







目录
第一章 爬虫基础
1.1 HTTP基本原理
1 URI 统一资源标注符:
- URL 统一资源定位符
- URN 统一资源名称
目前互联网中,URL用的非常少,几乎所有的URI都是URL。
URL基本格式:
![]()
- scheme:协议,也叫protocol,常用的协议有http、https、ftp。
- username、password:用户名和密码。
- hostname:主机地址,可以是域名或IP地址。
- port:端口。
- path:路径。
- parameters:参数,现在用的很少,目前很多人会把该参数后面的query称为参数。
- query:查询。如果有多个查询,用&分开。
- fragment:片段。对资源描述部分的补充,可以理解为资源内部的书签。
2 HTTP和HTTPS
爬虫抓取的页面基于http或https协议:
- http,中文名为超文本传输协议,作用是把超文本数据从网络传输到本地浏览器。
- https,是以安全为目标的HTTP通道,也就是HTTP的安全版,在HTTP下加入SSL层。
SSL是https的安全基础,主要作用有以下两种:
- 建立一个信息安全通道,保证数据传输的安全性。
- 确认网站的只能是行。
3 HTTP请求过程
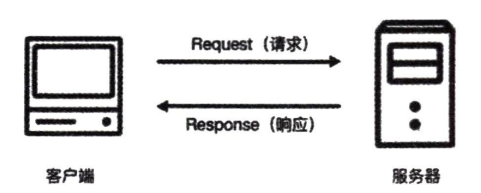
可通过chrome浏览器开发展模式下的Network监听组件(Network可以在访问当前请求的网页时,显示产生的所有网络请求和相应),具体操作如下:
打开chrome浏览器,访问百度,单机鼠标右键并选择“检查”菜单(或者直接按快捷键f12),即可打开浏览器的开发者工具。切换到Network面板,重新刷新网页,就可看到许多条目,其中一个条目就代表一次发送请求或接受响应的过程,如下图所示。
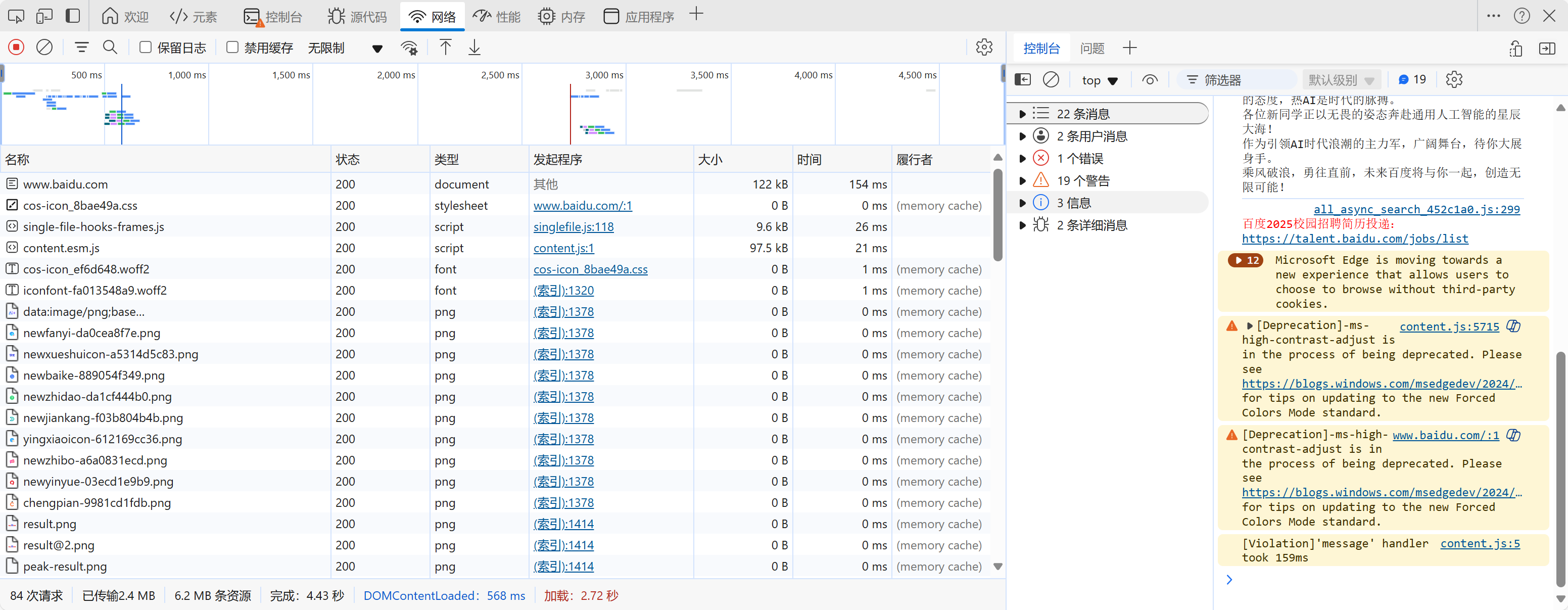
通过会包括以下内容:
- 第一列name/名称:请求的名称,一般会用URL的最后一部分作为名称。
- 第二列status/相应的状态码:200(正常)
- 第三列protocol/请求的协议类型:http/1.1表示http1.1版本,h2表示http2.0版本
- 第四列Type/请求的文档类型:document(访问的是HTML文档)
- 第五列initiator/请求源:用来标记请求是有哪个对象或进程发起的。
- 第六列size:从服务器下载的文件或请求的资源大小,如果资源是从缓存中取得的,则该列会显示from cache。
- 第七列time:从发起请求到和获取响应所花的总时间。
- 第八列waterfall:网络请求的可视化瀑布流。
点击其中一条目录,显示如下:
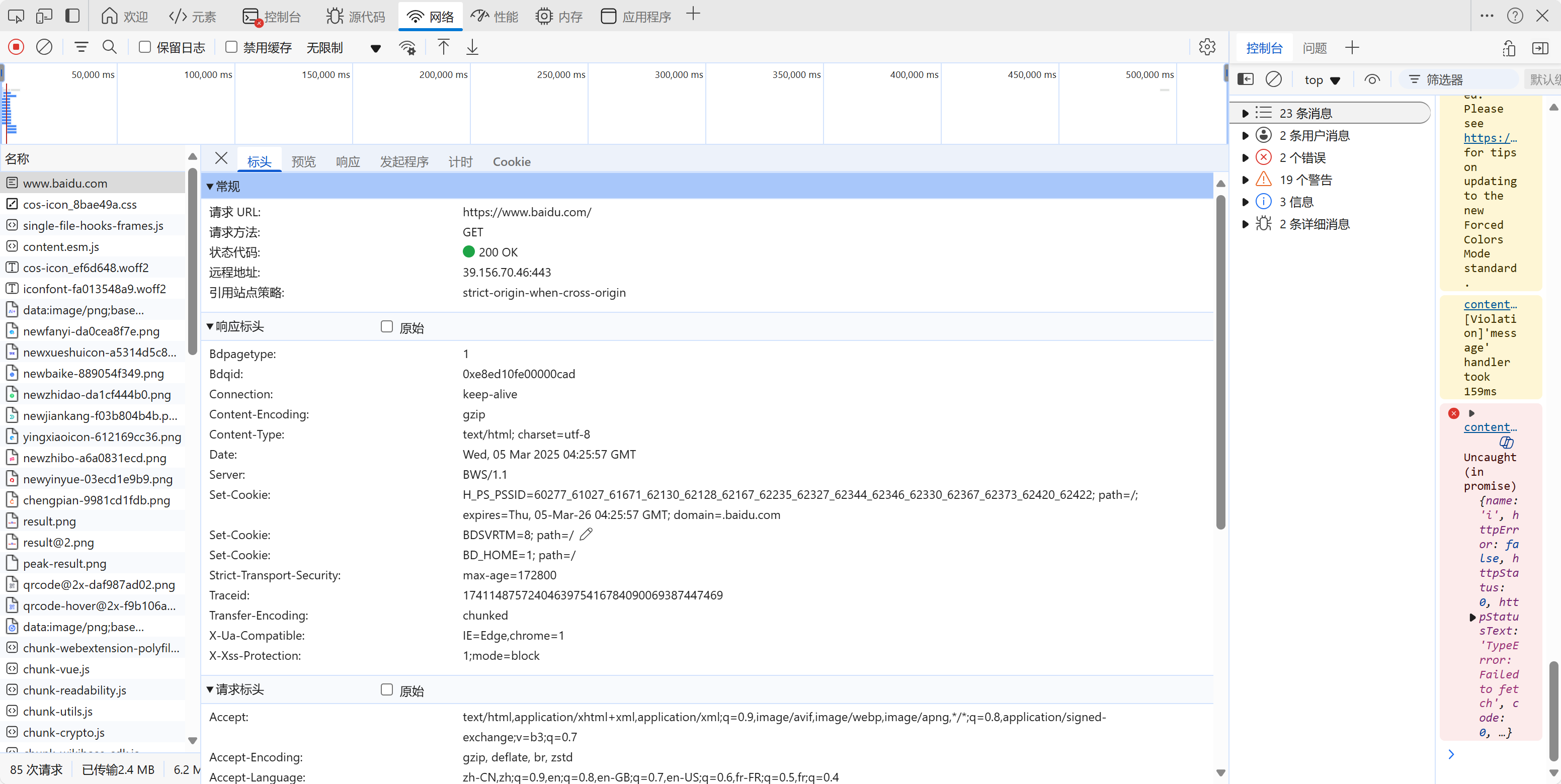
- general/常规
- response headers响应标头:包含服务器的类型、文档类型、日期
- request headers请求头:包含请求信息,如浏览器标识、cookie、host
4 请求
指从客户端发往服务器,分为四部分:
- 请求方法:用于标识请求客户端请求服务端的方式,包括get和post两种方法。get请求中的参数包含在URL中,数据可以在URL中看到;而post请求的URL不会包含这些数据,数据都是通过表单形式传输,而不会体现在请求体中。get请求提交的数据最多只有1024字节,post方式则没有限制。建议使用post请求,因为get请求的时候密码会暴露在url中。

- 请求的网址
- 请求头:用来说明服务器要使用的附加消息。


- 请求体:一般承载的是post请求中的表单数据,对于get请求,请求体为空。

5 响应
指由服务器返回给客户端,包括三个部分:
- 响应状态码:表示服务器的响应状态

- 响应头:包含服务器对请求的应答信息。

- 响应体:相应的正文数据都存在响应体中。爬虫时,主要通过响应体的得到网页的源代码、JSON数据,然后从中提取相应内容。
6 HTTP 2.0
http2.0内部实现了新的二进制分帧层:
- 二进制分帧层:在http1.x中,请求和响应都是用文本格式传输的,头部和实体之间也是用文本换行符分隔开的。http2.0将文本格式修改为了二进制格式,同时将请求和相应数据分割为更小的帧,并采用二进制编码。

- 多路复用:http2.0将http消息分解为互不依赖的帧,然后交错发送,最后再在另一端把他们重新组装起来,达到以下结果:


- 流控制:组织发送方向接收方发送大量数据的机制,以免超出后者的需求或处理能力。

- 服务端推送:http2.0新增的另一个强大的功能是服务器可以对一个客户端请求发送多个响应,除了最初请求的响应,服务器还可以向客户端推送额外资源,而无须客户端明确地请求。
1.2 Web 网页基础
1 网页组成
网页可以分为三大部分:HTML、CSS、JavaScript。
如果把网页比作一个人,那么HTML相当于骨架、Javascript相当于肌肉、CSS相当于皮肤。
- HTML:超文本标记语言,用来描述网页的语言。网页包括文字、段落p、按钮、图片img和视频video等各种复杂的元素,其基础框架就是HTML。这些标签之间常由布局标签div嵌套组合而成。(打开方式:右键→检查元素/f12→elements)
- CSS:层叠样式表,网页页面排版样式标准。

- JavaScript:js,脚本语言,用来提供一些交互和动画效果,如下载进度条、提示框、轮番图等。js通常也是以单独的文件形式加载的,后缀为js,在html中通过script标签即可引入。
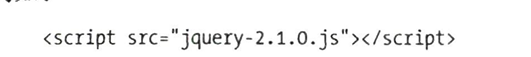
2 网页结构

- title:网页的标题
- body:网页正文
- div:定义网页中的区块
- head:网页标签的名字
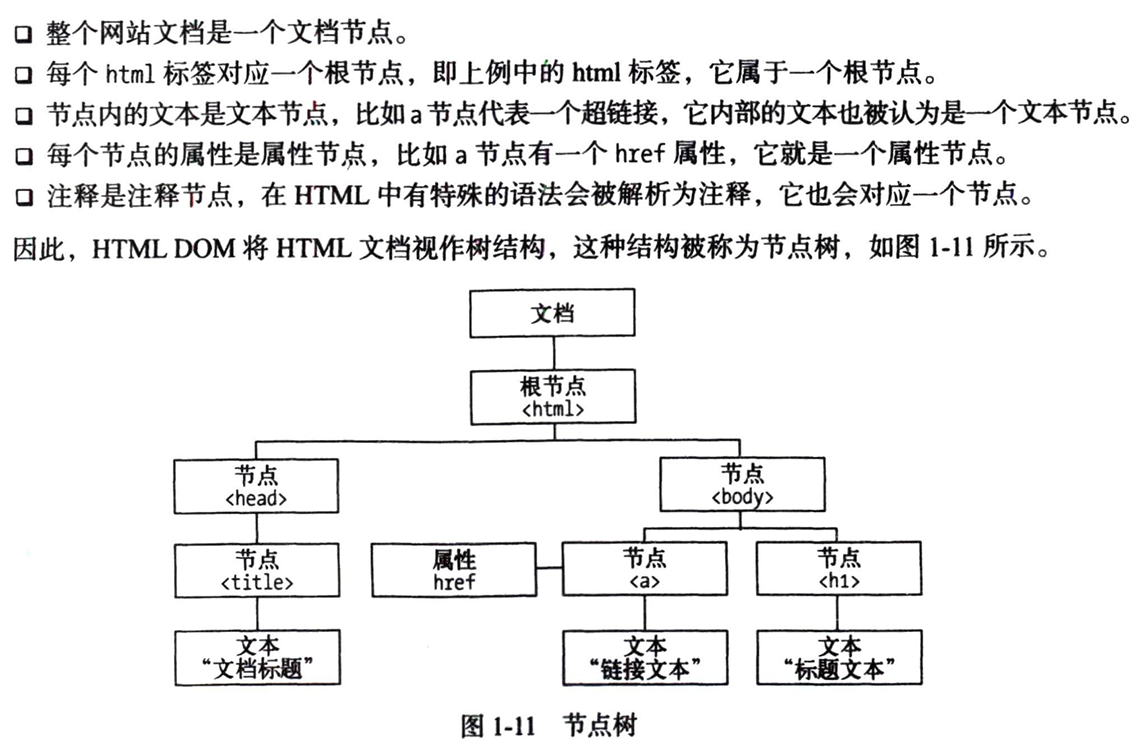
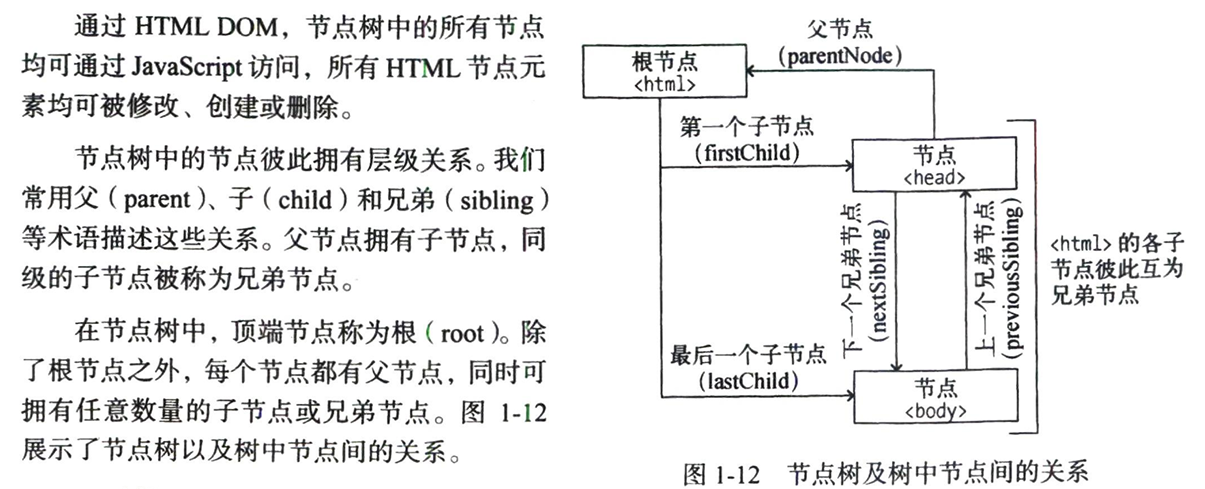
3 节点树及节点间的关系
在html中,所有标签定义的内容都是节点,这些节点构成一个html节点树,也叫html dom树。
4 选择器
css选择器会为不同的节点设置不同的样式规则。

操作方式:开发者工具→ctrl+f→左下角输入框


1.3 爬虫的基本原理
1 爬虫概述
简单点说,爬虫就是获取网页并提取和保存信息的自动化程序。
- 获取网页:等同于获取网页源代码。
- 提取信息:分析源代码,提取想要的数据。最通用的方法是正则表达式。

- 保存数据:可保存为txt或json文本,也可保存到mysql和mongobd数据库,也可保存至远程服务器,借助sftp进行操作。
- 自动化程序
2 能爬怎样的数据
html代码、json字符串、二进制数据(图片、视频、音频)等
3 JavaScript渲染的页面
当用urllib或requests抓取网页时,得到的源代码和浏览器中实际看到的不一样。
1.4 Session和Cookie
1 静态网页和动态网页
- 静态网页:有html代码编写的,文字、图片等内容均通过写好的html代码来指定。
- 动态网页:动态解析URL中参数的变化,关联数据库并动态呈现不同的页面内容。
2 无状态http

session在服务端,也就是网站的服务器,用来保存用户的session信息
cookie在客户端,在浏览器端,有了cookie,浏览器在下次访问相同网页时就会自动附带上他,并发送给服务器,服务器通过识别cookie鉴定出是哪个用户在访问,判断用户是否处于登录状态,并返回对应的响应。
因此,在爬虫中,一般会直接将登录成功后获取的cookie放在请求头里面直接请求,而不重新模拟登录。
3 Session
会话,指有始有终的一系列动作、消息,用来存储特定用户的sessio所需的属性及配置信息。
4 cookie
为了鉴别用户身份、进行session跟踪而存储在用户本地终端上的数据。
- session维持

- 属性结构

- 会话cookie和持久cookie:会话cookie就是把cookie放在浏览器内存里,关闭浏览器后,cookie即失效;持久cookie会把cookie保存到客户端的硬盘中,下次还可以继续使用。(由字段Max-Age或Expores决定)
- 关闭浏览器,session不会被删除,需要设置失效时间。
1.5 代理的基本原理
借助某种方式伪装我们的ip,让服务器识别不出来,从而不会限制请求次数。
1 基本原理


2 代理的作用

3 爬虫代理
使用代理隐藏真实的ip,请服务器误认为是代理服务器在请求自己。
4 代理分类


5 常见代理设置

1.6 多线程和多进程的基本原理
在编写爬虫程序时,为例提高爬虫效率,我们呢可能会同时运行多个爬虫任务,其中同样设计多进程和多线程。
1 多线程的含义


2 并发和并行

3 多线程适用场景

4 多进程的含义

5 python中的多线程和多进程

来源:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









