






这些都是我自己学到的python的知识点,总结了一下,分享出来希望能够帮助到大家!
写python代码,可以用pycharm软件
下滑到最下面有免费的社区版可以下载
一. 基础知识概括
1.输出语句以及格式化输出
str = "Hello World!"
print(str)
print(f"第一条程序{str}")
2.输入语句
输入的默认为字符串,需要可以转换为其他类型
例:str = int(input())
str = input()3.条件语句
if~else , if~elif~else,
if 10 > 8:
print("10大")
elif 9 > 10:
print("9小")
elif 8 > 10:
print("8小")
else:
print("全都不对!")4.循环语句
while和for循环
# while循环
i = 1
while i <= 10:
print("Hello World!")
i += 1
# for循环
# 输出十个 Hello World!
for i in range(10):
print("Hello World!")
# 输出0~9
for i in range(10):
print(i)
5.break和continue语句
for i in range(10):
print("语句1")
continue
print("语句2") # 不执行语句2
for j in range(100):
print("语句")
break # 执行一次就跳出循环6.函数
6.1.函数的定义与调用
def name(): # def+函数名+(传入参数)
print("Hello World!") # 函数体
return # 返回值
name() # 调用6.2.函数的文档说明
def add(x, y):
"""
add函数可以实现两数相加
:param x:一个数
:param y:另一个数
:return:结果
"""
sum = x + y
return sum6.3.函数的多个返回值
def number():
return 1, 'hello', True
a, b, c = number()
print(a, b, c)
7.数据容器
7.1.列表
# 列表
my_list = [1, 2, 3, 4, 5, 6]
# 列表的方法
a = my_list.index(5) # 查找元素的下标
# 输出为 4
my_list[0] = 5 # 修改1号元素的值为5
# 输出为 [5, 2, 3, 4, 5, 6]
my_list.insert(6, 7) # 在7号位置插入元素7
# 输出为 [5, 2, 3, 4, 5, 6, 7]
my_list.append(8) # 将指定元素8追加到列表的尾部
# 输出为[5, 2, 3, 4, 5, 6, 7, 8]
del my_list[0] # 删除第一个元素
# 输出为 [2, 3, 4, 5, 6, 7, 8]
my_list.pop(0) # 删除第一个元素
# 输出为 [3, 4, 5, 6, 7, 8]
my_list.remove(3) # 指定元素删除列表中的第一个该元素
# 输出为 [4, 5, 6, 7, 8]
print(len(my_list)) # 统计列表的长度
# 输出为 5
my_list.clear() # 清空列表
# 输出为 [] 空
# 用循环遍历列表
my_list = [1, 2, 3, 4, 5, 6]
for i in my_list:
print(i, end=' ') # 输出不换行
7.2. 元组
元组的方法函数与列表类似,可以参考列表
# 定义一个元组
tuple1 = (1, 2, 3)
# 元组的嵌套及下标
my_tuple = ((1, 2, 3), (4, 5, 6))
print(my_tuple[1][2])
# 元组不可修改,但元组内嵌套list可以修改
tuple2 = (1, 2, [3, 4, 5])
tuple2[2][0] = 2
print(tuple2)7.3.字符串
字符串的定义,替换,以及分割
# 定义一个字符串
str = 'Hello World!'
# 字符串的替换
my_str = "name is cxk"
new_my_str = my_str.replace("name", "your name")
print(f"原字符串:{my_str}")
print(f"新:{new_my_str}")
# split分割字符串,会得到一个list
my_str = "yuan sheng qi dong"
my_str_list = my_str.split(" ")
print(my_str_list)
# 输出为 ['yuan', 'sheng', 'qi', 'dong']
字符串的规范操作,strip方法
my_str = " your name "
new_my_str = my_str.strip() # 不传入参数,去除首尾空格
print(f"原字符串:{my_str}")
print(f"新:{new_my_str}")
# 输出为: 原字符串: your name
# 新:your name
my_str = "12your name21"
new_my_str = my_str.strip("12") # 传入参数,去除首尾的"12"
print(f"原字符串:{my_str}")
print(f"新:{new_my_str}")
# 输出为: 原字符串:12your name21
# 新:your name
统计字符串中某字符串的次数,
count my_str = "swustfghswustdfgh"
cnt = my_str.count("swust")
cnt = 2
len()统计长度
7.4.数据容器的序列(列表,字符串,元组)
序列的切片操作--取出一个子序列,注意:[1:4:1]第一个1表示的是从第一号元素开始,数据容器都是从零号元素开始的;第二个4表示的是第三号元素,4-1;第三个1表示的是步长为1,也就是每间隔多少切一个片。
# list
list1 = [0, 1, 2, 3, 4]
new_list = list1[1:4:1] # 默认步长为1
print(new_list)
# 输出为 [1, 2, 3]
# tuple
tuple1 = (1, 2, 3, 4, 5)
new_tuple = tuple1[1:5:2]
new_tuple1 = tuple[:] # 输出原本tuple
print(new_tuple)
# 输出为 (2, 4)
# 字符串
my_str = "01234567"
new_my_str = my_str[::2] # 从头到尾,步长为2
print(new_my_str)
# 输出为 0246
# 步长为负时
str1 = '0123456'
str2 = str1[::-1]
print(str2)
# 输出为 6543210
list1 = [0, 1, 2, 3, 4, 5]
list2 = list1[4:1:-1]
print(list2)
# 输出为 [4, 3, 2]
7.5.集合
定义一个集合
set1 = {1, 1, 2, 2, 3, 3, 4, 4} # 会去除重复的元素,顺序混乱
# 输出为 {1, 2, 3, 4}
set2 = set() # 空集合集合的方法,注意:集合内部的元素顺序是混乱的,无序性
# 添加元素
set = {1, 1, 1, 11, 111}
set.add(1111)
# 输出为:{1, 11, 1111, 111}
# 移除元素
set.remove(1)
# 输出为:{11, 1111, 111}
# 随机取出一个元素
element = set.pop()
print(f"取出的元素为:{element},取出元素后set为:{set}")
# 输出为:取出的元素为:11,取出元素后set为:{1111, 111}
# 清空集合
set.clear()
# 差集,set1有而set2没有的元素组成的集合
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.difference(set2) # set1和set2不会改变
# 输出:set3 = {2, 3}
# 集合1.different_update(集合2)--删除集合1内与集合2相同的元素
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set1.difference_update(set2)
# 输出:set1 = {2, 3}, set2 = {1, 5, 6}
# 合并两个集合,set1和set2不发生变化
set1 = {1, 2, 3}
set2 = {1, 7, 4, 6}
set4 = set2.union(set1)
# set4 = {1, 2, 3, 4, 6, 7}
统计集合内的数量, len()方法
集合的遍历,集合不支持下标索引,不能用while循环
用for循环
7.6.字典
定义一个字典
# 字典 dict{key:value,}
my_dict = {'name1': 99, 'name2': 88, 'name3': 77, 'name': 66}
# 定义空字典
my_dict1 = {}
my_dict2 = dict()从字典中基于key获取value,获取全部的keys和values
my_dict = {'name1': 99, 'name2': 88, 'name3': 77, 'name': 66}
print(my_dict['name1'])
# 输出为:99
my_dict.keys()
my_dict.values()
print(my_dict.keys())
print(my_dict.values())
# 输出为:dict_keys(['name1', 'name2', 'name3', 'name'])
# dict_values([99, 88, 77, 66])
字典的嵌套
# 字典的key和value可以是任意数据类型(key不可为字典)
stu_score_dict = {
'王力宏': {
'语文': 77,
'数学': 66,
'英语': 55,
}, '周杰伦': {
'语文': 88,
'数学': 99,
'英语': 100,
}, '林俊杰': {
'语文': 50,
'数学': 40,
'英语': 30,
}
}
print(stu_score_dict['王力宏']['数学'])
# 输出为:66字典的常用方法以及遍历
# (1)新增元素
dict1 = {'name1': 77, 'name2': 88}
dict1['name3'] = 99 # 若不存在,才添加
# dict1 = {'name1': 77, 'name2': 88, 'name3': 99}
# (2)更新元素
dict2 = {'name1': 77, 'name2': 88}
dict2['name1'] = 33 # 若存在,才更新
# dict2 = {'name1': 33, 'name2': 88
# (3)删除元素,pop()方法
dict3 = {'name1': 77, 'name2': 88}
score = dict3.pop('name1')
# dict3 = {'name2': 88}
# (4)遍历
my_dict = {'1': 22, '2': 33, '3': 44, '4': 55}
keys = my_dict.keys()
# 方式1:通过获取keys来遍历
for i in keys:
print(my_dict[i], end=' ')
print("\t")
# 输出为:22 33 44 55
# 方式2:直接
for i in my_dict:
print(i, end=' ')
print(my_dict[i], end=', ')
# 输出为:1 22, 2 33, 3 44, 4 55,
7.7.数据容器的通用操作
list1 = [1, 2, 3, 4, 5]
tuple1 = (1, 2, 3, 4, 5)
str1 = 'abcdefg'
set1 = {1, 2, 3, 4, 5}
dict1 = {'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4}
# max元素
print(max(list1)) # 输出为:5
print(max(tuple1)) # 输出为:5
print(max(str1)) # 输出为:g
print(max(set1)) # 输出为:5
print(max(dict1)) # 输出为:key4
# min元素
print(min(list1)) # 输出为:1
print(min(tuple1)) # 输出为:1
print(min(str1)) # 输出为:a
print(min(set1)) # 输出为:1
print(min(dict1)) # 输出为:key1
# 容器的通用排序
list1 = [3, 1, 2, 5, 4]
tuple1 = (3, 1, 2, 5, 4)
str1 = 'bcdagfe'
set1 = {3, 1, 2, 5, 4}
dict1 = {'key3': 1, 'key1': 2, 'key2': 3, 'key5': 4, 'key4': 5}
# 从小到大排序
print(sorted(list1)) # 输出为:[1, 2, 3, 4, 5]
print(sorted(tuple1)) # 输出为:[1, 2, 3, 4, 5]
print(sorted(str1)) # 输出为:['a', 'b', 'c', 'd', 'e', 'f', 'g']
print(sorted(set1)) # 输出为:[1, 2, 3, 4, 5]
print(sorted(dict1)) # 输出为:['key1', 'key2', 'key3', 'key4', 'key5']
# 从大到小
print(sorted(list1, reverse=True)) # 输出为:[5, 4, 3, 2, 1]
# 字符串的比较,是按位比较,也就是一位位进行对比,只要有一位大,那么整体就大
print('abd' > 'abc') # True
print('acb' > 'ad') # False列表推导式
d = [1, 2, 3]
new_list = []
for i in d:
new_list.append(i*2)
print(new_list)
# 相当于
new_list = [i*2 for i in d]
print(new_list)
# 加入if判断
new_list = [i*2 for i in d if i > 1]二. 异常,模块和包
1.异常
1.1.异常的定义
异常就是代码运行中的bug
try: # 可能会发生错误的代码
f = open("D:\pyhthon文件.txt", "r", encoding='UTF-8')
except: # 如果出现异常则执行的代码
f = open("D:\pyhthon文件.txt", "w", encoding='UTF-8')1.2.捕获异常
捕获指定异常,异常有很多类
try:
print(name)
except NameError as e: # 指定为NameError,将错误存入e中
print("出现了变量未定义的错误")
print(e)
# 输出为:name 'name' is not defined捕获多个异常
try:
1/0
print(name)
except (NameError, ZeroDivisionError):
print("出现了变量未定义的错误,或者除以0的错误")1.3.异常的用法
捕获所有异常,关键字Exception
try:
1/0
except Exception as e:
print("出现异常了")
print(e)
# 输出为:division by zero异常else
try:
print(b)
except:
print("出现异常了")
else:
print("没有出现异常")
# 输出为:出现异常了
finally表示的是无论是否异常都需要执行的代码,例如关闭文件
try: # 可能会发生错误的代码
f = open("D:\pyhthon文件.txt", "r", encoding='UTF-8')
except: # 如果出现异常则执行的代码
print("出现异常了")
f = open("D:\pyhthon文件.txt", "w", encoding='UTF-8')
else:
print("没有出现异常")
finally:
print("有没有异常我都要执行")
f.close()异常的传递性
def func1():
print("func1 开始执行")
num = 1 / 0
print("func1 结束执行")
def func2():
print("func2 开始执行")
func1()
print("func2 结束执行")
def main():
try:
func2()
except Exception as e:
print(f"出现异常了,异常为{e}")
main()2.模块
2.1.模块的定义和导入
模块的定义:模块就是一个python文件,里面有类,函数,变量等,可以拿过来用
模块的导入:
# 方法一模块的导入
import time # 导入python内置的time模块(time.py文件)
print("你好")
time.sleep(5) # time模块中的sleep函数
print("我好")
# 方法二模块的导入,针对某一个功能
from time import sleep
print("你好")
sleep(5)
print("我好")
# 使用*导入time模块的全部功能功能
from time import *
print("你好")
sleep(5)
print("我好")模块别名
import time as t # 将time模块换为t
t.sleep(5)
from time import sleep as s # 将time模块中的sleep函数换为s
s(5)
2.2.自定义模块
自定义模块,新建一个python文件,命名一个名字,并定义函数
if __name__ == '__main__':避免与主文件冲突,都调用sum(a, b)
__all__,导入指定的功能,形式为 __all__ = ['函数名']
# 自定义一个模块
# import_mo_kuai.py文件
# __all__ = ['sum2']
def sum1(a, b):
print(a + b)
def sum2(c, d):
print(c - d)
# __main__
if __name__ == '__main__': # 避免与主文件冲突,都调用sum(a, b)
sum1(1, 2)
if __name__ == '__main__': # 避免与主文件冲突,都调用sum(a, b)
sum2(1, 2)# 主函数调用模块
from import_mo_kuai import sum1
sum1(1, 2)
from import_mo_kuai import *
sum2(1, 2)3.包
3.1.包的定义
包就是一个包中有很多的模块,而模块就是里面有很多的功能函数
3.2.自定义包以及第三方包的下载
自定义python包,包就是一个文件夹,在该文件夹下包含一个_init_.py文件,该文件夹可包含多个模块文件。

第三方包的下载:
方法一:在最下面找到终端,直接下载,pip install + 包名
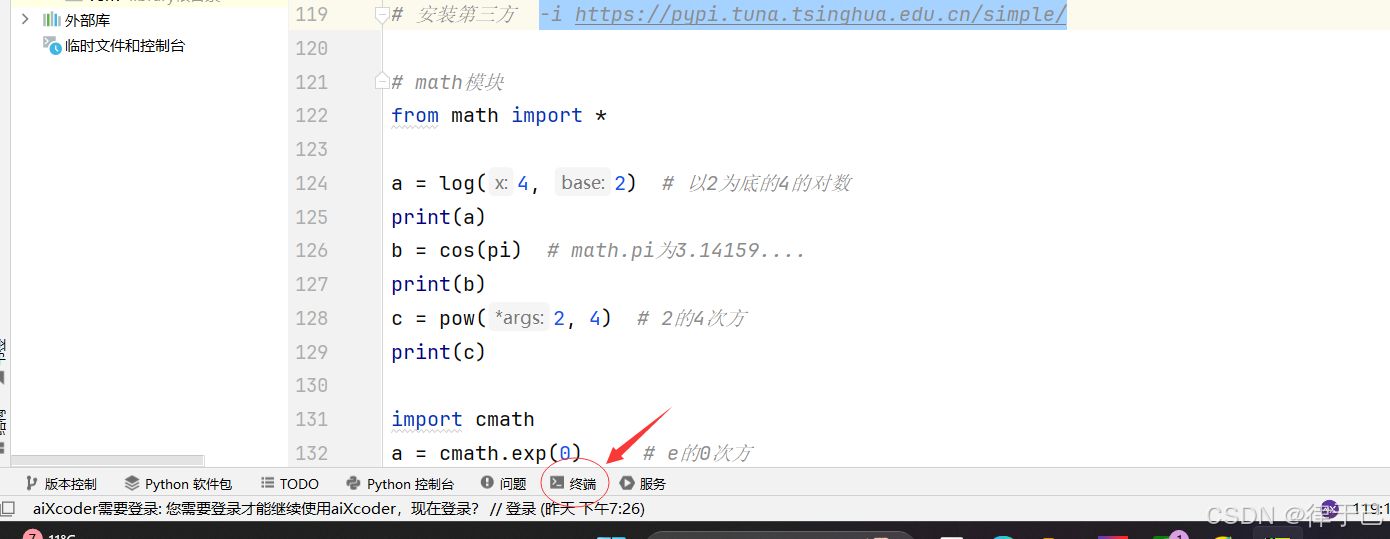
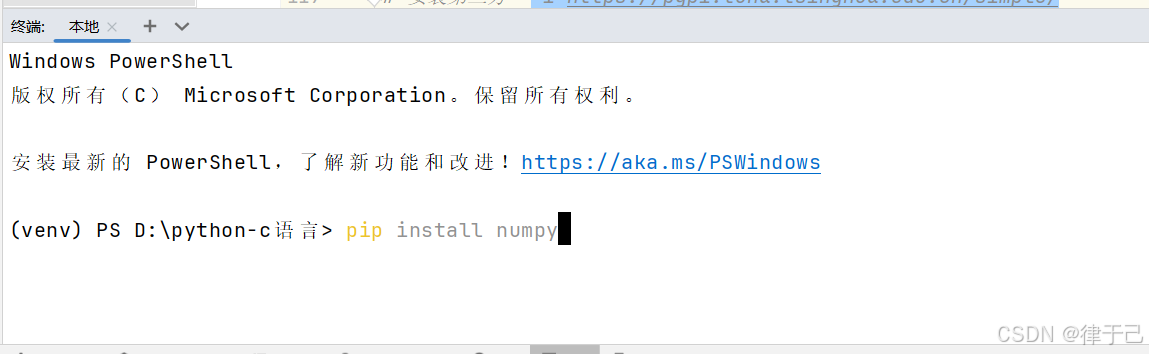
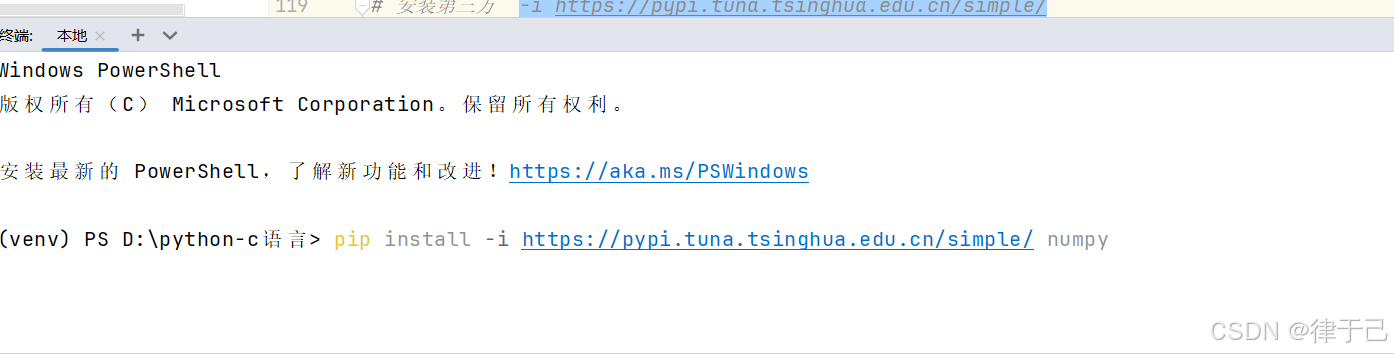
中间加入镜像源6. "-i https://pypi.tuna.tsinghua.edu.cn/simple/ "可以加速下载
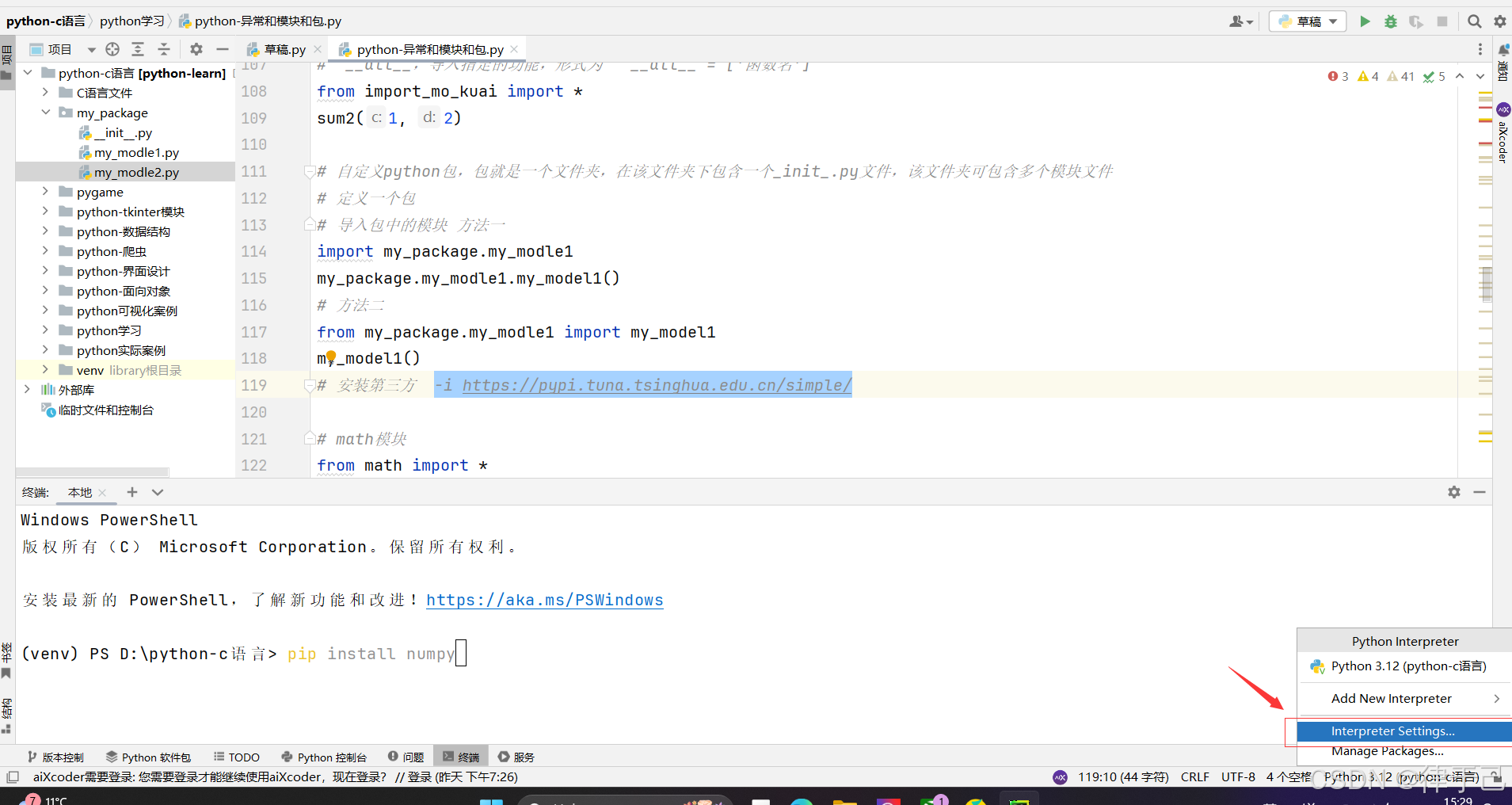
方法二:pychram内部直接下载
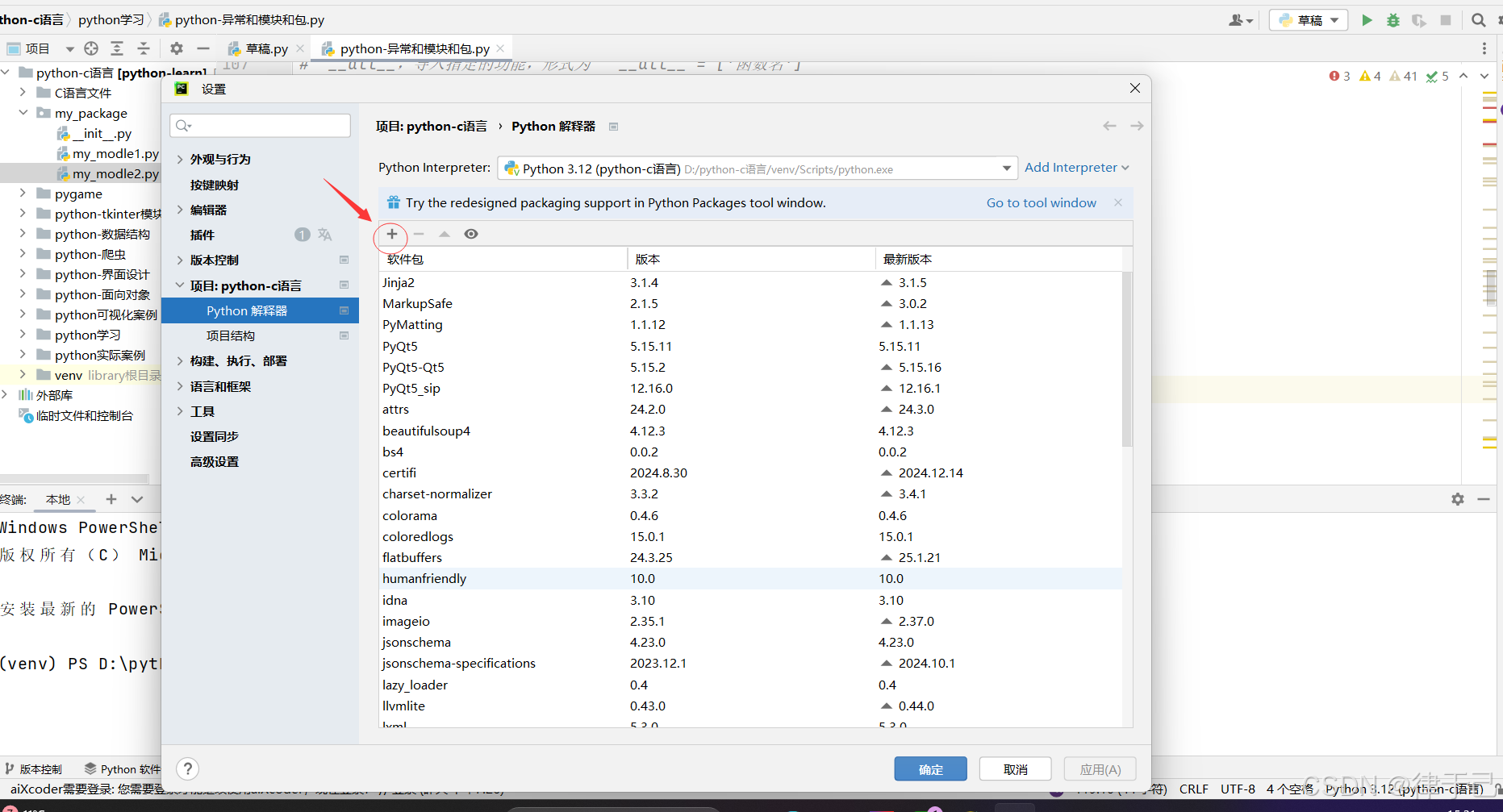
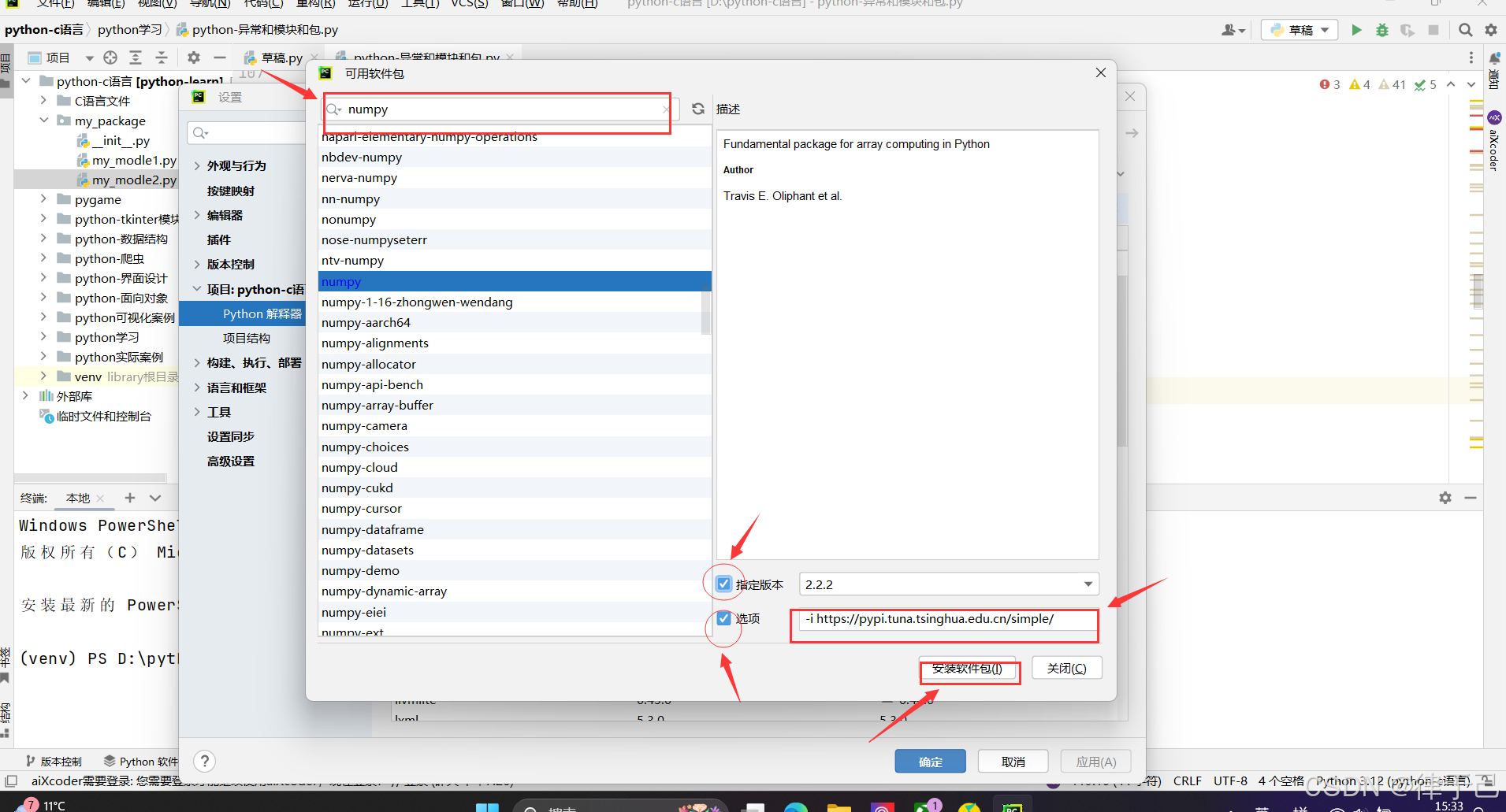
方法三:cmd终端也可以下载
4.常见的模块
math模块
from math import *
a = log(4, 2) # 以2为底的4的对数
b = cos(pi) # math.pi为3.14159....
c = pow(2, 4) # 2的4次方
cmath模块
import cmath
a = cmath.exp(0) # e的0次方
print(cmath.log10(1)) # 以10为第的对数
print(cmath.sqrt(1)) # 开平方datetime模块
# 获取现在的日期--年月日
import datetime
d = datetime.date.today().strftime('%Y-%m-%d %H:%M:%S') # strftime使日期格式化
print(d)
# d = 2025-01-23 00:00:00
# 获取更精准的日期
date = datetime.datetime.now()
print(date)
# date = 2025-01-23 15:40:29.496505calendar模块
# 打印出某年某月的日历
import calendar
c = calendar.month(2025, 1)
print(c)
# 输出为:
# January 2025
# Mo Tu We Th Fr Sa Su
# 1 2 3 4 5
# 6 7 8 9 10 11 12
# 13 14 15 16 17 18 19
# 20 21 22 23 24 25 26
# 27 28 29 30 31
# 打印某年的日历
import calendar
c = calendar.calendar(2025)
print(c)qrcode模块(生成二维码)
# 生成二维码
import qrcode
data = '及你太美' # 二维码中的数据
img = qrcode.make(data)
img.save("test1.png") # 生成二维码图片
import qrcode
data = "www.baidu.com" # 数据是一个网站
img = qrcode.make(data)
img.save("test2.png")
# 扫描二维码之后会直接跳转到该网站三.类与对象
1.类的定义
定义一个类:
class关键字 + 类名:
成员
创建一个对象:
对象名 = 类名()
class Student:
name = None # 记录学生姓名
gender = None # 记录性别
country = None
Native_place = None # 记录籍贯
age = None
# 创建一个对象
stu_1 = Student()
# 对象的属性进行赋值
stu_1.name = '周杰伦'
stu_1.age = 18
stu_1.gender = '男'
stu_1.Native_place = '四川省'
stu_1.country = '中国'
# 输出
print(stu_1.gender) # 输出性别2.类的构造方法
构造方法的名称: __init__
class Student:
name = None
age = None
tel = None
# 初始化成员变量
def __init__(self, name, age, num):
self.name = name
self.age = age
self.tel = num
print("创建了一个类对象")
stu = Student('zx', 18, 188521211)3.类内置的方法
class student:
def __init__(self, name, age):
self.name = name
self.age = age
# __str__ 魔术方法 ,转化为字符串
def __str__(self):
return f"student类对象,name:{self.name},age:{self.age}"
# __lt__ 魔术方法,小于符号比较
def __lt__(self, other):
return self.age < other.age
# __le__ 魔术方法,小于等于比较
def __le__(self, other):
return self.age <= other.age
# 比较两个是否相等,__eq__
def __eq__(self, other):
return self.name == other.name
stu1 = student('周杰伦', '18')
stu2 = student('周杰伦', '21')
print(stu1) # 输出为:student类对象,name:周杰伦,age:18
print(stu1 < stu2) # 输出为:True
print(stu1 >= stu2) # 输出为:False
print(stu1 == stu2) # 输出为:True4.封装
类的私有成员 ,在成员变量和成员方法前面加上两个下划线就是,例:__成员
私有变量和私有方法一般都是用于成员方法中的
class phone:
__tel = 9 # 私有变量
def __telphone(self): # 私有方法
print("低储能,不能")
def call_by_5g(self):
if self.__tel >= 10:
print("开启5g,可以正常通话")
else:
self.__telphone()
phone = phone()
# print(phone.tel) 私有成员不能被使用
phone.call_by_5g()5.继承
单继承,写法————class 类名(父类名)
class phone:
def __init__(self, id, name):
id = id
name = name
def call_by_4g(self):
print("4g手机")
class phone5g(phone):
face_id = '10004' # 面部识别编码
def call_by_5g(self):
print("5g手机")
phone = phone5g("10086", "5g手机")
print(phone.face_id)
多继承,写法————class 类名(父类名,父类名,父类名,......)
如有同名的成员,先继承的优先级大于后继承,
不想写新的成员变量和方法是,避免语法错误就需要写个 pass
class phone: # 父类
ID = '19988411' # 编号
producer = 'HM' # 产地
def call_by_4g(self):
print("4g手机")
class green: # 父类
ID = '46658'
producer = 'SC'
def green_color(self):
print("red")
class CPU: # 父类
type_phone = 'ios'
def color(self):
print("pink")
class new_phone(phone, green, CPU):
pass
phone1 = new_phone()
print(phone1.ID)
定义子类,复写父类成员,以及如何在子类中调用父类成员
class phone: # 父类
ID = '19988411' # 编号
producer = 'HM' # 产地
def call_by_4g(self):
print("4g手机")
class smart_phone(phone):
ID = '10086' # 复写
def call_by_4g(self): # 复写
print("5g手机")
print("CPU单核模式")
# 在子类中,调用父类成员
# 方式1,直接父类名.成员
print(phone.ID)
phone.call_by_4g(self)
# 方式2,super().成员
print(super().ID)
super().call_by_4g()
phone1 = smart_phone()
phone1.call_by_4g()6.类型注解
6.1.变量的类型注解
格式: 变量名:变量类型 = 值
var_1: int = 10
var_2: str = 'qwer'
var_3: bool = True
6.2.类对象的注解
class Student:
name = None
age = None
gender = None
def __init__(self, age, name, gender):
age = age
name = name
gender = gender
stu: Student = Student(18, "cxk", "男")6.3.数据容器的注解
格式都大致一样
# 数据容器
my_list: list = [1, 2, 3]
my_dict: dict = {'qwe': 666}
# 容器类型详细注解
my_list1: list[int] = [1, 2, 3]
my_dict1: dict[str, int] = {'qwr': 444}6.4.在注释中进行类型注解
import random
a = random.randint(1, 10) # type: int
b = json.loads('{"name": 6}') # type: dict[str, str]
def func():
return 10
c = func() # type: int6.5.函数的注解
# 对形参进行注解
def add(x: int, y: int):
return x + y
add(1, 2)
# 对返回值注解
def func(data: list) -> list:
data.append(1)
return data
func([1, 2, 3])
6.6.Union联合类型注解
from typing import Union
my_list2 = list[Union[str, int]] = [1, 2, 'zx', 'heima']
def func(data: Union[int, str]) -> Union[int, str]:
pass
func(1)7.抽象类
如果说,类是对一堆对象共同内容的抽取,那么抽象类就是对一堆类共同内容的抽取,包括:属性和方法。
演示抽象类
class AC:
def cool_wind(self):
"""制冷"""
pass
def hot_wind(self):
"""制热"""
pass
def swing_l_r(self):
"""左右摆风"""
pass
class Midea_AC(AC):
def cool_wind(self):
print("美的空调制冷")
def hot_wind(self):
print("美的空调制热")
def swing_l_r(self):
print("美的")
class Gree_AC(AC):
def cool_wind(self):
print("格力空调制冷")
def hot_wind(self):
print("格力空调制热")
def swing_l_r(self):
print("格力")
def make_cool(ac: AC):
ac.cool_wind()
midea_cool = Midea_AC()
gree_cool = Gree_AC()
make_cool(midea_cool)
make_cool(gree_cool)8.文件操作
8.1.打开文件
第一个是文件地址,‘r’是读取操作,第三是编码
f = open("D:\文本.txt", "r", encoding='UTF-8')8.2.读取文件
读取方法--read()
f = open("D:\文本.txt", "r", encoding='UTF-8')
f.read()读取方法--readlines()
f = open("D:\文本.txt", "r", encoding='UTF-8')
list1 = f.readlines() # 读取文件的全部行,装入列表中
print(list1) # read()已经将内容读取完,所以list1为空读取方法--readline()
f = open("D:\文本.txt", "r", encoding='UTF-8')
line1 = f.readline() # 每次读取一行
print(line1)
for i in f:
print(i) # 输出每一行的内容8.3.关闭文件
f.close()
with open操作文件,也是打开文件操作, 会自动关闭文件
with open("D:\文本.txt", "r", encoding='UTF-8') as file:
for i in file:
print(i)8.4.文件的写进操作
如果文件不存在,”w“会创造文件,“a”模式也是一样
f1 = open("D:\pyhthon.txt", "w", encoding='UTF-8')
f1.write("我喜欢你!") # 将写入的存入内存
f1.flush() # 将内存的写进入文件中
f1.close()
# 文件的追加写入操作
f2 = open("D:\pyhthon.txt", "a", encoding='UTF-8')
f2.write("你的名字")
f2.flush()
f2.close()文件案例,从f1文件中取出内容写进f2文件中
f1 = open("D:\pyhthon文件.txt", "r", encoding='UTF-8')
f2 = open("D:\pyhthon新的文件.txt", "w", encoding='UTF-8')
for line in f1:
line = line.strip() # 将每行换行处理掉
if line.split(",")[2] == "否": # 以逗号为分割,分割为列表,并判断
continue
f2.write(line) # 写进新的文件
f2.write("\n")
f1.close()
f2.close()四.tkinter模块
1.基础知识
import tkinter as tk
from tkinter import messagebox
root = tk.Tk() # 这个方法的作用就是创建一个窗口
root.title("演示窗口")
root.geometry("600x400+500+200") # (宽度x高度)+(x轴+y轴), 设置宽高以及窗口在屏幕的位置
# 按键1
btn1 = tk.Button(root) # 将我们创建的btn1按钮放到这个窗口上面
btn1["text"] = "点击" # 给按钮取一个名称
btn1.pack()
# grid_info() 查看组件默认的参数
# btn1.grid()
# print(btn1.grid_info())
# 创建点击按钮事件的弹窗,先导入messagebox,这个必须单独导入
def test(e):
messagebox.showinfo("窗口名称", "点击成功")
# 现在有了按钮,有了方法,我想要做的是一点击按钮,就执行这个方法,那么就需要将按钮和方法进行绑定
btn1.bind("<Button-1>", test) # 第一个参数为:按鼠标左键的事件 第二个参数为:要执行的方法的名字
root.mainloop() # 让窗口一直显示, 循环
2.组件分布及样式设置
import tkinter as tk
import tkinter.font as font
# place布局管理器
root = tk.Tk()
but1 = tk.Button(root, text="按键1")
but2 = tk.Button(root, text="按键2")
"""
x,y 组件左上角的绝对坐标(相当于窗口)
relx ,rely 组件左上角的坐标(相对于父容器)
width , height 组件的宽度和高度
relwidth , relheight 组件的宽度和高度(相对于父容器)
anchor 对齐方式,左对齐“w”,右对齐“e”,顶对齐“n”,底对齐“s”
"""
but1.place(relx=0.1, x=0, y=0, relwidth=0.1, relheight=0.1, anchor="n")
but2.place(relx=0.1, rely=0.1, x=0, y=0, relwidth=0.1, relheight=0.1, anchor="n")
# 组件文字字体、字号、字体粗细、颜色设置
'''
family:指定字体名称
size:指定字体大小
weight:指定字体的粗细程度
'''
font_1 = font.Font(family='Helvetica', size=15, weight='normal')
font_2 = font.Font(family='Arial', size=10, weight='bold')
# bg:背景颜色
# foreground:文字颜色
but3 = tk.Button(root, text="背景色", font=font_1, bg="LightSkyBlue")
but3.place(relx=0.1, rely=0.2, x=0, y=0, relwidth=0.1, relheight=0.1, anchor="n")
label1 = tk.Label(root, text="文字颜色", font=font_2, foreground="Orange")
label1.place(relx=0.2, rely=0.2, x=0, y=0, relwidth=0.1, relheight=0.1, anchor="n")
root.title('演示窗口')
root.geometry("600x400+500+200")
root.mainloop()
3.基本控件
import tkinter as tk
from tkinter import ttk
class GUI:
def __init__(self):
self.root = tk.Tk()
self.root.title("演示窗口")
self.root.geometry("500x200+1100+150")
self.interface()
def interface(self):
"""界面编写位置"""
# 文本显示_Label
self.Lable0 = tk.Label(self.root, text="文字显示")
self.Lable0.grid(row=0, colum=0)
# 按键显示
self.Button0 = tk.Button(self.root, text="按键显示")
self.Button0.grid(row=0, colum=0)
# 输入框显示_Entry
self.Entry0 = tk.Entry(self.root)
self.Entry0.grid(row=0, colum=0)
# 文本输入框显示_Text
# pack布局
self.w1 = tk.Text(self.root, width=80, height=10)
self.w1.pack(pady=0, padx=30)
# grid布局
self.w1 = tk.Text(self.root, width=80, height=10)
self.w1.grid(row=1, colum=0)
# 复选按钮_Checkbutton
self.Checkbutton01 = tk.Checkbutton(self.root, text="名称")
self.Checkbutton01.grid(row=0, colum=2)
# 单选按钮_Radiobutton
self.Radiobutton01 = tk.Radiobutton(self.root, text="名称")
self.Radiobutton01.grid(row=0, colum=2)
# 下拉选项框_Combobox
values = ['1', '2', '3', '4']
self.combobox = ttk.Combobox(
master=self.root, # 父容器
height=10, # 高度,下拉显示的条目数量
width=20, # 宽度
state='', # 设置状态 normal(可选可输入)、readonly(只可选)、 disabled(禁止输入选择)
cursor='arrow', # 鼠标移动时样式 arrow, circle, cross, plus...
font=('', 15), # 字体、字号
textvariable='', # 通过StringVar设置可改变的值
values=values, # 设置下拉框的选项
)
self.combobox.grid(padx=150)
if __name__ == '_main_':
a = GUI()
a.root.mainloop()
4.菜单--主菜单,子菜单
import tkinter as tk
from tkinter import Menu
class GUI:
def __init__(self):
self.root = tk.Tk()
self.root.title("演示窗口")
self.root.geometry("500x200+1100+150")
# 创建主菜单实例
self.menubar = Menu(self.root)
# 显示菜单,将root根窗口的主菜单设置为menu
self.root.config(menu=self.menubar)
self.interface()
def interface(self):
"""界面编写位置"""
# 在menubar上设置菜单名,并关联一系列子菜单
self.menubar.add_cascade(label="文件", menu=self.papers())
self.menubar.add_cascade(label="查看", menu=self.papers())
def papers(self):
"""
fmenu = Menu(self.menubar): 创建子菜单实例
tearoff=1: 1的话多了一个虚线,如果点击的话就会发现,这个菜单框可以独立出来显示
fmenu.add_separator(): 添加分隔符"--------":
"""
fmenu = Menu(self.menubar, tearoff=0)
# 创建d'dan五.数据可视化
1.json数据
Json数据和python字典的相互转换
import json
# 列表里的元素都是字典,将其转换为json
data = [{"name": "王大锤", "age": "18"}, {"name": "张子瑜", "age": "19"}, {"name": "周兴航", "age": "20"}]
# dumps为转换为json字符串的功能函数
json_str = json.dumps(data, ensure_ascii=False) # 确保中文转换过去还是中文
# 字典转换为json字符串
d = {"name": "周杰伦", "address": "北京"}
json_str = json.dumps(d, ensure_ascii=False) # 确保中文转换过去还是中文
# loads为json字符串转换为python数据类型的功能函数
str1 = '[{"name": "王大锤", "age": "18"}, {"name": "张子瑜", "age": "19"}, {"name": "周兴航", "age": "20"}]'
l1 = json.loads(str1)
str2 = '{"name": "周杰伦", "address": "北京"}'
d2 = json.loads(str2)
2.pyecharts入门
pyecharts包详细的使用方法在这简介 - pyecharts - A Python Echarts Plotting Library built with love.
2.1.折线图案例
导包,导入pyecharts包中的Line功能函数,对于下面的全局配置项 TitleOpts(), LegendOpts(), ToolboxOpts(),VisualMapOpts(),LabelOpts(),还需导入这些
from pyecharts.charts import Line
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts, LabelOpts得到折线图对象
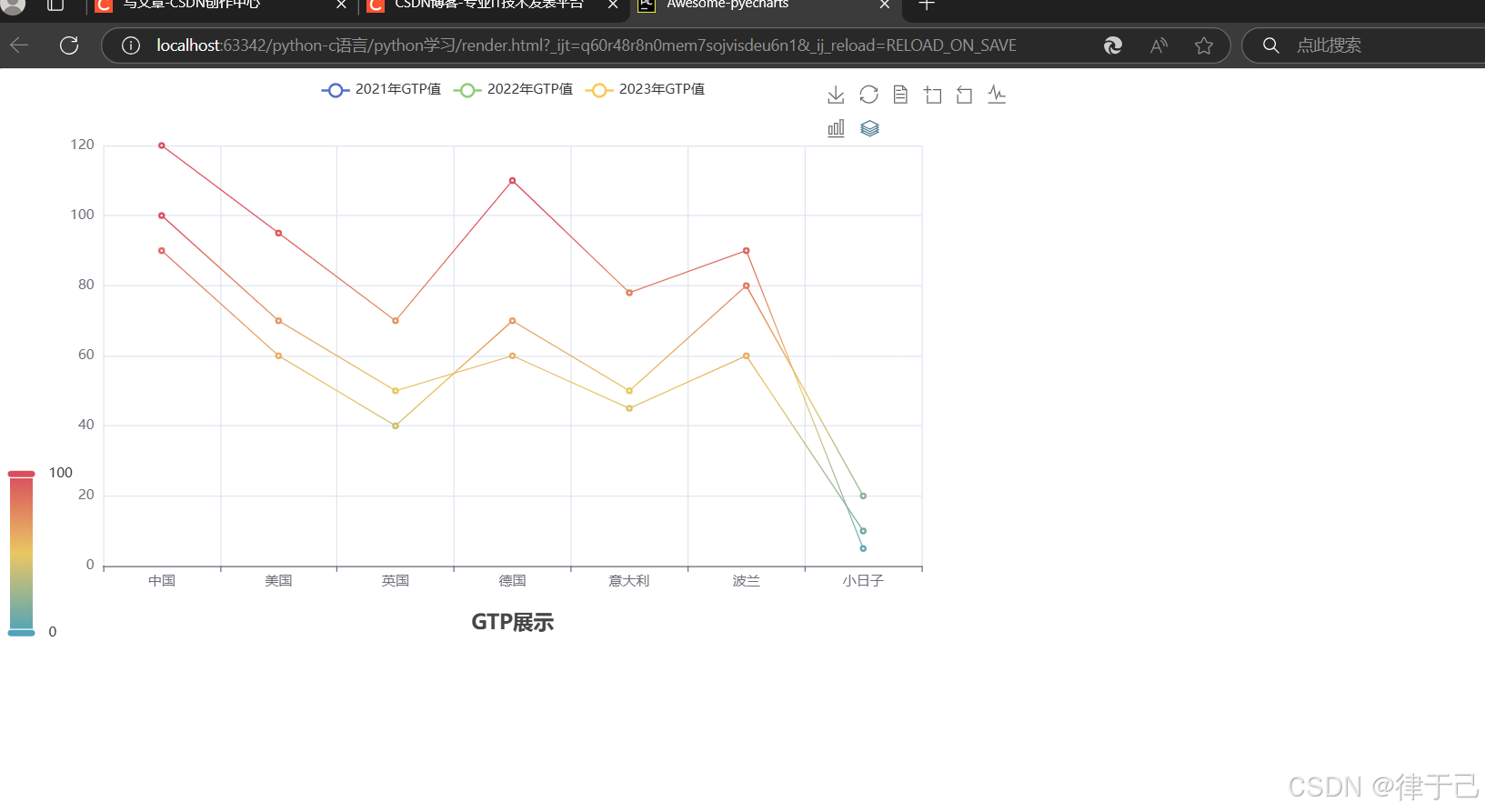
line = Line()给折线图添加x轴的数据,y轴的数据
line.add_xaxis(["中国", "美国", "英国", "德国", "意大利", "波兰", "小日子"])
line.add_yaxis("2021年GTP值", [100, 70, 50, 60, 45, 60, 10], label_opts=LabelOpts(is_show=False))
line.add_yaxis("2022年GTP值", [90, 60, 40, 70, 50, 80, 20], label_opts=LabelOpts(is_show=False))
line.add_yaxis("2023年GTP值", [120, 95, 70, 110, 78, 90, 5], label_opts=LabelOpts(is_show=False))设置全局配置项set_global_opts来设置
注意:pos_left表示title靠近左边有多元, pos_bottom表示距离底部只有1%的距离
line.set_global_opts(
title_opts=TitleOpts(title="GTP展示", pos_left="center", pos_bottom="1%"), # 按ctrl+p可看见传入的参数
legend_opts=LegendOpts(is_show=True),
toolbox_opts=ToolboxOpts(is_show=True),
visualmap_opts=VisualMapOpts(is_show=True),
)
通过render方法,将代码生成图像
line.render("render.html")点击运行之后,在目录路径下会生成一个render.html文件
点击图中提示的地方
就可以看到折线图了
2.2.地图数据可视化案例
1.导包,导入pyecharts包下的charts模块中的Map方法,以及全局设置的模块方法,json包
import json
from pyecharts.charts import Map
from pyecharts.options import *2.文件操作,将存有数据的文件转换为列表
# 读文件
f = open("D:\python文件\河南省各地疫情情况.txt", "r", encoding="UTF-8")
data1 = f.read()
# 关闭文件
f.close()
# Json数据转换为python列表
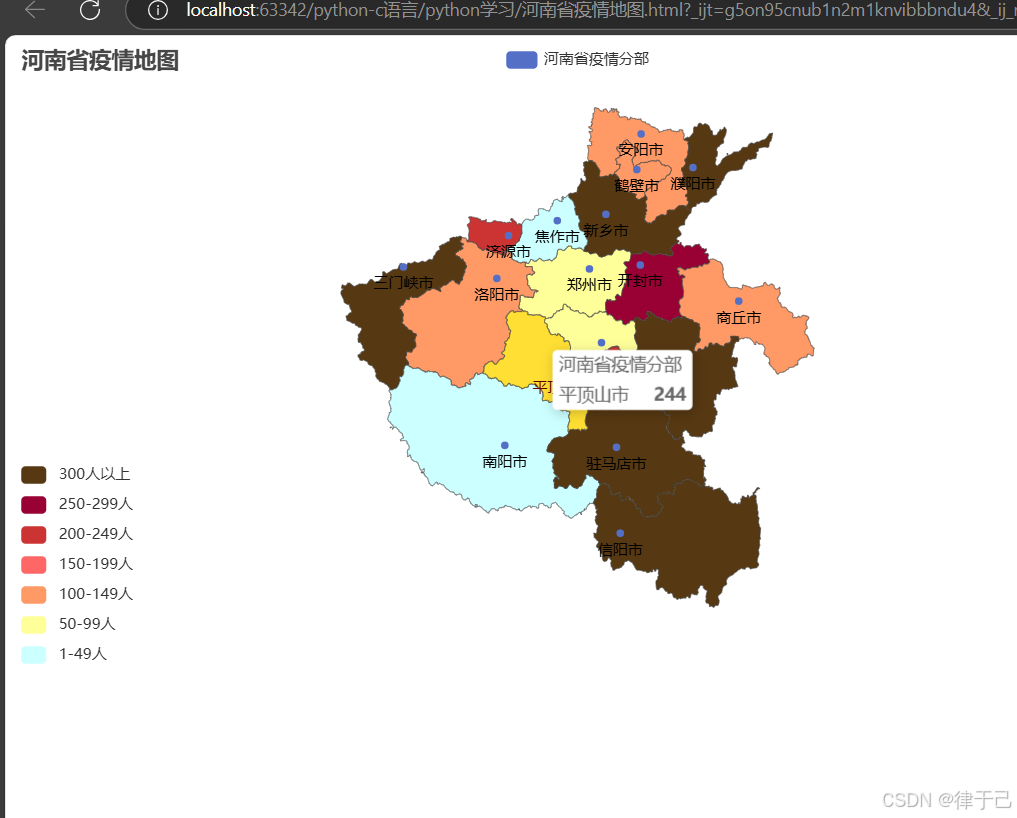
data1_list = json.loads(data1)3.构建地图对象
map1 = Map()
map1.add("河南省疫情分部", data1_list, "河南")
# 给地图对象添加信息4.设置全局选项
map1.set_global_opts(
title_opts=TitleOpts(title="河南省疫情地图"),
visualmap_opts=VisualMapOpts(
is_show=True,
is_piecewise=True,
pieces=[
{"min": 1, "max": 49, "label": "1-49人", "color": "#CCFFFF"},
# min和max为范围,label为显示的标签,#CCFFFF表示颜色
{"min": 50, "max": 99, "label": "50-99人", "color": "#FFFF99"},
{"min": 100, "max": 149, "label": "100-149人", "color": "#FF9966"},
{"min": 150, "max": 199, "label": "150-199人", "color": "#FF6666"},
{"min": 200, "max": 249, "label": "200-249人", "color": "#CC3333"},
{"min": 250, "max": 299, "label": "250-299人", "color": "#990033"},
{"min": 300, "label": "300人以上", "color": "#563812"},
]
)
)
5.绘图
map1.render("河南省疫情地图.html")运行之后会生成一个html文件,按照2.1.案例一样的方法打开,结果如下:
2.3.动态柱状图绘制
里面用到的数据文件可以到全球GPT国家网站寻找
1.导包,柱状图需要导入Bar模块
# 柱状图Bar模块,时间轴Timeline模块
from pyecharts.charts import Bar, Timeline
from pyecharts.options import *
from pyecharts.globals import ThemeType2.文件操作
本案例用到的数据是这样的,有很多很多数据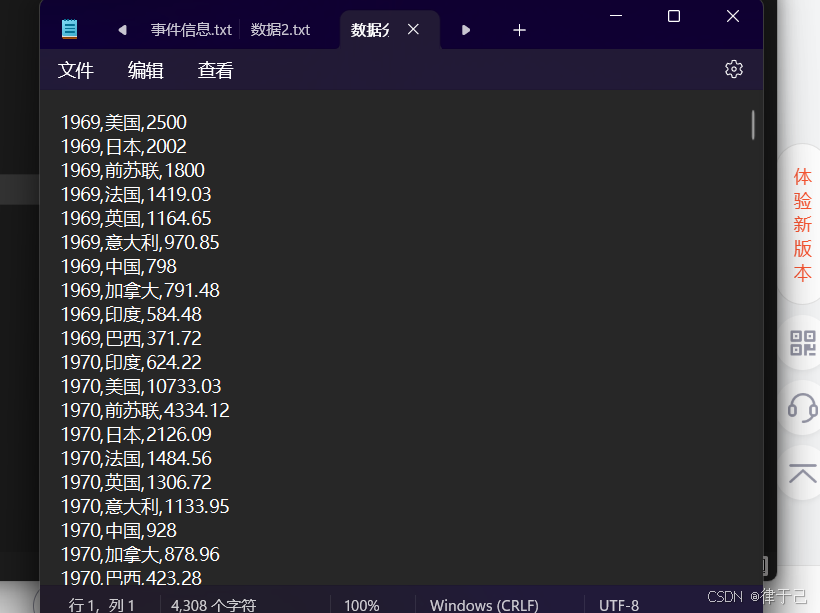
读取数据
# 读取数据
f = open("D:\pyhthon文件例子\空文件.txt", "r", encoding="UTF-8")
data_line = f.readlines() # 读到所有行数据
# 关闭文件
f.close()3.数据转化为固定格式
#将数据转换为字典格式,格式为:
{年份:[[国家, gtp],[国家, gtp]...... ], 年份:[[国家, gtp],[国家, gtp]...... ],}
# 先定义一个字典对象
data_dict = {}
for i in data_line:
line = i.strip('\n')
# print(line)
year = int(line.split(",")[0]) # 年份
country = line.split(",")[1] # 国家
gtp = float(line.split(",")[2])
# 如何判断字典里有没有指定的key呢
try:
data_dict[year].append([country, gtp])
except KeyError:
data_dict[year] = []
data_dict[year].append([country, gtp])
4.创建时间线对象
timeline = Timeline({"theme": ThemeType.LIGHT}) # 设置主题颜色
5.排序时间,以及构建柱状图对象
因为字典的key顺序是混乱的
sorted_year_list = sorted(data_dict.keys())
for year in sorted_year_list:
data_dict[year].sort(key=lambda element: element[1], reverse=True) # 对GTP从大到小排序
# 取出本年份GTP前八的国家
year_data = data_dict[year][0:8]
x_data = [] # x轴数据
y_data = [] # y轴数据
for country_gtp in year_data:
x_data.append(country_gtp[0]) # x轴添加国家
y_data.append(country_gtp[1]) # y轴添加gtp
# 构建柱状图
bar = Bar()
x_data.reverse() # 将数据反转,以便于最高的在最上面
y_data.reverse() # 一样
bar.add_xaxis(x_data)
bar.add_yaxis("GTP(亿)", y_data, label_opts=LabelOpts(position="right"))
# 反转x,y轴
bar.reversal_axis()
# 设置每一年的图标的标题
bar.set_global_opts(
title_opts=TitleOpts(title=f"{year}年全球前8GTP数据")
)
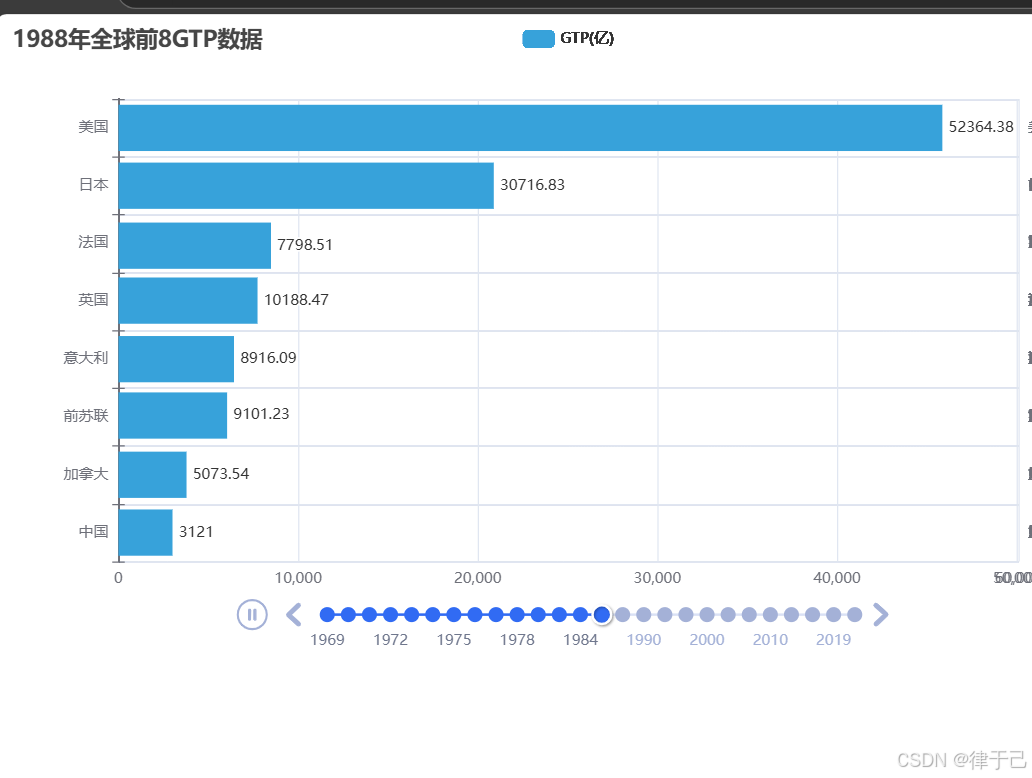
timeline.add(bar, str(year))6.设置时间线自动播放
timeline.add_schema(
play_interval=500,
is_timeline_show=True,
is_auto_play=True,
is_loop_play=False # 是否循环播放
)7.绘图
timeline.render("1969-2021年全球GTP前8国家.html")最后的结果就是一个会自动播放的柱状图
六.最后
python还有很多有意思的模块与功能,
比如可以写爬虫,写web,数据库开发,小游戏开发(pygame包)等等。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









