




到新公司实习的第一个项目就是爬指定关键词搜索出的微信公众号文章统计词频进行热度分析,这篇博客先简单回顾一下一个简单的爬虫需要哪些步骤:
发送请求获取响应内容->解析内容->保存数据
1. 发送请求获取响应内容
要爬取一个网页首先要有网址,我们通过http库向此目标站点发起请求request,然后获取响应的内容response。
首先我们先要知道http请求的格式:
- 第一行必须是一个请求行(requestline),用来说明请求类型、要访问的资源以及使用的HTTP版本。
- 紧接着是一个首部(header)小节,用来说明服务器要使用的附加信息。
- 在首部之后是一个空行,再此之后可以添加任意的其他数据[称之为主体(body)。
通过http请求的第一行请求行,我们就可以知道我们访问的网址是post还是get请求,然后才能开始我们的第一步用request的post或者get方法发送请求。
request.get()
requests.get(url, params=None, **kwargs)
- url为我们要访问的网站
- params 为参数
- kwargs包括headers和proxies,其中**headers就是我们加的头(也就是上述http请求第二行的内容),模拟浏览器访问此url。 因为有些网站会检查你是否为浏览器,如果是程序就会拒绝你的访问。
下面举个用requests的get方法获取目标站点的响应内容
import requests
dicheader = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4549.400 QQBrowser/9.7.12900.400'
} #dicheader就是我模拟的浏览器的头
url=‘http://weixin.sogou.com/’ #搜狗微信搜索页面
page = requests.get(url, headers=dicheader) #获取响应的内容request.post()
requests.post(url,data)
- url 访问的网址(翻页网址不会改变)
- data 就是上述http请求格式第三行的内容;data是我们使用post请求必不可少的一部分,因为一般post的网址不会改变,我们要翻页时一般都改变的是data中的参数。
2. 解析内容
抓取到结果后就对内容进行解析,首先要将获取的响应内容解码,常用的两种是utf8和gbk具体是哪张取决于你访问的网站
html = page.content.decode("UTF8")接下来就可以进行解析了,解析的方法有很多,如xpath、pq、beautifulsoup等,我用的最多的是pq。
pq是Python的pyquery模块,可以通过标签、类名、id号提取你想要的数据。
我使用解析内容一般分为两步,首先用正则表达式把包含你想要的结果的区域提取出来,然后再使用pq。
举个栗子:
我要获取到搜狗微信搜索某一关键词后所返回结果列表的每篇文章的名称
首先,我要在浏览器中找到我想获取数据的区域点击右键检查,找到包含这块区域的字符,如下图红色区域就是我用正则表达式选择的区域,这样会提高使用pq的效率。
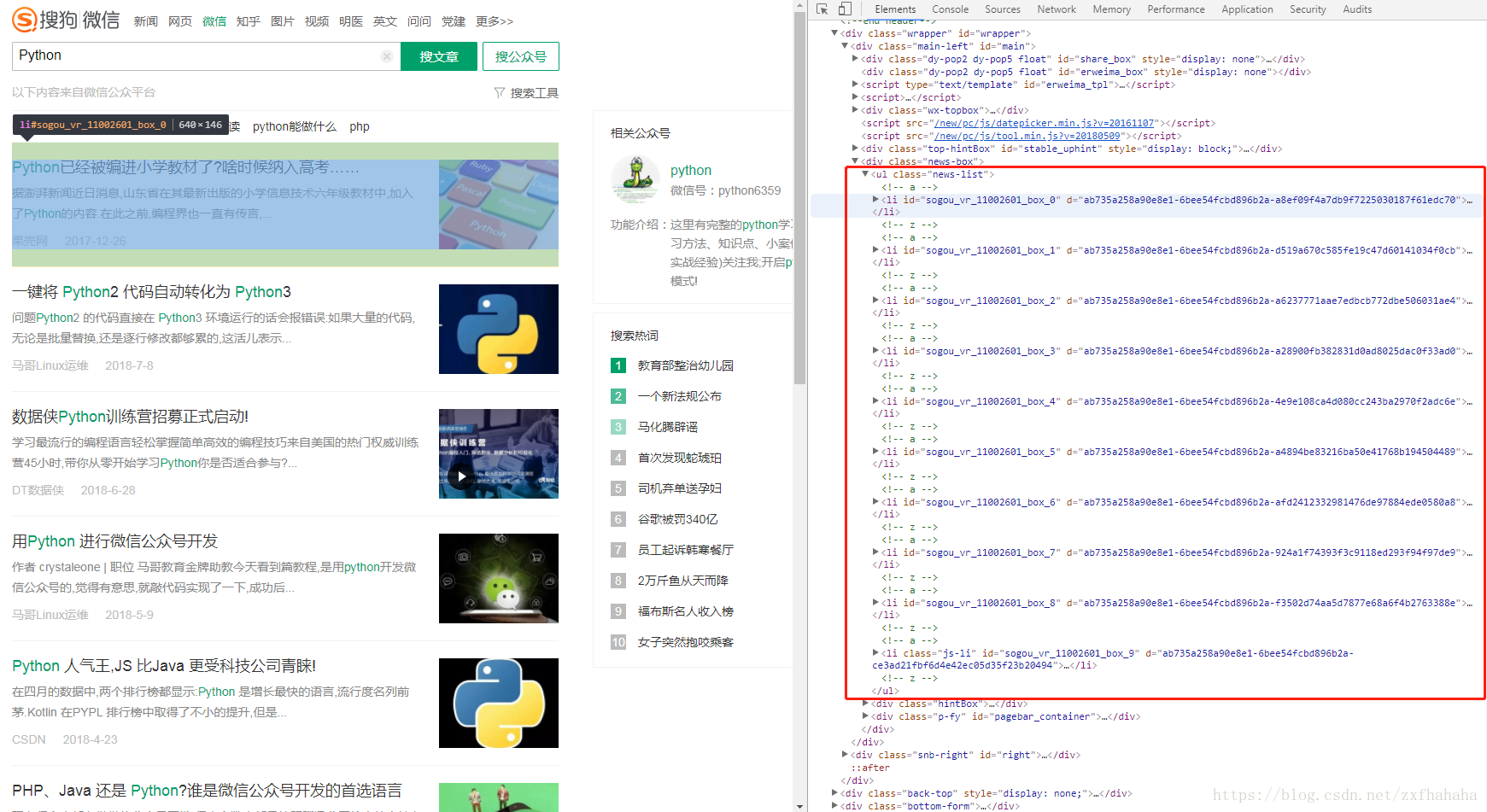
然后我们通过检查可以发现一个文章对应html中的一个li标签,即每个
- 中的内容就是一篇文章的相关信息,所以我用pq把每天li标签包含的内容提取到doc。通过检查我们可以看到文章的标题的共性通过遍历doc获取我们想要的文章标题。
strpattern = r'(?<=<ul class="news-list">).+?(?=</ul>)' # <ul class="news-list">和</ul>之间的内容就是文章的列表 pt = re.compile(strpattern, re.S) mch1 = re.search(pt, html) # 找到组1 wzbt=[] if mch1 != None: doc = pq(mch1.group(0))('li') # 每个li就是列表中的一条记录 for it in doc.items(): # 分析每一条记录 wzbt.append(it('.txt-box h3 a').text()) #文章标题

















 6115
6115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









