



 本文介绍了电商搜索算法竞赛中的词向量预处理和训练过程。通过加载数据、使用jieba分词、gensim训练Word2Vec模型,构建商品和查询的词向量表示。之后利用最大池化或平均池化将句子编码,并提出使用sentence-bert和simcse等更高级技术可提升搜索任务的效果。
本文介绍了电商搜索算法竞赛中的词向量预处理和训练过程。通过加载数据、使用jieba分词、gensim训练Word2Vec模型,构建商品和查询的词向量表示。之后利用最大池化或平均池化将句子编码,并提出使用sentence-bert和simcse等更高级技术可提升搜索任务的效果。
以下学习笔记来源于 Datawhale202203 NLP竞赛学习课程的任务二:词向量介绍与训练。
地址:https://github.com/datawhalechina/team-learning-data-mining/tree/master/ECommerceSearch
竞赛链接:https://tianchi.aliyun.com/specials/promotion/opensearch
赛题介绍
本次题目围绕电商领域搜索算法,开发者们可以通过基于阿里巴巴集团自研的高性能分布式搜索引擎问天引擎(提供高工程性能的电商智能搜索平台),可以快速迭代搜索算法,无需自主建设检索全链路环境。
本次评测的数据来自于淘宝搜索真实的业务场景,其中整个搜索商品集合按照商品的类别随机抽样保证了数据的多样性,搜索Query和相关的商品来自点击行为日志并通过模型+人工确认的方式完成校验保证了训练和测试数据的准确性。
词向量介绍与训练
加载并处理数据
import numpy as np
import pandas as pd
import os
from tqdm import tqdm_notebook
corpus_data = pd.read_csv( "./data/corpus.tsv", sep="\t", names=["doc", "title"])
dev_data = pd.read_csv("./data/dev.query.txt", sep="\t", names=["query", "title"])
train_data = pd.read_csv("./data/train.query.txt", sep="\t", names=["query", "title"])
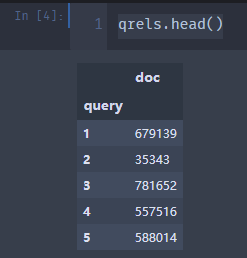
qrels = pd.read_csv("./data/qrels.train.tsv", sep="\t", names=["query", "doc"])
corpus_data = corpus_data.set_index("doc")
dev_data = dev_data.set_index("query")
train_data = train_data.set_index("query")
qrels = qrels.set_index("query")
qrels.head()
for idx in range(1, 20):
print(
train_data.loc[idx]["title"],
"\t",
corpus_data.loc[qrels.loc[idx].ravel()[0]]["title"],
)

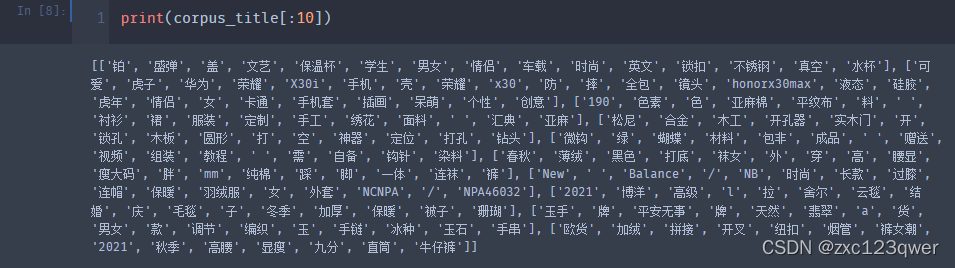
使用jieba进行分词处理
def title_cut(x):
return list(jieba.cut(x))
from joblib import Parallel, delayed
corpus_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in corpus_data["title"])
train_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in train_data["title"])
dev_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in dev_data["title"])
使用gensim训练词向量
from gensim.models import Word2Vec
from gensim.test.utils import common_texts
if os.path.exists("./model_storage/word2vec.model"):
model = Word2Vec.load("./model_storage/word2vec.model")
else:
model = Word2Vec(
sentences=list(corpus_title) + list(train_title) + list(dev_title),
vector_size=128,
window=5,
min_count=1,
workers=4,
)
model.save("./model_storage/word2vec.model")
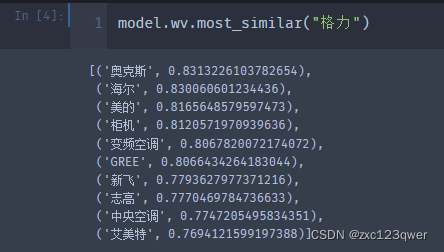
计算与格力最相似的top10单词
将句子转化为编码
此处仅使用简单的最大池化和平均池化,在后面的任务会考虑idf来删除句子中一些不重要的词,保留一些关键词。
def unsuper_w2c_encoding(s, pooling="max"):
corpus_query_word = s
feat = model.wv[corpus_query_word]
if pooling == "max":
return np.array(feat).max(0)
if pooling == "avg":
return np.array(feat).mean(0)
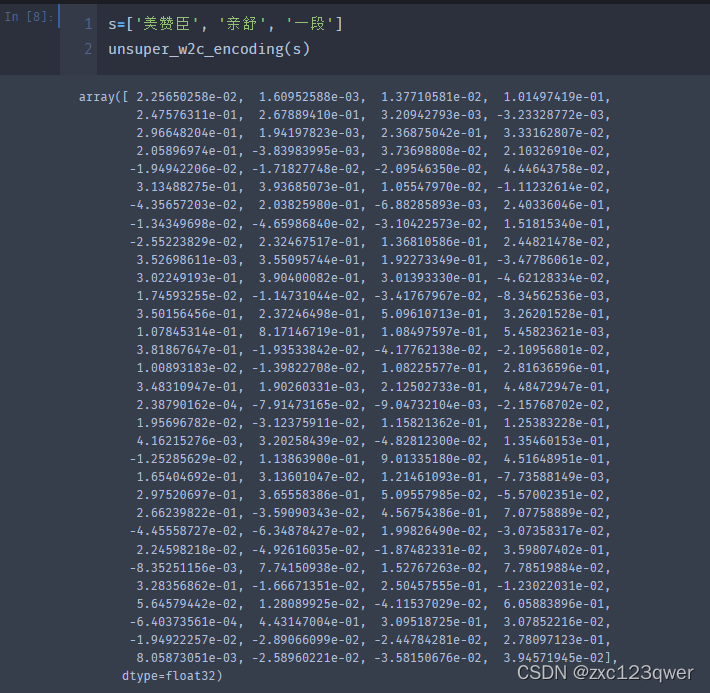

可以看到是128维的
总结
比较基础的词向量训练,将单词转为128维度的词向量编码,之后使用max_pooling或avg_pooling将该句子包含的词向量转为句子编码,加入idf后可以得到0.035左右的分数,可以对句子进行一些简单的去标点符号、去停用词等处理,分数应该会有小幅度提升。对于语义搜索任务可以尝试使用sentence-bert结合比赛标注数据进行训练或使用simcse无监督对比学习训练,效果比单纯的训练词向量再进行句子编码要好很多。

















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









