










faster-rcnn pytorch1.0.0版本源码地址:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
参考:https://blog.youkuaiyun.com/qq_38497266/article/details/97396096
https://blog.youkuaiyun.com/woshicao11/article/details/82055449
https://blog.youkuaiyun.com/u014696804/article/details/103817245
https://blog.youkuaiyun.com/zxmyoung/article/details/106771428
一、环境配置:
1.1、 系统环境:Ubuntu 16.04:安装教程:https://jingyan.baidu.com/article/3c48dd348bc005e10be358eb.html
1.2、Python3.6,安装Anaconda,https://blog.youkuaiyun.com/lwplwf/article/details/79162470
1.3、硬盘驱动+CUDA 10.0安装:https://blog.youkuaiyun.com/baobei0112/article/details/79755803
1.4 Pytorch 1.3安装
二、用voc2007标准数据集训练模型
1、训练模型
2.1.1 到github下载源码:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0,放到指定的目录下
2.1.2 在代码所在目录打开终端,手动创建data文件夹或者用命令行创建:mkdir data
2.1.3 安装模型所需依赖(第三方包),命令行输入即可自动安装所需依赖:pip install -r requirements.txt
2.1.4 进入lib目录下,编译NMS, ROI_Pooling, ROI_Align和ROI_Crop模块,命令行输入:
编译CUDA依赖环境
cd lib
python setup.py build develop
2.1.5 下载voc2007数据集,下载链接:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
,下载后解压,解压后的目录结构如下:
在项目路径data下创建VOCdevkit文件夹,将刚才下载解压后的voc2007文件夹复制到./data/VOCdevkit目录下 ,目录结构如下:

2.1.6 下载预训练好的vgg16模型,并在data数据集上面新建一个pretrained_model文件夹,将与训练模型放到里面(resnet101:dropbox vgg16:dropbox)
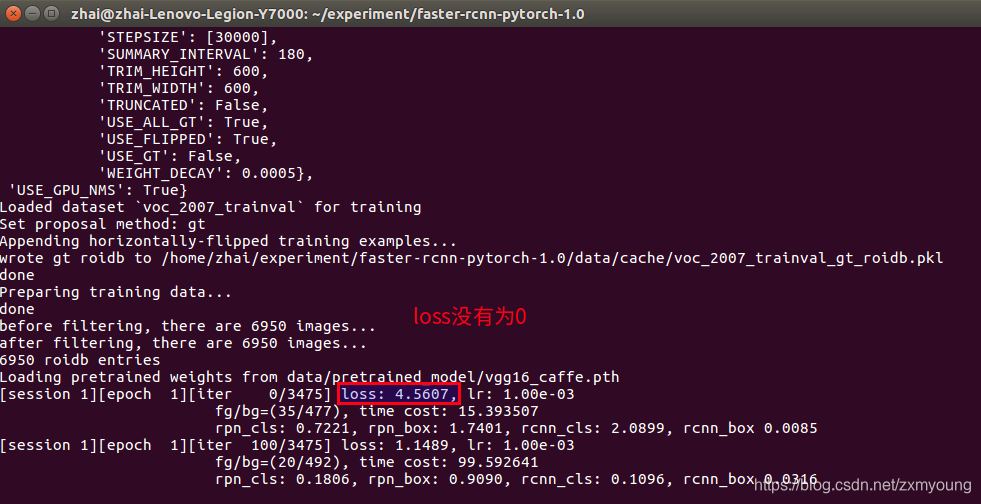
2.1.7 训练模型:基于vgg16模型训练网络,在项目根目录下输入下列命令就会开始训练模型,python trainval_net.py表示执行trainval_net.py代码进行训练,后面的都是指定的参数,若不指定,将会选择默认选项
CUDA_VISIBLE_DEVICES=$GPU_ID python trainval_net.py \
--dataset pascal_voc --net vgg16 \
--bs 1 --nw 4 \
--lr 0.00001 \
--cuda最终在控制台输入以下命令开始训练模型,
python trainval_net.py --dataset pascal_voc --net vgg16 --bs 1 --nw 4 --cuda其中
“CUDA_VISIBLE_DEVICES”指代了gpu的id,–dataset”指代你跑得数据集名称,我们就以pascal-voc为例;“–net”指代你的backbone网络是啥,我们以vgg16为例;"–bs"指的batch size;“–nw”指的是worker number;"--lr"指代学习率,“–cuda”指的是使用gpu。
–net vgg16:用vgg16作为特征提取网络,可选res101
–epochs 20:20个epoch,每个epoch都过一遍全部的训练图。
–bs 1:batch_size=1
–nw 4:num_works=4,4线程进行读取,我的显卡显存是11G,如果显存小的话就设为1
–lr 1e-4: 初始学习率是0.0001;可选参数
–lr_decay_step 8: 每几个epoch学习率衰减一次(默认衰减一次0.1,通过decay_gamma可调);可选参数
–use_tfb: 使用tensorboardX实现记录和可视化,不用就不写;可选参数
–mGPUs: 多GPU训练,不用就不写该命令;可选参数
–cuda:使用cuda;
训练过程中模型默认保存地址为./model/vgg16/pascal_voc路径下(trainval_net.py中变量sava_name的值为模型保存的路径)。
2、测试训练好的模型
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 20 --checkpoint 1291 --cuda参数的意义:
@@可以根据生成训练得到模型的名称给checksession、checkepoch、checkpoint赋值。
注意,这里的三个check参数,是定义了训好的检测模型名称,我训好的名称为faster_rcnn_1_20_1291,代表了checksession = 1,checkepoch = 20, checkpoint = 1291,这样才可以读到模型“faster_rcnn_1_20_1291”。训练中,我设置的epoch为20,但训练到第3批就停了,所以checkepoch选择3,也就是选择最后那轮训好的模型,理论上应该是效果最好的。当然着也得看loss。
3、测试demo
python demo.py --net vgg16 --checksession 1 --checkepoch 20 --checkpoint 1291 --cuda --load_dir modelsdemo测试会检测images路径下的图片,images从官网下载后的图片有12个,但其中×××_det.jpg的8张都是作者在测试的结果,因此需要删除这8张再进行测试。
参数的意义:
–dataset pascal_voc:用pascal数据集
–net res101:用res101作为特征提取网络,可选vgg16
–cfg cfgs/res101.yml:加载res101的配置
–load_dir models --checksession 1 --checkepoch 28 --checkpoint 2813:这四个参数共同决定读取models/文件夹中训练好的faster_rcnn_1_28_2813.pth权重文件
–image_dir path/to/your/image:需要批量检测的图像文件路径
–bs 1:batch_size=1
–cuda:使用cuda
测试好的图片输出在与images相同的文件夹内,其命名为原图名字+_det
三、用自己数据集训练模型
3.1 训练
3.1.1 准备数据集:
制作和voc2007格式相同的数据集,将原来data\VOCdevkit\VOC2007目录下的所有内容删除,将自己做好的数据放进data\VOCdevkit\VOC2007目录下,目录结构为

其中Annotations为标注文件夹,有若干.xml文件。每一个图片都对应一个.xml文件,其中存储的是该图片的名称,长宽,目标框(GroundTrues)的左上右下坐标,目标框的类别名称;
ImagesSet文件夹下的Main里,保存了用来训练和测试图片的名称,以txt文本存储,每行一个图片名称;
JPEGImage文件夹保存了所有原图片。
数据集制作软件和具体方法参考:https://blog.youkuaiyun.com/qq_38497266/article/details/95169227
如果想要更改xml文件中属性值,比如想把xml文件中类别名称改变,或把图片名称、路径等值改变,参考:https://github.com/XinZhangNLPR/Xml-document-modify.git
3.1.2替换原有的VOC2007数据集:
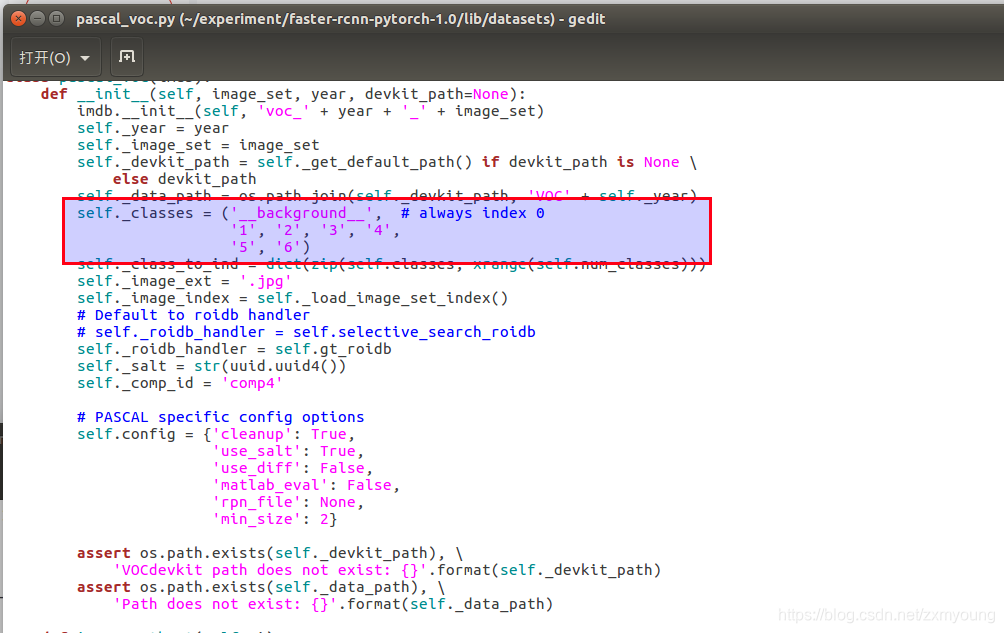
删除之前训练VOC2007数据集产生的模型文件(./models文件夹下的所有文件和./data/cache文件夹)和测试产生的结果文件(./output文件夹下的所有文件和./data/VOCdevkit文件夹下的annotations_cache与results),进入faster-rcnn.pytorch/lib/datasets/pascal_voc.py文件下,注释掉原来模型识别的类别,比如要检测猫和狗,则添加自己定义的需要识别类别名cat和dog(类名和前面xml文件中目标的name属性应该是一样的)
3.1.3 训练,
到此为止就可以开始训练了,训练命令行不用变,依旧为:
python trainval_net.py --dataset pascal_voc --net vgg16 --bs 4 --nw 4 --cuda换骨干网络res101
python trainval_net.py --dataset pascal_voc --net res101 --bs 4 --nw 4 --cuda
若换骨干网络res50,要在./lib/model/faster_rcnn/resnet.py改动
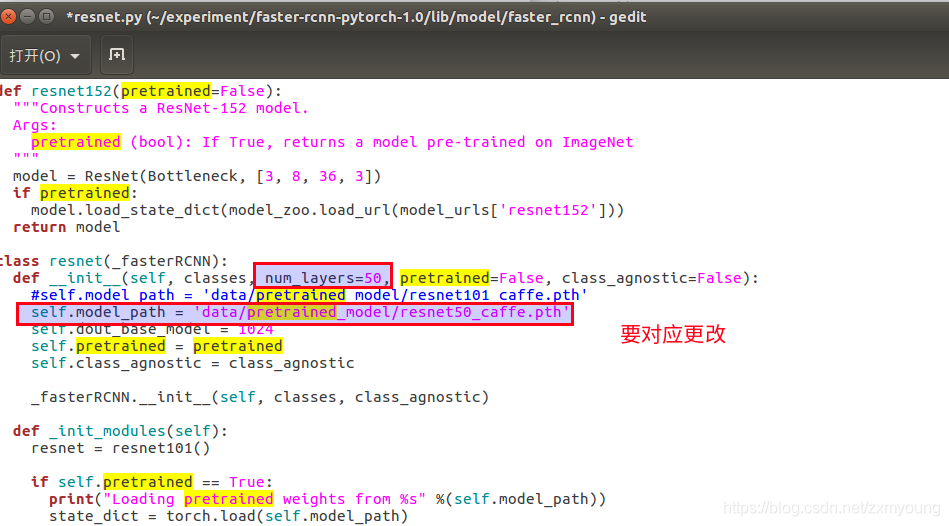
问题:ImportError: cannot import name '_mask'
解决方法:参考https://github.com/cocodataset/cocoapi/issues/59#issuecomment-469859646中的讨论
1.##下载cocoapi代码
git clone https://github.com/cocodataset/cocoapi.git
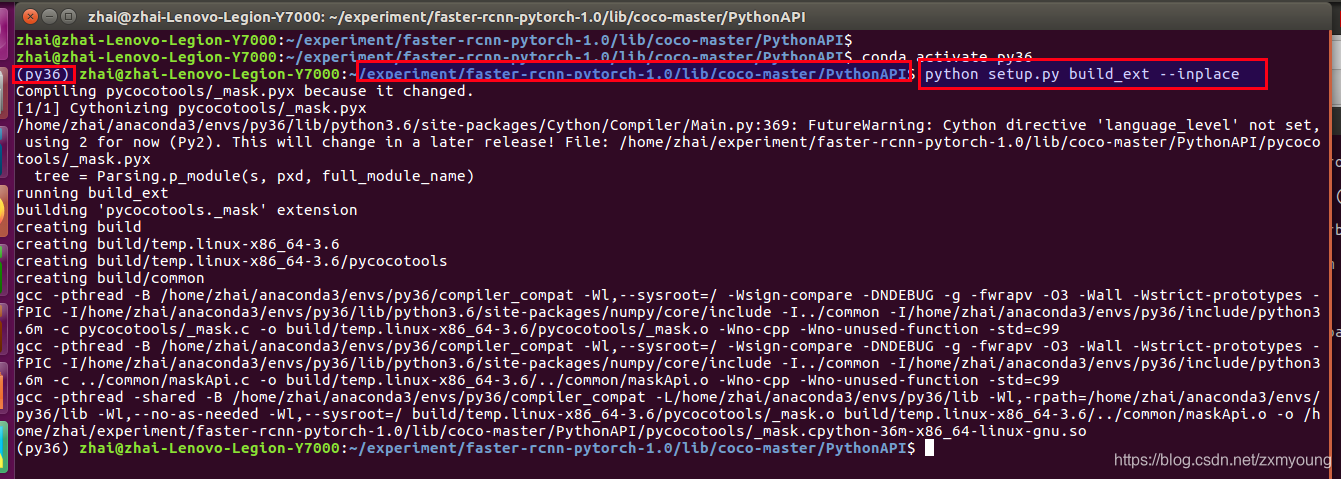
2.##单独编译PythonAPI
cd PythonAPI
python setup.py build_ext --inplace
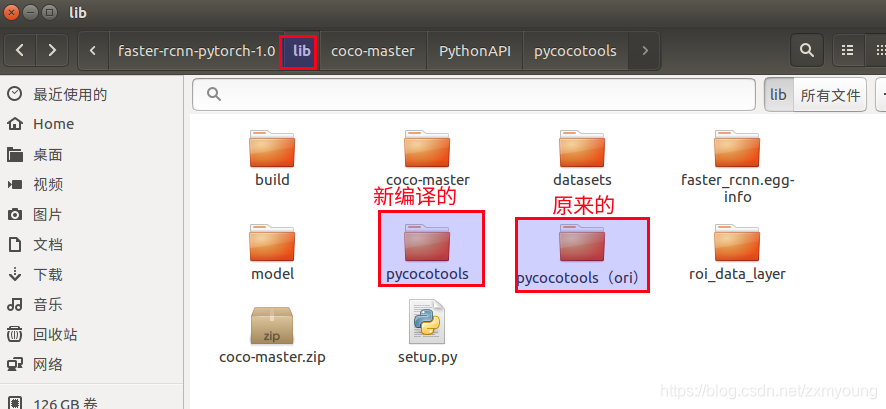
3.##删除faster-rcnn.pytorch/lib/下的pycocotools,将编译后的pycocotools文件夹复制到faster-rcnn.pytorch/lib/下
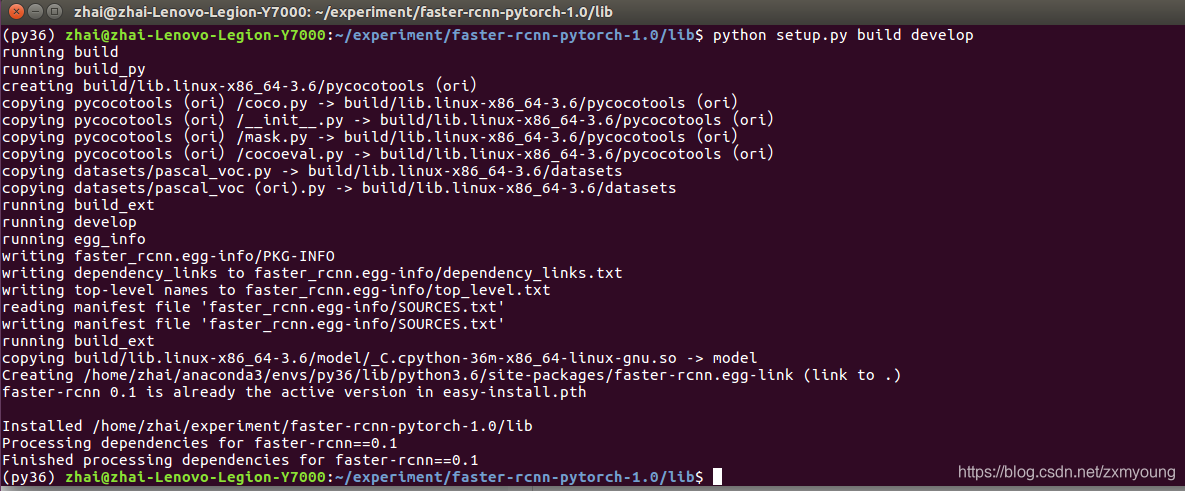
4.##现在可以在faster-rcnn中按原来的方法编译了
cd lib
python setup.py build develop
执行训练命令
问题
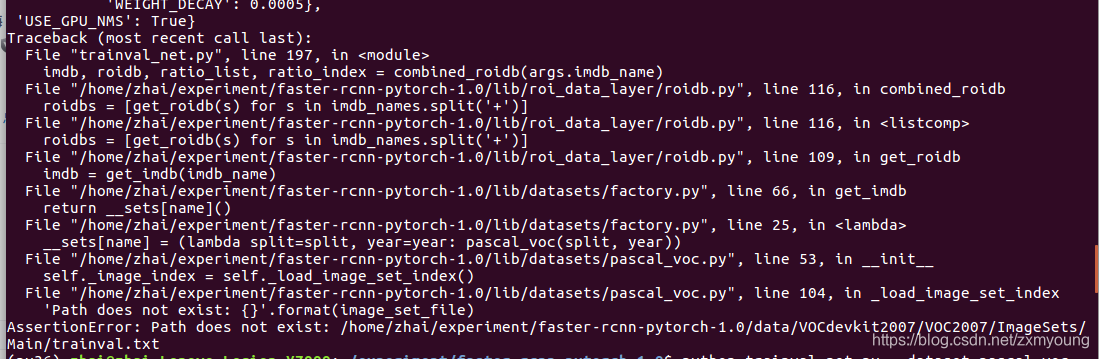
AssertionError: Path does not exist: /home/zhai/experiment/faster-rcnn-pytorch-1.0/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt
执行训练命令
问题
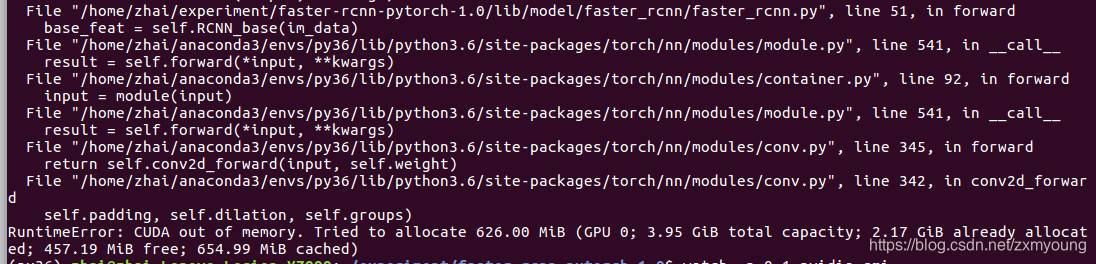
RuntimeError: CUDA out of memory. Tried to allocate 626.00 MiB (GPU 0; 3.95 GiB total capacity; 2.17 GiB already allocated; 457.19 MiB free; 654.99 MiB cached)
解决方法
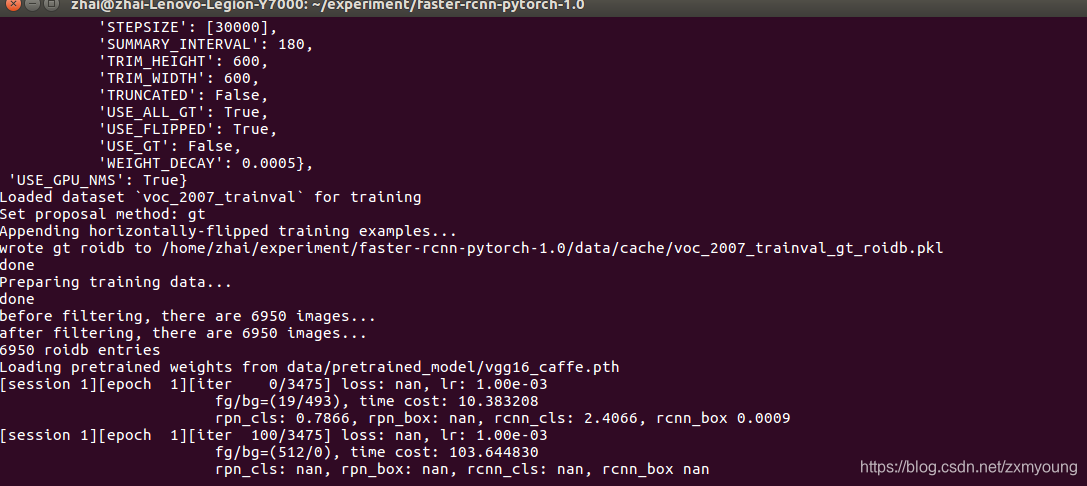
bs从4降为2
python trainval_net.py --dataset pascal_voc --net vgg16 --bs 2 --nw 4 --cuda成功
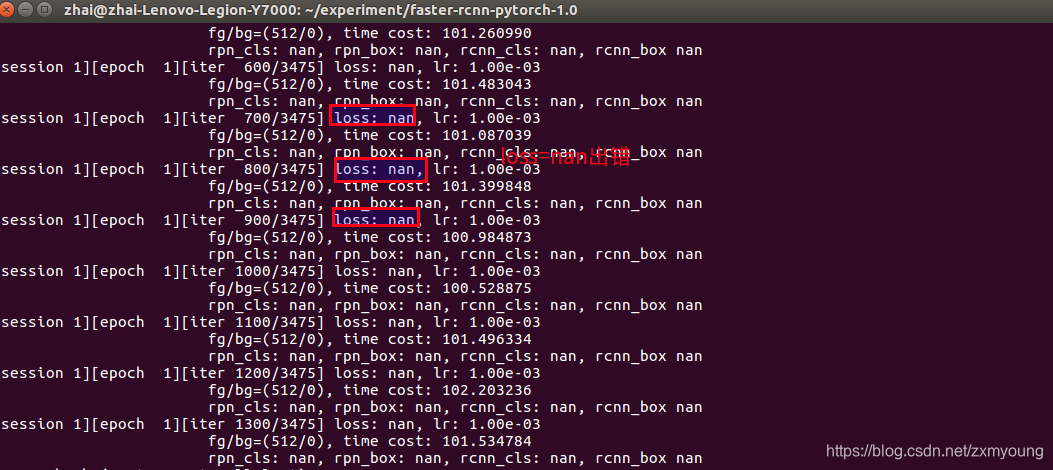
问题:参考:https://www.pythonheidong.com/blog/article/368496/
https://github.com/jwyang/faster-rcnn.pytorch/issues/75
https://blog.youkuaiyun.com/slq1023/article/details/90147042
训练过程中出现
[session 1][epoch 1][iter 1200/3475] loss: nan, lr: 1.00e-03
fg/bg=(512/0), time cost: 102.203236
rpn_cls: nan, rpn_box: nan, rcnn_cls: nan, rcnn_box nan
[session 1][epoch 1][iter 1300/3475] loss: nan, lr: 1.00e-03
fg/bg=(512/0), time cost: 101.534784
rpn_cls: nan,
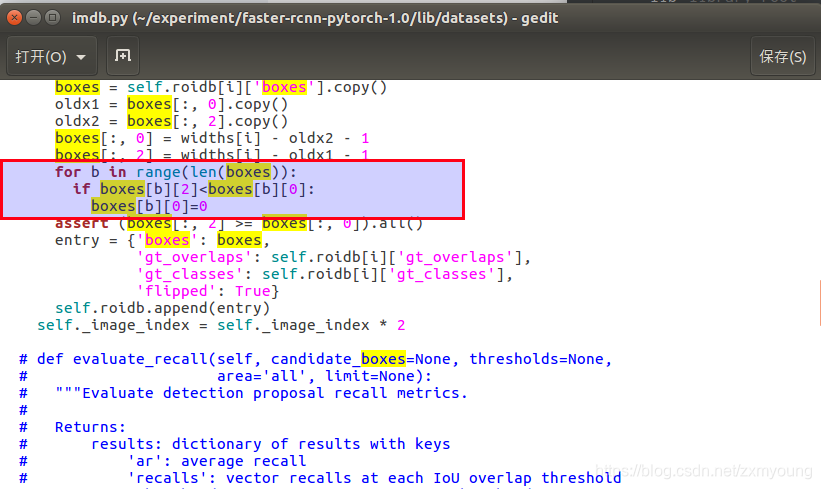
解决方法
lib/datasets/imdb.py修改如下
def append_flipped_images(self):
num_images = self.num_images
widths = self._get_widths()
for i in range(num_images):
boxes = self.roidb[i]['boxes'].copy()
oldx1 = boxes[:, 0].copy()
oldx2 = boxes[:, 2].copy()
boxes[:, 0] = widths[i] - oldx2 - 1
boxes[:, 2] = widths[i] - oldx1 - 1
for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
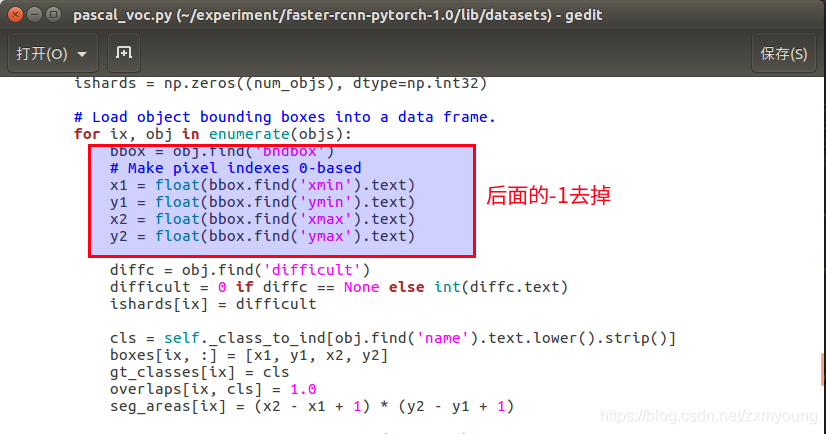
lib/datasets/pascal_voc.py
# Load object bounding boxes into a data frame.
for ix, obj in enumerate(objs):
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
x1 = float(bbox.find('xmin').text)
y1 = float(bbox.find('ymin').text)
x2 = float(bbox.find('xmax').text)
y2 = float(bbox.find('ymax').text)
执行训练命令
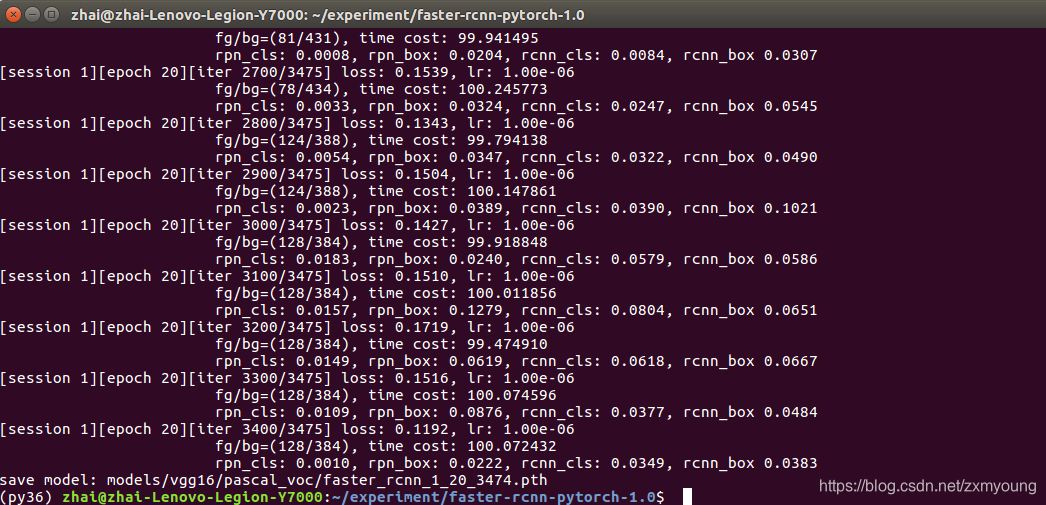
上面是VGG16骨干结果
下面展示Resnet101骨干结果
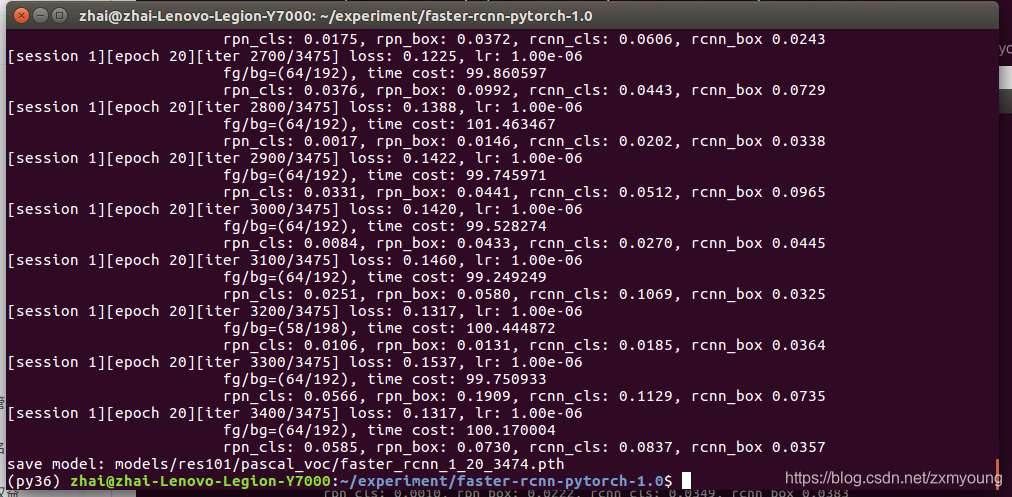
下面展示Resnet101,adam结果
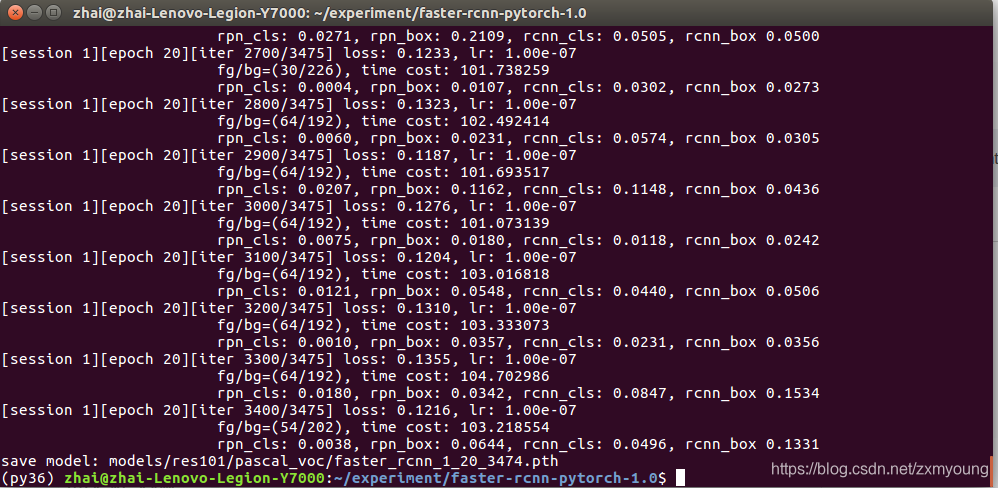
3.2 测试模型精度mAP+demo可视化检测结果、
3.2.1 测试模型精度
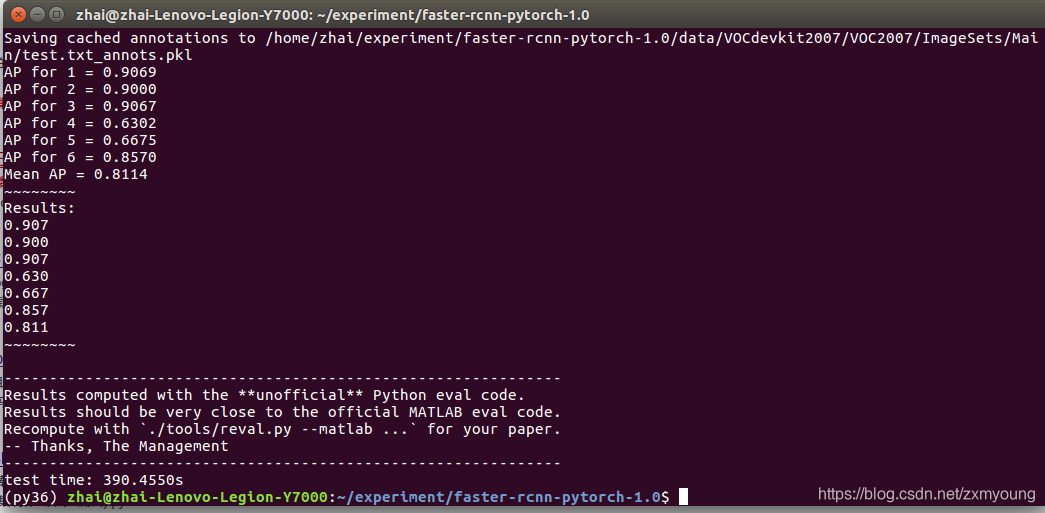
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 20 --checkpoint 3474 --cuda
@@可以根据生成训练得到模型的名称给checksession、checkepoch、checkpoint赋值。
注意,这里的三个check参数,是定义了训好的检测模型名称,我训好的名称为faster_rcnn_1_20_3474,代表了checksession = 1,checkepoch = 20, checkpoint = 3474,这样才可以读到模型“faster_rcnn_1_20_3474”。训练中,我设置的epoch为20,但训练到第3批就停了,所以checkepoch选择3,也就是选择最后那轮训好的模型,理论上应该是效果最好的。当然着也得看loss。
VGG16骨干网路的结果:
Resnet骨干网路的结果:
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 20 --checkpoint 3474 --cuda
待放图???????
测试结果默认保存在./output/vgg16/voc_2007_test目录下
3.2.2 demo自己的模型检测结果如何,并进行可视化
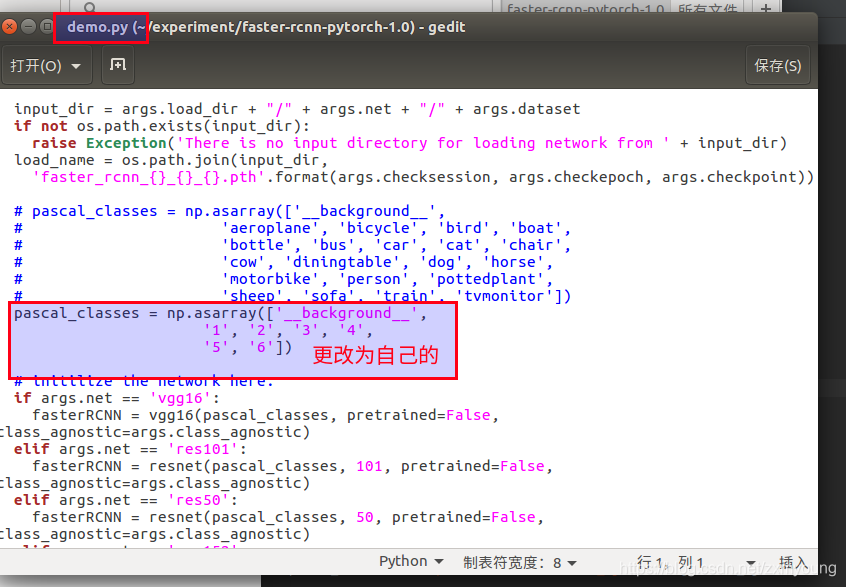
注意demo文件中也需要修改模型要识别的类名
修改完demo后就可以正常的测demo了,测demo的命令类似于:
python demo.py --net vgg16 --checksession 1 --checkepoch 20 --checkpoint 3474 --cuda --load_dir models但此处要注意看你训练好的模型文件中的checkpoint是否为3474,否则修改为模型文件中的数值。
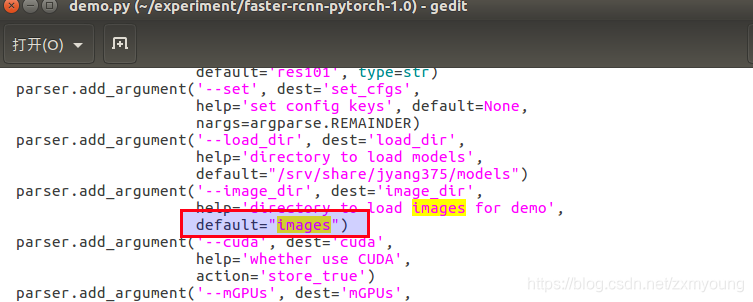
注意:默认检测的图片文件是images,可以更改
执行后
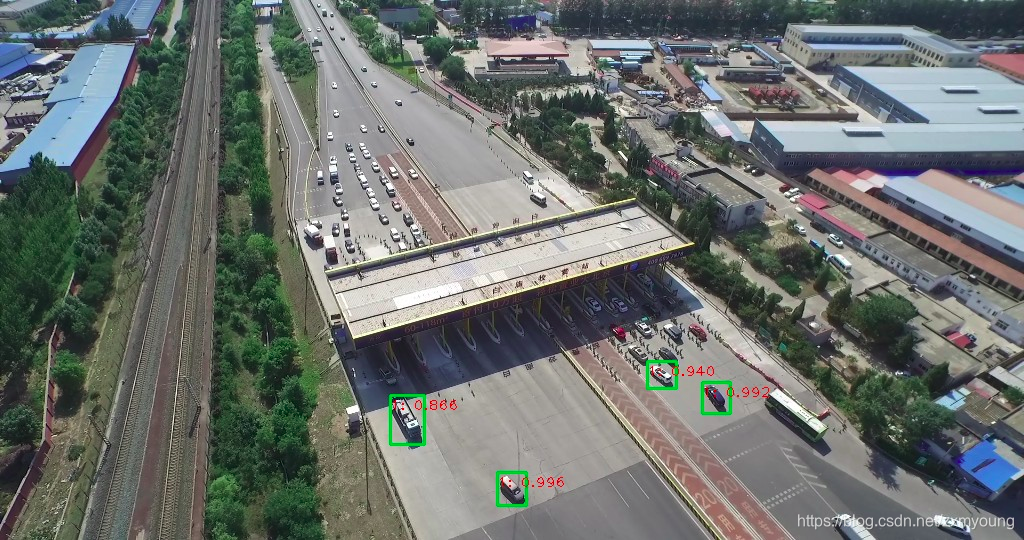
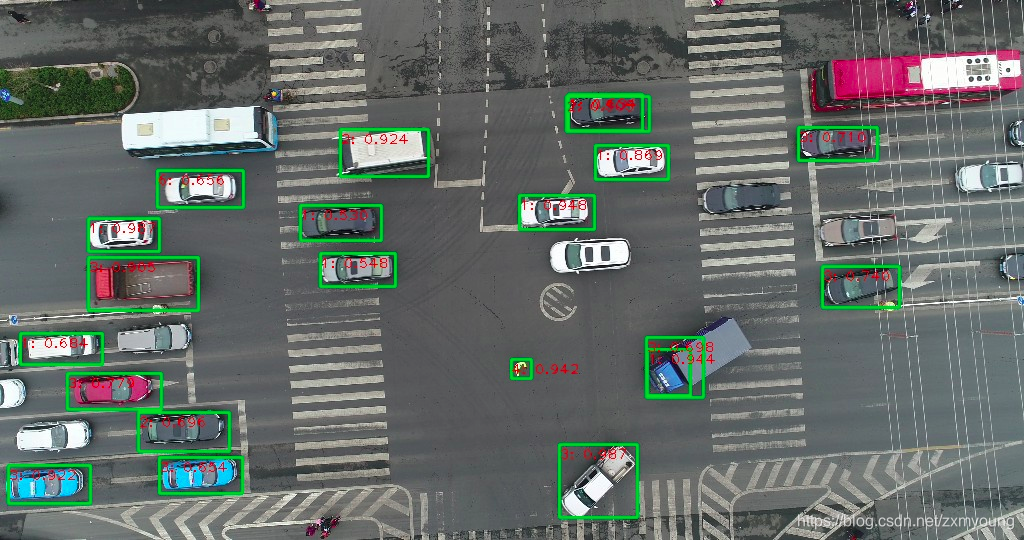

四、在已经训练好的模型上继续训练自己的数据
假如你需要做某个场景下的目标检测,但手上的数据集样本很小,而网上有其他一些大样本的数据集,此时就可以先用大样本的数据预训练一个模型,然后用自己的小数据集在预训练模型上继续训练,使之更加适应我们的场景,也可以提高我们模型的鲁棒性。具体步骤如下:
4.1 本次做文本检测,选用的大样本数据集为COCO2014文本检测数据集,下载链接:数据集标签文件,数据集所有图片,注意COCO2014数据集的标注格式和VOC2007的标注格式不同,因此需要将其转换成VOC格式,具体转换方法见:https://blog.youkuaiyun.com/qq_38497266/article/details/99950471
4.2 用COCO2014数据集先训练模型,训练的迭代次数不能设置的过多,否则用自己的数据集继续训练出的模型结果不会很适应自己的场景,本次因为我自己的数据集只有300多张,因此在COCO2014数据集上只迭代了2轮,训练好的模型保存路径为:./models/vgg16/pascal_voc/faster_rcnn_1_2_33659.pth
4.3 将自己的数据集放入data/VOCdevkit/VOC2007文件夹中,在COCO2014数据集上迭代了2轮的基础上继续训练,命令行输入下面命令:
python trainval_net.py --epochs 10 --cuda --r True --checksession 1 --checkepoch 2 --checkpoint 33659其中--r True checksession 1 --checkepoch 2 --checkpoint 33659这几个参数表明在faster_rcnn_1_2_33659.pth模型基础上继续训练至第10轮,--r 默认情况是False,表示每次训练都是从第一轮重新开始训练模型
4.4 测试+demo
同上面测试步骤一样


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









