









参考各位大神:https://zhuanlan.zhihu.com/p/98059235
https://blog.youkuaiyun.com/Lighter_Go/article/details/106917245
https://blog.youkuaiyun.com/lianggyu/article/details/100076153
https://blog.youkuaiyun.com/weixin_43730508/article/details/106225270
https://blog.youkuaiyun.com/weixin_43935669/article/details/102766183
https://www.cnblogs.com/xiximayou/p/12546556.html
https://blog.youkuaiyun.com/dingkm666/article/details/88775428
西西嘛呦讲解的比较详细
https://www.cnblogs.com/xiximayou/p/12552854.html
最近做实验,参考各位大神的教程来跑自己的数据集,
整个过程做一个记录,为以后的复现做参考。
所用的代码地址:https://github.com/lufficc/SSD
这份代码是比较新的,比起两年前star数量最多的SSD Pytorch实现有更多的灵活度,更详细的文档,作者给出了不同的Backbone,在readme里面给出了特别详细的修改指导,对于想要自己更改网络,写自己的数据类的小伙伴,强烈安利!在此感谢原作者。
因为安装使用SSD和源码解读是很大两块内容,分俩个部分来写,第一部分主要是关于SSD的使用。
SSD安装/训练/推理
安装:(ubuntu环境)对于如何安装并跑这份代码作者在readme里面写得简直不能太详尽,只补充几个注意点:
- 养成好习惯,尽量在conda 里面创个虚拟环境
- CUDA9/10皆可,但是CUDA8是不行的
- 小Tip: conda install torchvision==0.3.0,一行命令基本帮忙把torch相关依赖都装上了
git clone https://github.com/lufficc/SSD.git
cd SSD
# Required packages: torch torchvision yacs tqdm opencv-python vizer
pip install -r requirements.txt
# Done! That's ALL! No BUILD! No bothering SETUP!
插播一下数据准备:
新建一个datasets文件夹。源码支持coco/voc格式,当然你也可以自定义一个数据接口,这个作者也有指导!自己写数据类请参考ssd/data/datasets/目录下的coco.py和voc.py
对于voc:
--datasets
| --voc2007
| --Annotations
| --1.xml,2.xml,....,......
| --JPEGImages
| --1.jpg,2.jpg,....,......
| --ImageSets
| --Main
| --test.txt #用于测试的。形如1,2,3,4...也就是index 加上.xml或者.jpg就是标签和图像的名字
| --train.txt #用于训练的
| --trainval.txt #训练加验证
| --val.txt #验证
仿照VOCDataset(torch.utils.data.Dataset)写一个针对自己特定数据格式的类就可!
对于想自己定义数据类以及更改网络结构的,给出原作者的指导
https://github.com/lufficc/SSD/blob/master/DEVELOP_GUIDE.md
含有三个目标的voc格式的.xml文件标长这样:
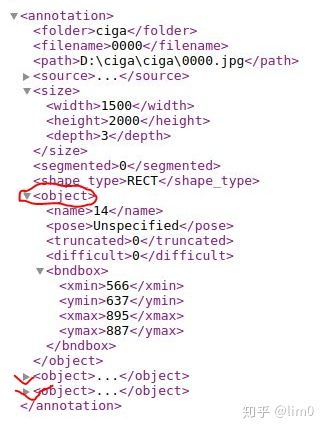
注意:这边有个坑,原作者是在训练时同事用了VOC2007和VOC2012的格式。所以在自己的数据集中也要有这两种格式的,其实就是吧VOC2007的复制一下,然后把名字改成VOC2012就行。
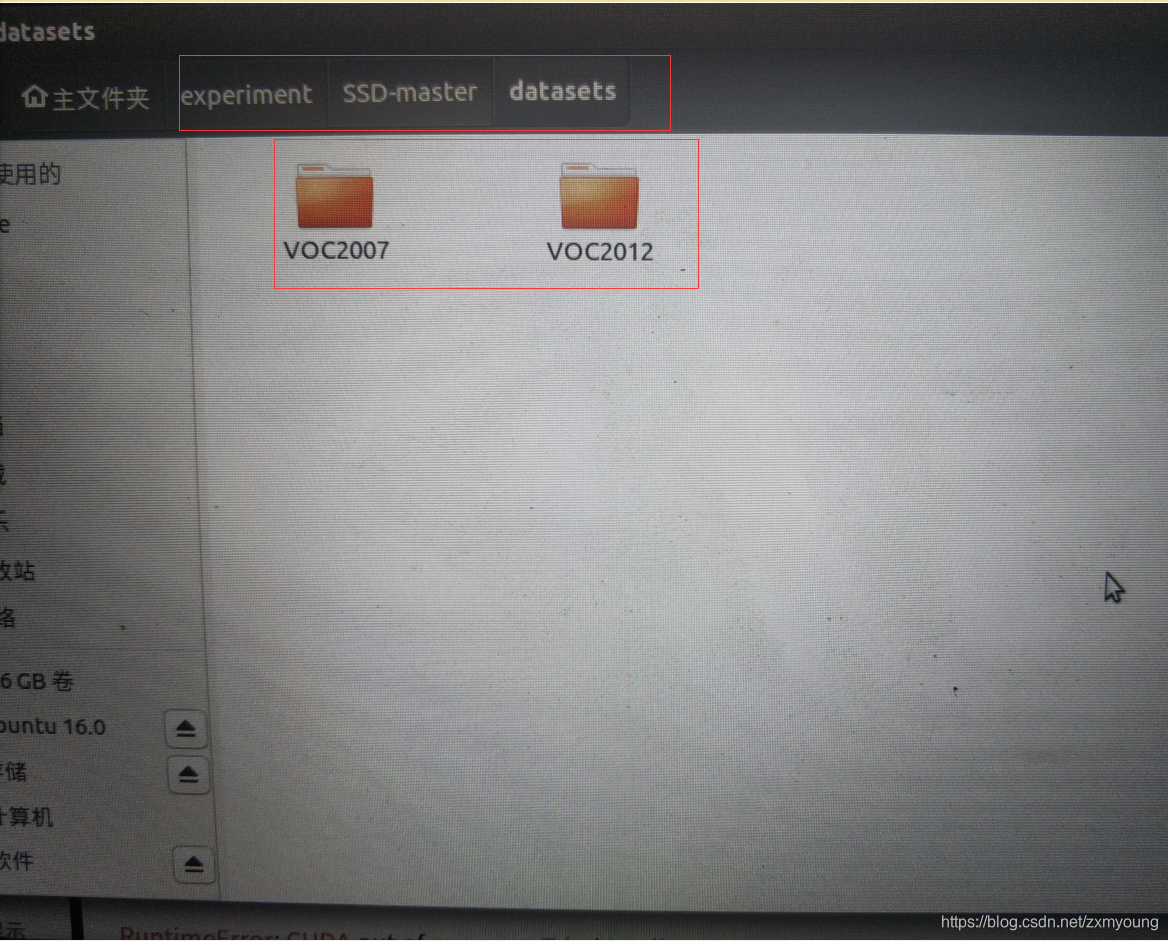
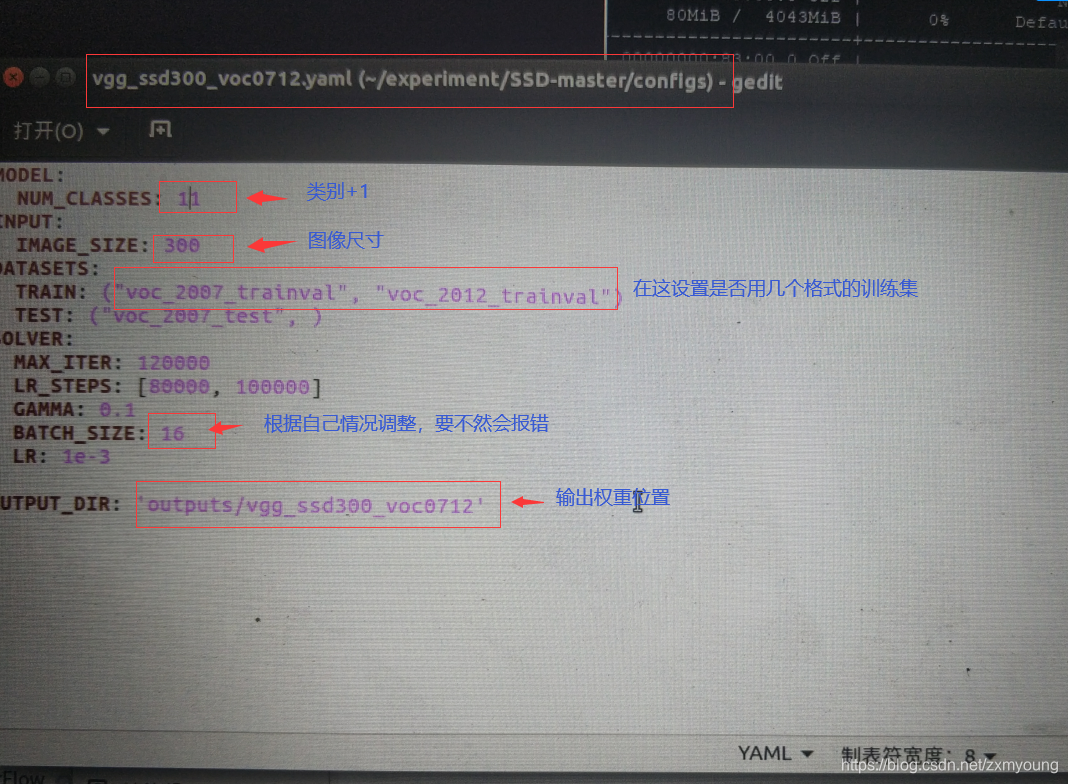
当然也可以只用VOC2007,只需要在SSD-master/configs/vgg_ssd300_voc0712.yaml中设置就行
训练阶段
建立好自己数据后,需要把它的路径写到 ssd/config/path_catlog.py中,同时在configs/vgg_ssd300voc0712.yaml文件中指定所用数据。为了方便,上面我直接把自己的数据就命名为VOC2007,这样其实不需要改 pathcatlog.py.
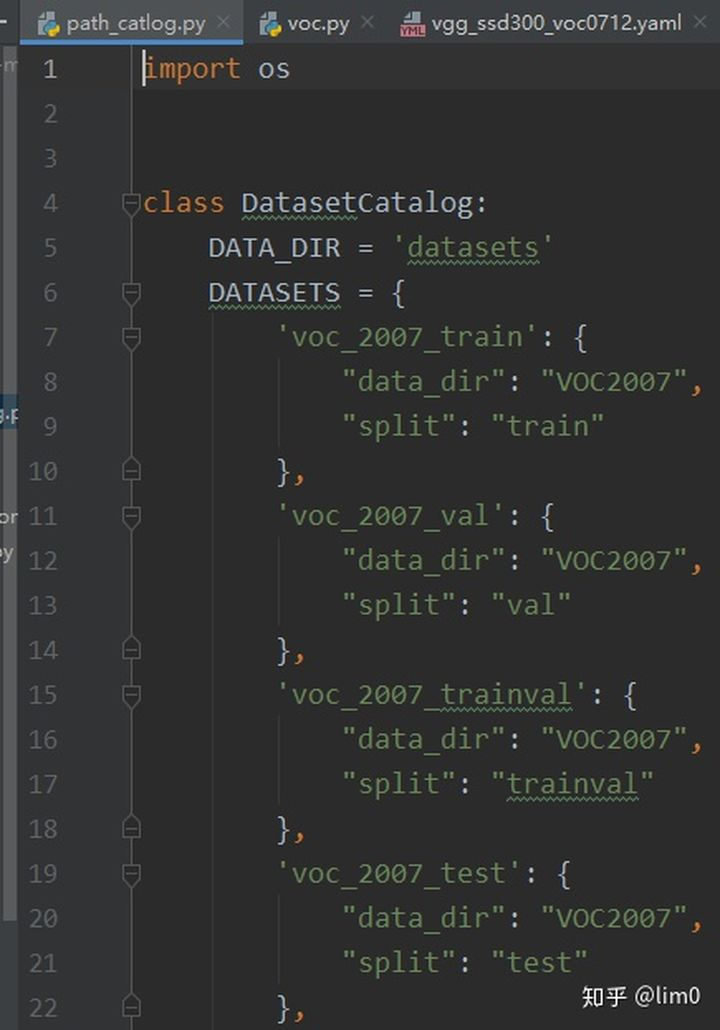
注意要点:还有一个特别需要注意的点就是类别的更改,在SSD-master/default.py和,configs/vgg_ssd300voc0712.yaml中的NUM_CLASSES是自己的数据的类别,记得加上背景,且一定要和数据集中的一样,而且不能有大写,空格等符号,只能是小写字母。同时,一定要在SSD-master/ssd/data/datasets/voc.py或者SSD-master/ssd/data/datasets/coco.py中(如果用的voc/coco格式)将类别标签都改为自己的.
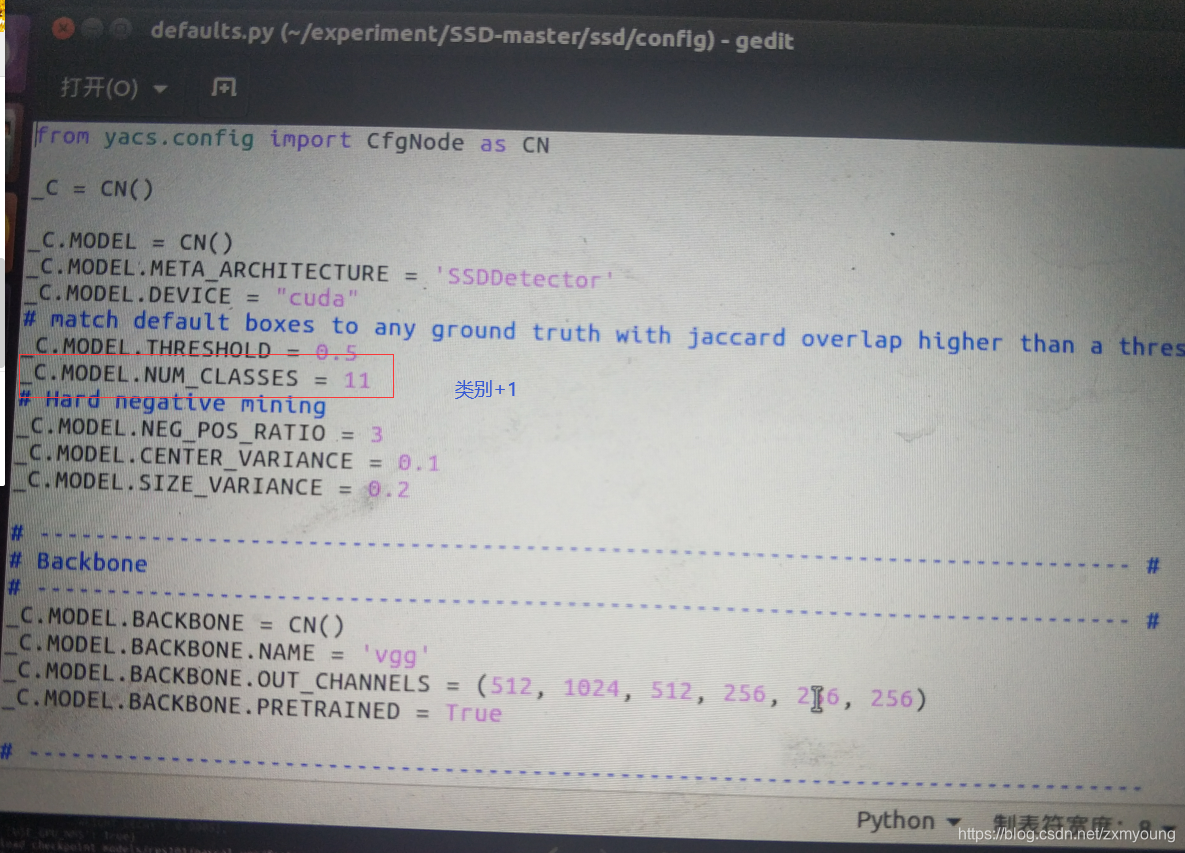
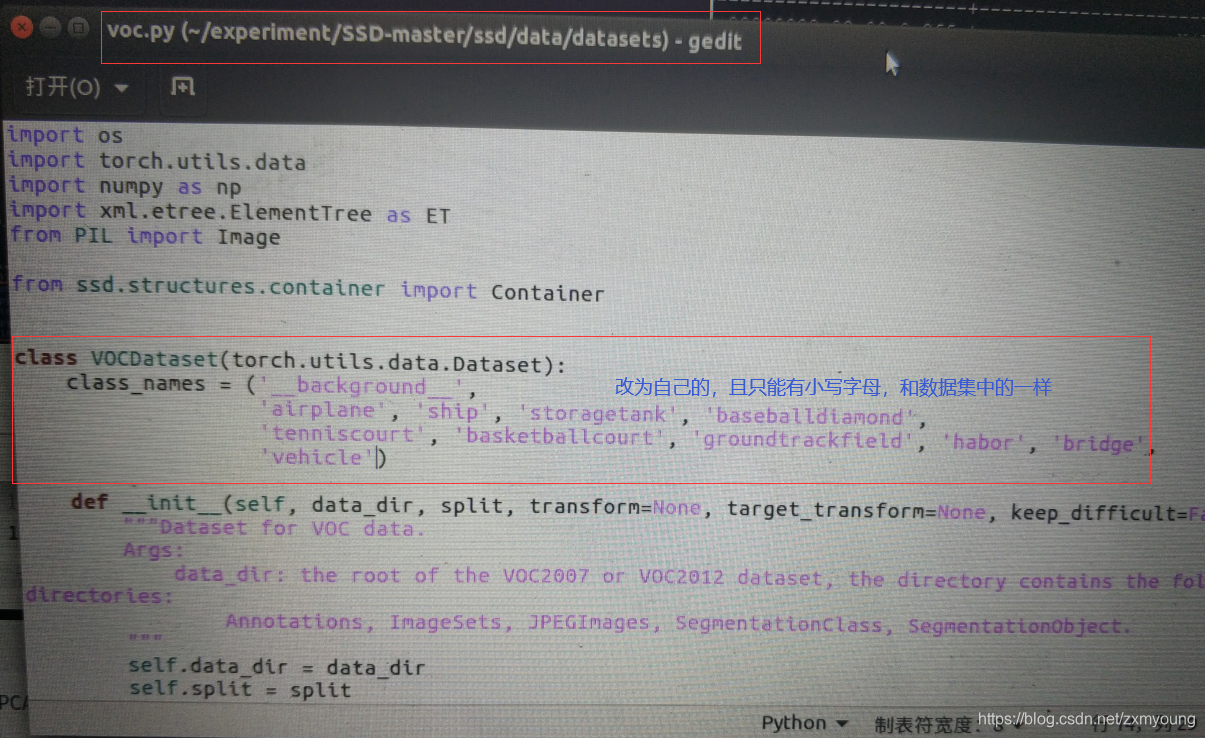
注意:
运行train.py的训练的时候,由于在ssd/config/default.py中,默认是vgg网络作为backbone,但是如果你选择了使用预训练模型,那么往往会遇到一个问题,预训练模型需要到程序中指定的那个url去下载,但往往会失败。所以,这个时候不如到网上找一个vgg16的预训练模型vgg16_reducedfc.pth,根据错误提示,把模型放到~/.torch/models/下面,要在命令行下面操作,.torch是隐藏文件,图形界面找不到的
# for example, train SSD300:
python train.py --config-file configs/vgg_ssd300_voc0712.yaml我的下载好,手动放置到所提示的位置:
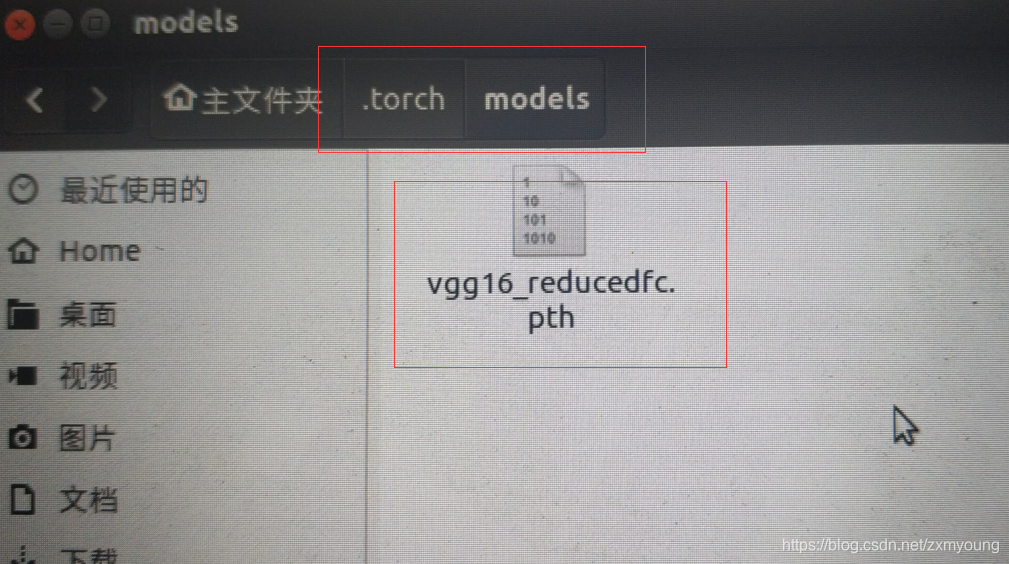
接下来是对里面的几个关键文件作一个说明:
ssd/config/defaults.py和 configs/vgg_ssd300_voc0712.yaml:这两个是都是这个工程的参数配置,yaml比前者的优先级高,yaml没有的到defaults里面找,使用何种backbone,输入图片大小,特征图,默认框的生成配置,训练配置等等都在里面。几个关键的点:
更换backbone:
这个对应了defaults.py中的# Backbone部分,在ssd/modeling/backbone目录下面可以看到,作者提供了三个backbone。但是并非简简单单的把_C.MODEL.BACKBONE.NAME = 'vgg'换成mobilenet或者efficientnet就可。前面的链接里面作者也给出了指导:
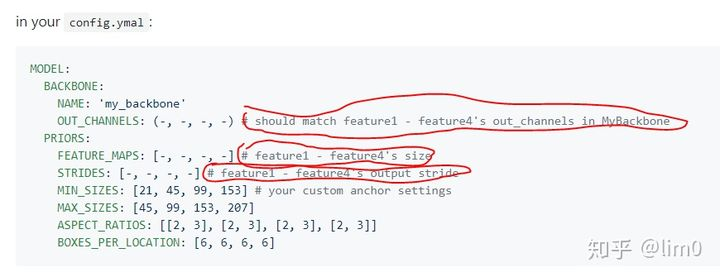
但是问题来了,这几个参数该咋改呢,咋知道mobilenet对应的几个特征图的输出通道和大小呢?当然只能去看在ssd/modeling/backbone目录下面的源码了,以下对于更换为mobilenet的情况作一个说明。源码支持300和512大小的图像输入,对于300x300的输入,尝试着自己打印一下作者定义的mobilenet为基础的banckbone的网络就很容易得到各个特征图的信息:
torch.Size([2, 96, 19, 19])
torch.Size([2, 1280, 10, 10])
torch.Size([2, 512, 5, 5])
torch.Size([2, 256, 3, 3])
torch.Size([2, 256, 2, 2])
torch.Size([2, 64, 1, 1])
#输出通道分别是[96,1280,512,256,256,64]
#大小分别是[19,10,5,3,2,1]
#STRIDES代表了特征图框放大到原始图的缩放比例,输入图像是300x300,
#那么300除以各个特征图的大小就对应了比例:[15,30,60,100,150,300]
对于不能整除的情况,可以近似(这一点其实我也不是特别的理解,
我觉得完全可以在设计网络阶段就把其全都设计为整除的啊)
插播一句:
_C.MODEL.PRIORS.MIN_SIZES #这个和特征图的个数有关,因为都是6个,不需改所以更改后:
(注意一定要把mobilenet名字写全,看源码里面叫啥:是叫mobilenet_v2啊!!!!!!)
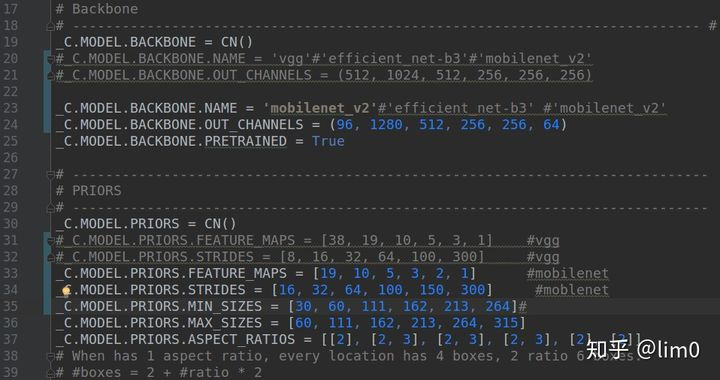
顺便给出imgesize=512对应的vgg和mobilenet_v2的特征图size信息
512输入对应的vgg的六个FeatureMap
torch.Size([2, 512, 64, 64])
torch.Size([2, 1024, 32, 32])
torch.Size([2, 512, 16, 16])
torch.Size([2, 256, 8, 8])
torch.Size([2, 256, 6, 6])
torch.Size([2, 256, 4, 4])
512输入对应的mobilenet_v2的六个FeatureMap
torch.Size([2, 96, 32, 32])
torch.Size([2, 1280, 16, 16])
torch.Size([2, 512, 8, 8])
torch.Size([2, 256, 4, 4])
torch.Size([2, 256, 2, 2])
torch.Size([2, 64, 1, 1])
至于lr,batch_size,模型输出路径等到.yaml中修改
推理
参考:demo.py
补充说明,源码中是用的vizer库在绘图,但是我感觉这给绘出来的图太细了,而且不支持中文显示,我没搞懂怎么调,于是用cv2和PIL重新写了一遍
附上linux下中文字体的路径:
/usr/share/fonts/truetype/arphic/uming.ttc



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









