







题目描述:
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
示例:
输⼊: n = 4, k = 2
输出: [
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
思路:
对于给出的用例,要选出集合个数为2的所有组合,很容易想到的是双重for循环解决问题,集合个数为3的话就嵌套三层for循环,那集合个数为50、100呢?这种暴力for循环是解决不了问题了,我们就需另找它法了。
虽然回溯法很低效,但是对于这种问题却可以得出正确的答案。
根据上述出现的问题,for循环层数太多,无法写出,而回溯法就是用递归来解决嵌套层数的问题。递归来做层叠嵌套(可以理解是开k层for循环),每⼀次的递归中嵌套⼀个for循环,那么递归就可以用于解决多层嵌套循环的问题了。
关于为什么 for+递归 可以解决多层嵌套循环问题的思考,下面以上述示例的集合[1,2]为例解释:
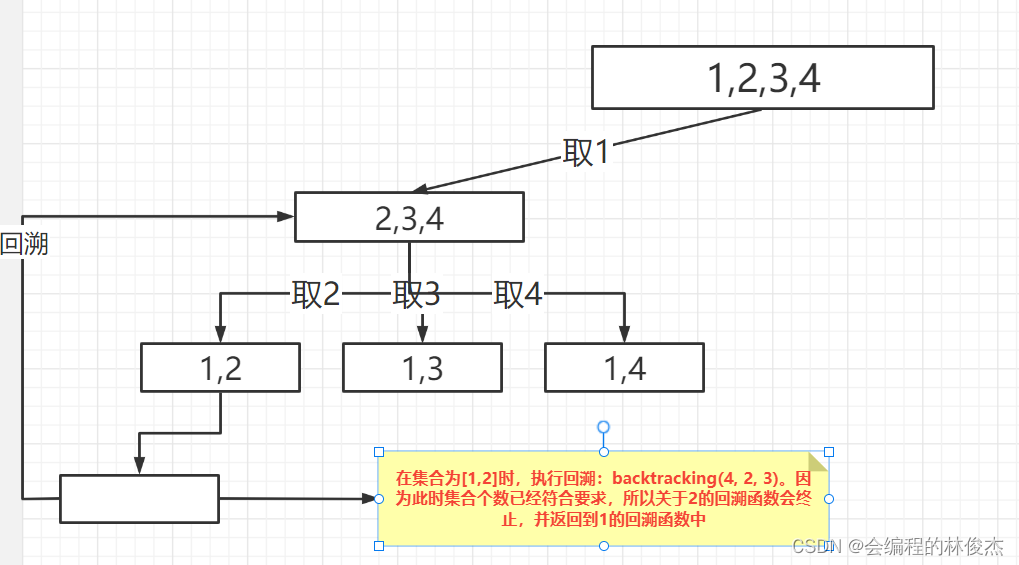
注:每次回溯终止返回都是返回到了它的上一层,然后接着执行for循环。对这儿的阐述可能不太准确,但是通过举例子去思考这个过程就能想明白。
穷举过程如下图所示:
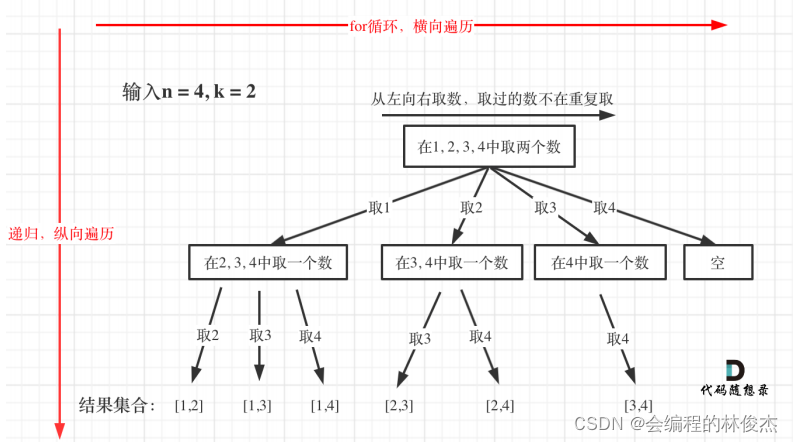
回溯三部曲:
- 定义方法返回值及参数:
在这里要定义两个全局变量,⼀个用来存放符合条件单⼀结果,⼀个用来存放符合条件结果的集合。
代码如下:
vector<vector<int>> result; // 存放符合条件结果的集合
vector<int> path; // ⽤来存放符合条件结果其实不定义这两个全局遍历也是可以的,把这两个变量放进递归函数的参数里,但函数里参数太多影响可读性,所以我定义全局变量了。
函数里⼀定有两个参数,既然是集合n里面取k的数,那么n和k是两个int型的参数。
然后还需要⼀个参数为int型变量startIndex,这个参数用来记录本层递归的中,集合从哪里开始遍历 (集合就是[1,...,n] )。
为什么要有这个startIndex呢?
从上述穷举图可以看出,每次从集合中选取元素时,为了保证选出的集合是组合而不是排列,所以可选择的范围随着选择的进行而收缩,这就需要一个变量 startIndex 来调整可选择的范围。
所以,函数定义为:void backtracking(int n, int k, int startIndex)
- 终止条件:
path这个数组的大小如果达到k,说明我们找到了⼀个子集大小为k的组合了,此时用result二维数组把path保存起来,并终止本层递归。
所以终止条件的代码为:
if (path.size() == k) {
result.push_back(path);
return;
}- 单层搜索过程:
for循环每次从startIndex开始遍历,然后用path保存取到的节点。
代码如下:
for (int i = startIndex; i <= n; i++) { // 控制树的横向遍历
path.push_back(i); // 处理节点
backtracking(n, k, i + 1); // 递归:控制树的纵向遍历,注意下⼀层搜索要从i+1开始
path.pop_back(); // 回溯,撤销处理的节点
}注:backtracking(递归函数)通过不断调用自己⼀直往深处遍历,总会遇到叶子节点,遇到了叶子节点就要返回
代码:
class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> combine(int n, int k) {
backtracking(n, k, 1);
return result;
}
public void backtracking(int n, int k, int startIndex) {
if(path.size() == k) {
result.add(new ArrayList<>(path));
return;
}
for(int i = startIndex; i <= n; i++) {
path.add(i);
backtracking(n, k, i + 1);
path.remove(path.size() - 1);
}
}
}遇到的问题:
- ArrayList中remove方法的语法为:
// 删除指定元素
arraylist.remove(Object obj)
// 删除指定索引位置的元素
arraylist.remove(int index)- res.add(new ArrayList<>(path))和res.add(path)的区别:
共同点:
都是向res这个ArrayList中填加了一个名为path的链表。
不同点:
res.add(new ArrayList(path)):开辟一个独立地址,地址中存放的内容为path链表,后续path的变化不会影响到res。
res.add(path):将res尾部指向了path地址,后续path内容的变化会导致res的变化。
剪枝优化:
举例:当 n = 4, k = 4
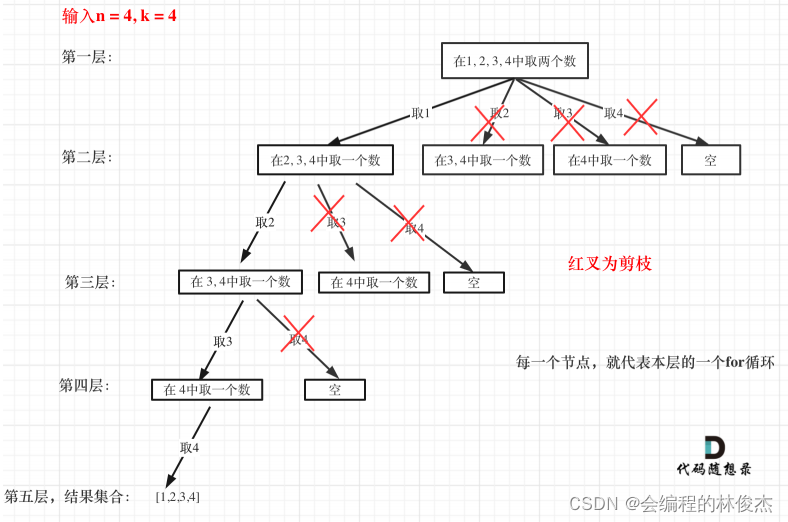
通过分析可知,当起始位置之后的元素个数不满足所需元素个数时,进行的都是无效遍历,所以可以剪枝的地方就在递归中每一层for循环所选择的起始位置。
优化过程如下:
1. 已经选择的元素个数:path.size();
2. 还需要的元素个数为: k - path.size();
3. 在集合n中至多要从该起始位置 : n - (k - path.size()) + 1,开始遍历
由
for (int i = startIndex; i <= n; i++)
优化为
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++)
问题:至于 + 1 的问题,需要根据下标情况来分析?
不确定是否要加一,可以通过举例来判断,如果不加一符合题目要求,那就不加,反之则加。本题加一,我觉得是因为for循环是从1开始,到n才结束。
代码:
class Solution {
List<List<Integer>> result = new ArrayList<>();
List<Integer> path = new ArrayList<>();
public List<List<Integer>> combine(int n, int k) {
backtracking(n, k, 1);
return result;
}
public void backtracking(int n, int k, int startIndex) {
if(path.size() == k) {
result.add(new ArrayList<>(path));
return;
}
for(int i = startIndex; i <= n - (k - path.size()) + 1; i++) {
path.add(i);
backtracking(n, k, i + 1);
path.remove(path.size() - 1);
}
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









