




1.Python 用作计算器
现在,尝试一些简单的 Python 命令。启动解释器,等待主提示符(>>> )出现。python解释器像一个简单的计算器:你可以输入一个表达式,它将给出结果值。
1.1.1. 数字
运算符 +, -, * 和 / 可被用来执行算术运算;圆括号 (()) 可被用来进行运算分组。 例如:

除法运算 (/) 总是返回浮点数。 如果要做 floor division 得到一个整数结果你可以使用 // 运算符;要计算余数你可以使用 %:

Python 用 ** 运算符计算乘方 :

等号(=)用于给变量赋值。

如果变量未定义(即,未赋值),使用该变量会提示错误:

Python 全面支持浮点数;混合类型运算数的运算会把整数转换为浮点数:

交互模式下,上次输出的表达式会赋给变量 _。把 Python 当作计算器时,用该变量实现下一步计算更简单,例如:

最好把该变量当作只读类型。不要为它显式赋值,否则会创建一个同名独立局部变量,该变量会用它的魔法行为屏蔽内置变量。
除了 int 和 float,Python 还支持其他数字类型,例如 Decimal 或 Fraction。Python 还内置支持 复数,后缀 j 或 J 用于表示虚数(例如 3+5j )。
1.1.2. 文本
除了数字 Python 还可以操作文本(由 str 类型表示,称为“字符串”)。 这包括字符 "!", 单词 "rabbit", 名称 "Paris", 句子 "Got your back." 等等. "Yay! :)"。 它们可以用成对的单引号 ('...') 或双引号 ("...") 来标示,结果完全相同 。

要标示引号本身,我们需要对它进行“转义”,即在前面加一个 \。 或者,我们也可以使用不同类型的引号:

在 Python shell 中,字符串定义和输出字符串看起来可能不同。 print() 函数会略去标示用的引号,并打印经过转义的特殊字符,产生更为易读的输出:

如果不希望前置 \ 的字符转义成特殊字符,可以使用 原始字符串,在引号前添加 r 即可:

原始字符串还有一个微妙的限制:一个原始字符串不能以奇数个 \ 字符结束;
字符串字面值可以跨越多行。 一种做法是使用三重引号: """...""" 或 '''...'''。 行结束符会自动包括在字符串中,但可以通过在行尾添加 \ 来避免此行为。 在下面的例子中,开头的换行符将不会被包括:

字符串可以用 + 合并(粘到一起),也可以用 * 重复:

相邻的两个或多个 字符串字面值 (引号标注的字符)会自动合并:

拼接分隔开的长字符串时,这个功能特别实用:

这项功能只能用于两个字面值,不能用于变量或表达式:

合并多个变量,或合并变量与字面值,可以用 +号:

字符串支持 索引 (下标访问),第一个字符的索引是 0。单字符没有专用的类型,就是长度为一的字符串:

索引还支持负数,用负数索引时,从右边开始计数:

注意,-0 和 0 一样,因此,负数索引从 -1 开始。
除了索引操作,还支持 切片。 索引用来获取单个字符,而 切片 允许你获取子字符串:

切片索引的默认值很有用;省略开始索引时,默认值为 0,省略结束索引时,默认为到字符串的结尾:

注意,输出结果包含切片开始,但不包含切片结束。因此,s[:i] + s[i:] 总是等于 s:

还可以这样理解切片,索引指向的是字符 之间 ,第一个字符的左侧标为 0,最后一个字符的右侧标为 n ,n 是字符串长度。例如:

第一行数字是字符串中索引 0...6 的位置,第二行数字是对应的负数索引位置。i 到 j 的切片由 i 和 j 之间所有对应的字符组成。
对于使用非负索引的切片,如果两个索引都不越界,切片长度就是起止索引之差。例如, word[1:3] 的长度是 2。
索引越界会报错:

但是,切片会自动处理越界索引:

Python 字符串不能修改,是 immutable 的。因此,为字符串中某个索引位置赋值会报错:

要生成不同的字符串,应新建一个字符串:

内置函数 len() 返回字符串的长度:

1.1.3. 列表
Python 支持多种 复合 数据类型,可将不同值组合在一起。最常用的 列表 ,是用方括号标注,逗号分隔的一组值。列表 可以包含不同类型的元素,但一般情况下,各个元素的类型相同:

和字符串(及其他内置 sequence 类型)一样,列表也支持索引和切片:

列表还支持合并操作:

与 immutable 字符串不同, 列表是 mutable 类型,其内容可以改变:

你也可以在通过使用 list.append() 方法,在列表末尾添加新条目(我们将在后面介绍更多相关的方法):

Python 中的简单赋值绝不会复制数据。 当你将一个列表赋值给一个变量时,该变量将引用 现有的列表。你通过一个变量对列表所做的任何更改都会被引用它的所有其他变量看到。:

切片操作返回包含请求元素的新列表。以下切片操作会返回列表的 浅拷贝:

为切片赋值可以改变列表大小,甚至清空整个列表:

内置函数 len() 也支持列表:

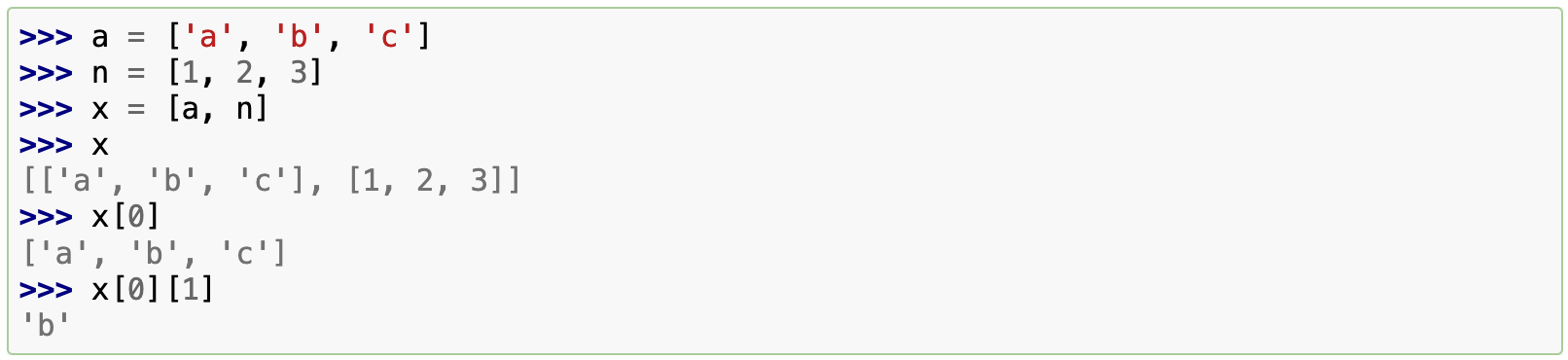
还可以嵌套列表(创建包含其他列表的列表),例如:
2.控制流工具
2.1. if 语句
最让人耳熟能详的语句应当是 if 语句:

可有零个或多个 elif 部分,else 部分也是可选的。关键字 'elif' 是 'else if' 的缩写,用于避免过多的缩进。if ... elif ... elif ... 序列可以当作其它语言中 switch 或 case 语句的替代品。
如果是把一个值与多个常量进行比较,或者检查特定类型或属性,match 语句更有用。详见 match 语句。
2.2. for 语句
Python 的 for 语句与 C 或 Pascal 中的不同。Python 的 for 语句不迭代算术递增数值(如 Pascal),或是给予用户定义迭代步骤和结束条件的能力(如 C),而是在列表或字符串等任意序列的元素上迭代,按它们在序列中出现的顺序。(也就是说:Python 的 for 循环是“把序列里的东西一个个拿出来用,而C 可以一步步算到另一个数字) 例如:
C:

Python:(可以通过range()模仿上述C的行为)

很难正确地在迭代多项集的同时修改多项集的内容。更简单的方法是迭代多项集的副本或者创建新的多项集:

2.3. range() 函数
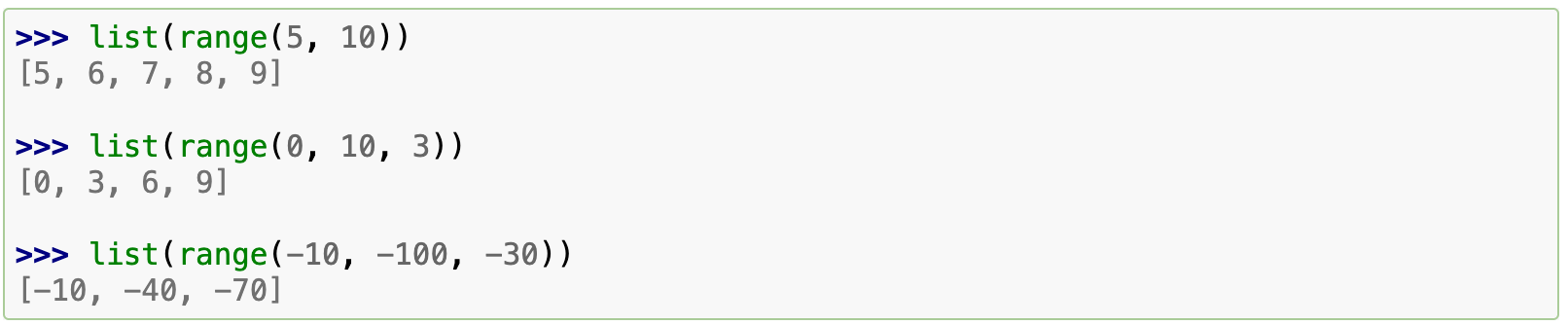
内置函数 range() 用于生成等差数列:

生成的序列绝不会包括给定的终止值;range(10) 生成 10 个值——长度为 10 的序列的所有合法索引。range 可以不从 0 开始,且可以按给定的步长递增(即使是负数步长):
要按索引迭代序列,可以组合使用 range() 和 len():

不过大多数情况下 enumerate() 函数很方便,详见 循环的技巧。
如果直接打印一个 range 会发生意想不到的事情:

range() 返回的对象在很多方面和列表的行为一样,但其实它和列表不一样。该对象只有在被迭代时才一个一个地返回所期望的列表项,并没有真正生成过一个含有全部项的列表,从而节省了空间。
这种对象称为可迭代对象 iterable,适合作为需要获取一系列值的函数或程序构件的参数。for 语句就是这样的程序构件;以可迭代对象作为参数的函数例如 sum():

2.4. break 和 continue 语句
break 语句将跳出最近的一层 for 或 while 循环:

continue 语句将继续执行循环的下一次迭代:

2.5. 循环的 else 子句
在 for 或 while 循环中 break 语句可能对应一个 else 子句。 如果循环在未执行 break 的情况下结束,else 子句将会执行。
在 for 循环中,else 子句会在循环结束其他最后一次迭代之后,即未执行 break 的情况下被执行。
在 while 循环中,它会在循环条件变为假值后执行。
在这两类循环中,当在循环被 break 终结时 else 子句 不会 被执行。 当然,其他提前结束循环的方式,如 return 或是引发异常,也会跳过 else 子句的执行。
下面的搜索质数的 for 循环就是一个例子:

(对,这是正确的代码。 仔细看:其中 else 子句属于 for 循环,而 不属于 if 语句。)
分析 else 子句的一种方式是想象它对应于循环内的 if。 当循环执行时,它将运行一系列的 if/if/if/else。 if 位于循环内部,会出现多次。 当出现条件为真的情况时,将发生 break。 如果条件一直不为真,则循环外的 else 子句将被执行。
当配合循环使用时,else 子句更像是 try 语句的 else 子句而不像 if 语句的相应子句:一个 try 语句的 else 子句会在未发生异常时运行,而一个循环的 else 子句会在未发生 break 时运行。 有关 try 语句和异常的详情,请参阅 异常的处理。
2.6. pass 语句
pass 语句不执行任何动作。语法上需要一个语句,但程序毋需执行任何动作时,可以使用该语句。例如:

这常用于创建一个最小的类:

pass 还可用作函数或条件语句体的占位符,让你保持在更抽象的层次进行思考。pass 会被默默地忽略:

2.7. match 语句
match 语句接受一个表达式并把它的值与一个或多个 case 块给出的一系列模式进行比较。这表面上像 C、Java 或 JavaScript(以及许多其他程序设计语言)中的 switch 语句,但其实它更像 Rust 或 Haskell 中的模式匹配。只有第一个匹配的模式会被执行,并且它还可以提取值的组成部分(序列的元素或对象的属性)赋给变量。
最简单的形式是将一个主语值与一个或多个字面值进行比较:

注意最后一个代码块:“变量名” _ 被作为 通配符 并必定会匹配成功。如果没有 case 匹配成功,则不会执行任何分支。
你可以用 | (“或”)将多个字面值组合到一个模式中:

形如解包赋值的模式可被用于绑定变量:

请仔细学习此代码!第一个模式有两个字面值,可视为前述字面值模式的扩展。接下来的两个模式结合了一个字面值和一个变量,变量 绑定 了来自主语(point)的一个值。第四个模式捕获了两个值,使其在概念上与解包赋值 (x, y) = point 类似。
如果用类组织数据,可以用“类名后接一个参数列表”这种很像构造器的形式,把属性捕获到变量里:

一些内置类(如 dataclass)为属性提供了一个顺序,此时,可以使用位置参数。自定义类可通过在类中设置特殊属性 __match_args__,为属性指定其在模式中对应的位置。若设为 ("x", "y"),则以下模式相互等价(且都把属性 y 绑定到变量 var):

建议这样来阅读一个模式——通过将其视为赋值语句等号左边的一种扩展形式,来理解各个变量被设为何值。match 语句只会为单一的名称(如上面的 var)赋值,而不会赋值给带点号的名称(如 foo.bar)、属性名(如上面的 x= 和 y=)和类名(是通过其后的 "(...)" 来识别的,如上面的 Point)。
模式可以任意嵌套。举例来说,如果我们有一个由 Point 组成的列表,且 Point 添加了 __match_args__ 时,我们可以这样来匹配它:

我们可以为模式添加 if 作为守卫子句。如果守卫子句的值为假,那么 match 会继续尝试匹配下一个 case 块。注意是先将值捕获,再对守卫子句求值:

该语句的一些其它关键特性:
-
与解包赋值类似,元组和列表模式具有完全相同的含义并且实际上都能匹配任意序列,区别是它们不能匹配迭代器或字符串。
-
序列模式支持扩展解包:
[x, y, *rest]和(x, y, *rest)和相应的解包赋值做的事是一样的。接在*后的名称也可以为_,所以(x, y, *_)匹配含至少两项的序列,而不必绑定剩余的项。 -
映射模式:
{"bandwidth": b, "latency": l}从字典中捕获"bandwidth"和"latency"的值。额外的键会被忽略,这一点与序列模式不同。**rest这样的解包也支持。(但**_将会是冗余的,故不允许使用。) -
使用
as关键字可以捕获子模式:
将把输入中的第二个元素捕获为
p2(只要输入是包含两个点的序列) -
大多数字面值是按相等性比较的,但是单例对象
True、False和None则是按 id 比较的。 -
模式可以使用具名常量。它们必须作为带点号的名称出现,以防止它们被解释为用于捕获的变量:

2.8.Lambda 表达式
lambda 关键字用于创建小巧的匿名函数。lambda a, b: a+b 函数返回两个参数的和。Lambda 函数可用于任何需要函数对象的地方。在语法上,匿名函数只能是单个表达式。在语义上,它只是常规函数定义的语法糖。与嵌套函数定义一样,lambda 函数可以引用包含作用域中的变量:
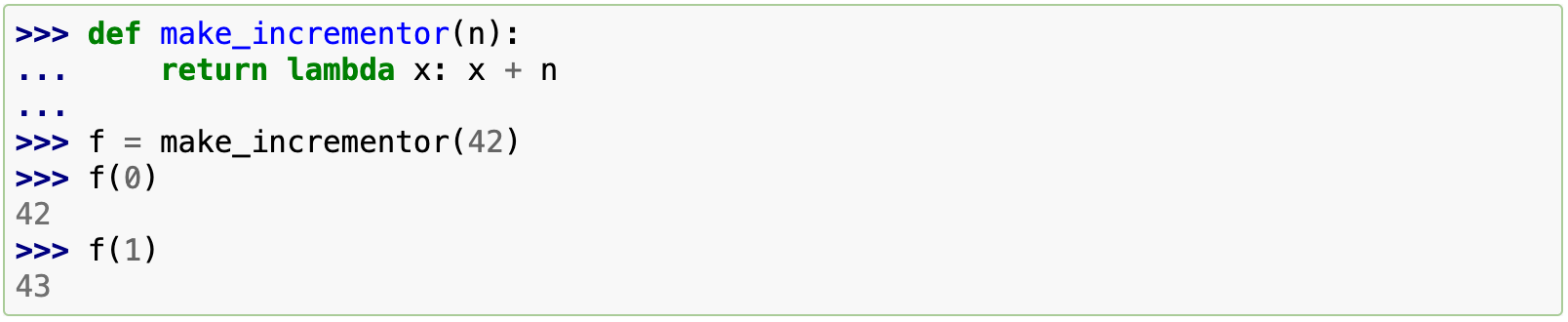 上面的例子使用 lambda 表达式返回函数。 另一种用法是传入一个小函数作为参数。 例如,list.sort() 接受一个排序键函数 key,它可以是一个 lambda 函数:
上面的例子使用 lambda 表达式返回函数。 另一种用法是传入一个小函数作为参数。 例如,list.sort() 接受一个排序键函数 key,它可以是一个 lambda 函数:


















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









