






2.1Hadoop的限制
Hadoop只能执行批量处理,并且只能以顺序的方式访问数据,导致随机访问的效率较低。
2.2HBase的存储机制
HBase可以存储海量数据,并且以随机方式访问数据。
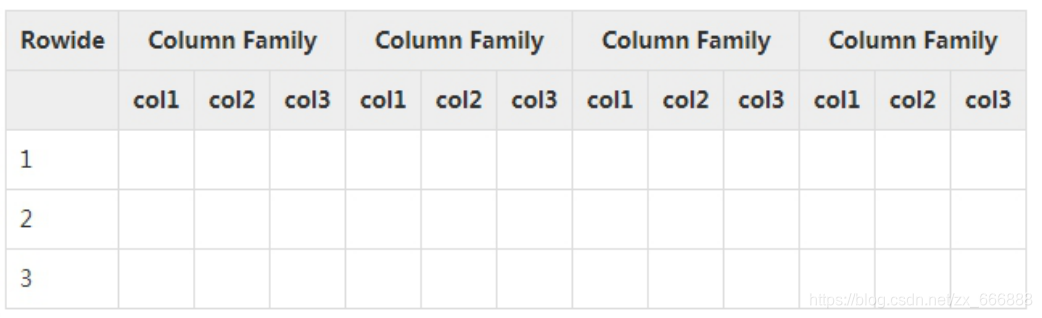
HBase是一个分布式的面向列的数据库,在表中由行进行排序。在创建表的时候就指定列族,定义列的时候以列族:列名键值对的形式定义。一个表有多个列族,每个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格即每个列都有具体的时间戳。
在HBase中:
- 表是行的集合
- 行是列族的集合
- 列族是列的集合
- 列是键值对的结合
下面是表模式的例子

















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









