







原理
一、HBase物理存储机制
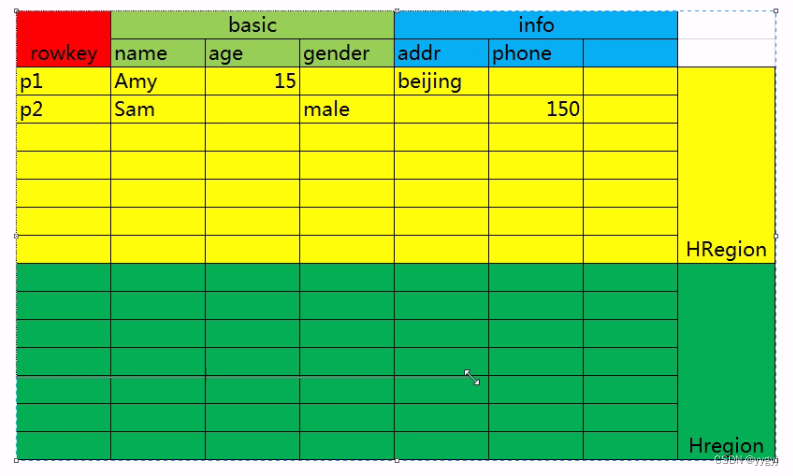
1.在HBase中,从行键的方向上将一个表划分为一个或者多个HRegion
2.每一个HRegion会存储在不同的节点(HRegionServer)上
3.因为HBase会对行键进行字典序排序,所以每一个HRegion所包含的数据是不重合的
4.每一个HRegion记录当前HRegion的起始行键和结束行键(范围锁定),这样做的目的是为了进行快速操作来避免整表查询
5.划分HRegion的目的是为了做到表的分布式存储,I并且能够有效的提高HBase的吞吐量
6.当某一个HRegion达到限定条件默认是10G,这个值可以调,范围1~20G)的时候,这个HRegion进行分裂,平均分为2个HRegion,其中一个HRegion会进行转移,转移到其他的HregionServer上
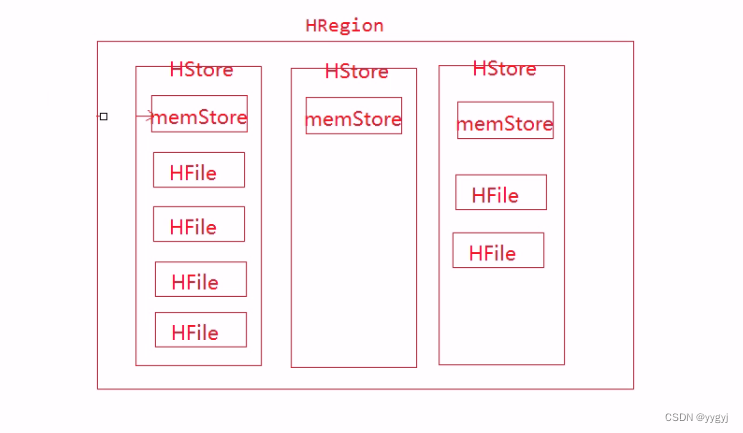
7. HBase在进行分布式存储的最小单位是HRegion,但是HBase存储的最小单位不是HRegion
8 HRegion中要包含1个到多个HStore,每一个列族对应一个HStore
9. HStore包含一个memStore(写缓存)以及0到多个HFile(StoreFile)

单独启动hmaster
[root@hadoop02 bin]# sh hbase-daemon.sh start master
[root@hadoop02 bin]# jps
3681 Jps
3593 HMaster
1579 QuorumPeerMain
二、HMaster
1.在HBase中不存在HMaster的单点故障,因为可以启动多个HMaster
2.HMaster存在2种状态: active(活跃)和backup(备份)。在HBase集群中,先在哪个节点
上启动HMaster,那么这个节点就是active HMaster,后启动的HMaster就是backup HMasterl
3.理论上,不限制HMaster的个数
4.当HBase启动的时候,会在zookeeper中注册/hbase节点。active HMaster
会在Zookeeper中注册一个临时节点/hbase/master节点,backup HMaster会在/hbase/backup-masters节点下注册临时节点
5.Active HMaster会监控Zookeeper中/hbase/backup-masters中的子节点的变化。如果/hbase/backup-masters中的子节点发生了变化,则说明有节点的加入或者移出
6.当Active HMaster宕机,那么Zookeeper中的临时节点也会消失,那么此时Zookeeper就直到Active节点挂掉,需要从Backup HMaster中选一个切换为Active状态
7. Active/Backup HMaster会向Zookeeper发送心跳维系这个节点的存活
8.Active HMaster默认是每隔180s发送一次心跳,实际开发中一般会将这个时间缩短为1min
9. Active HMaster和Backup HMaster要进行热备份,因此实际过程中,Backup HMaster的个数一般不超过2个
10. HMaster的职能:
a.对表结构进行管理(表的创建、删除、修改- create/drop/alter -ddl) ,而对于表中数据的操作(put/get/scan/delete - dml)不经过HMaster
b.管理HRegionServer【ddl】(zk管理【dml】—rs就是体现)
[zk: localhost:2181(CONNECTED) 2] ls /hbase
[replication, meta-region-server, rs, splitWAL, backup-masters, table-lock, region-in-transition, online-snapshot, master, running, recovering-regions, draining, namespace, hbaseid, table]
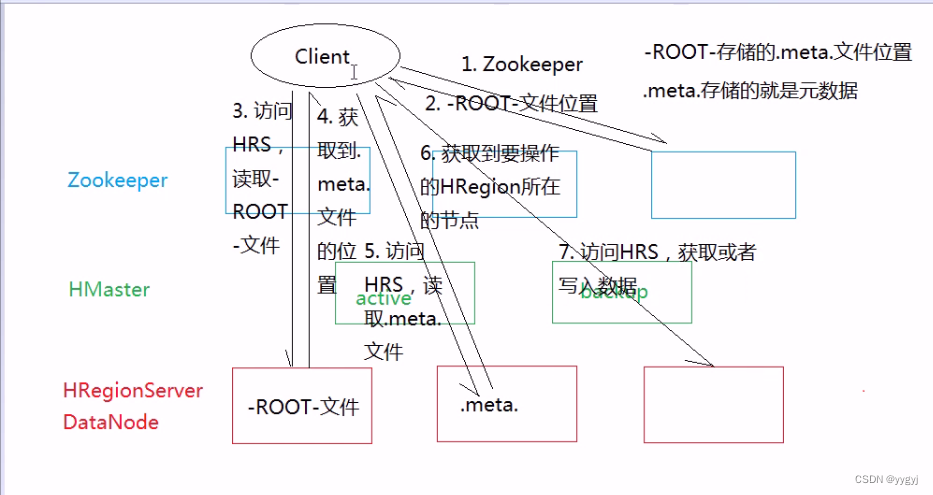
11.第一次读写流程:
a.在0.96版本以前:
b.在0.96版本开始:
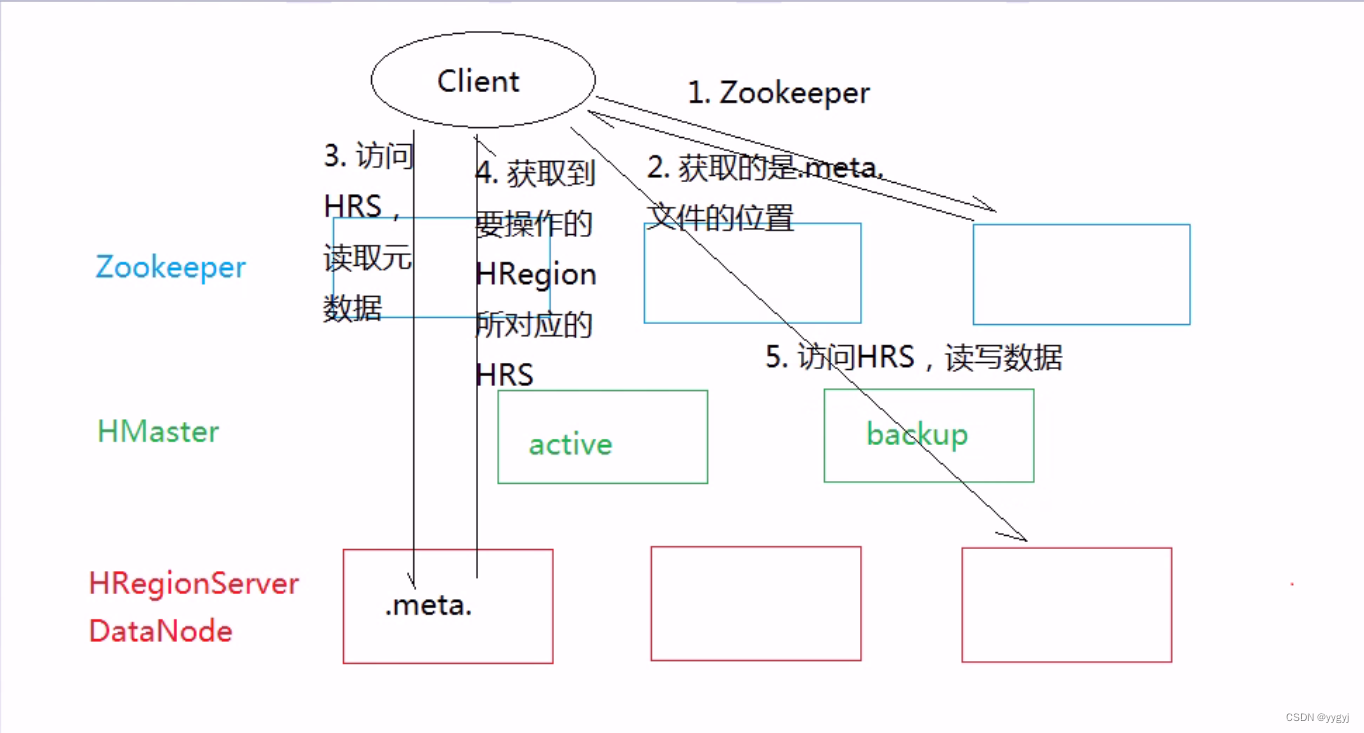
i、从0.96开始,为了提高读写效率减少访问次数,在客户端设置了缓存机制,存储HRegion所对应的HRegionServer。随着时间的延长,客户端的缓存会越来越多,读写效率也会越来越高
ii、这个过程中如果发生HRegion的分裂或者是客户端宕机,那么缓存机制就需要重新建立
12.元数据:
a.表名、列族名、名称空间等信息
b.每一个表对应的HRegion
c. HRegion所存在的HRegionServer
四、HRegionServer
1.HRegionServer不是存储HRegion而是管理HRegionr
2.在HBase官方文档中给出数据,每一个HRegionServer能够管理1000个HRegion
3.结构:
a. WAL - Write Ahead Log-改名为HLog
i.用于记录写操作。当HRegionServer收到写请求的时候,会先将操作记录到WAL中,然后再更新到memStore中。如果memStore满了,则冲刷到HFile中
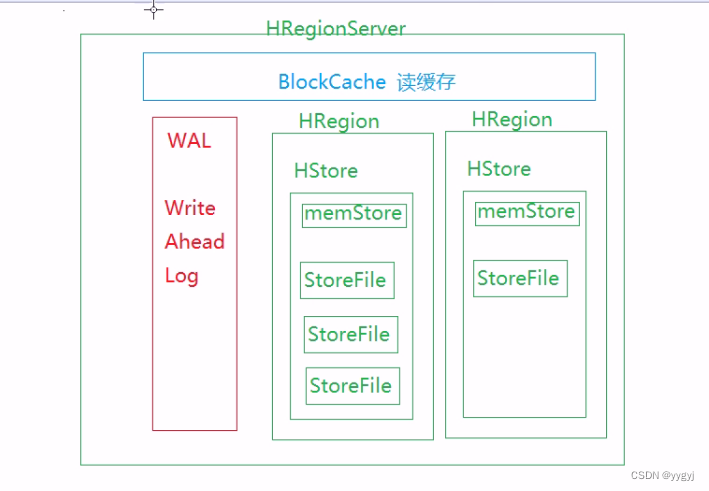
ii.在HBase0.92版本之前,WAL是串行写,从0.92版本开始,WAL运行进行并行写
b. BlockCache
i、在读取数据的时候,会把读取的数据放入读缓存中ii. BlockCache在进行缓存的时候采用的是"局部性"原理:
1)时间局部性:如果某一条数据被读取,那么这条数据再次被
读取的概率就比其他数据大,那么此时应该进行缓存
2)空间局部性:如果某一条数据被读取,那么与这条数据相邻的数据被读取的概率就比其他数据大,那么此时相邻的数据应该进行缓存。空间局部性在放的时候是以Data Block为单位向BlockCache中放
iii.采用局部性原理的目的是为了提高命中率
iv. BlockCache是维系在内存中,默认大小是128M
v.BlockCache采取了LRU策略:当BlockCache满了之后,会清除最长时间不用/使用次数最少的数据
c. HRegion -是HBase中存储数据的基本结构
i、一个HRegion包含1个到多个HStore,HStore的数量由列族数量决定个,每一个列族对应一个HStore
ii、每一个HStore中包含1个memStore以及0到多个storeFile/HFile
iii. memStore本身是一个写缓存,是维系在内存中,最大不超过128M。数据在memStore中会进行排序:行键字典序->列族名字典序-〉列名字典序->时间戳倒序,也就意味着在HFile中数据是局部有序-每一个HFile应该是有序的
流程
一、写流程
1.HRegionServer接收到写请求的时候,先将这个写请求记录到wAL中,然后再更新到memStore中,并且在这个memStore中进行排序
2.当memStore达到条件的时候会进行冲刷,产生HFile:
a.默认情况下,当memStore达到128M(通过
hbase.hregion.memstore.flush.size属性来调节,注意单位是字节)的时候,会讲行油冲刷
b.当WAL文件达到1G的时候,也会进行冲刷,并且此时会产生一个新的WAL文件
c.当一个HRegionServer中的所有的memStore的内存占到当前节点物理内存的35%的时候,也会进行冲刷,此时冲刷的时候,会先冲刷比较大的memStorel
3.在HBase提供了2种合并机制-针对HFile进行合并-默认的合并方式就是minor compact
a. minor compact:将当前HStore中多个小的HFile合并成几个大的HFile
b. major compact:将当前HStore中所有的HFile合并成一个HFile
4.在合并的时候,数据会进行整体的排序,而在排序过程中会去移除掉被标记为要删除的数据
5.Update:
数据无论在memStore中还是在HFile中,在进行更新的时候,都是进行追加写入,在合并的时候,会根据指定的版本,来舍弃过时的数据
Delete:
数据无论是memStore中还是在HFile中,在进行删除的时候,都是进行追加写入,在进行追加写入的时候,数据末尾会添加删除标记。在合并的时候,如果发现这个删除标记,则舍弃对应的数据
a. HFilev1:
i.包含了6部分:
-
Data Block:数据块。每一个DataBlock中存储1个Magic-魔数(魔数本身是一个随机数字,作用是用于进行校验,保证这个数据没有被改变过)和多个KeyValue数据。小的DataBlock有利于查询,大的Data Block适用于遍历scan
-
Meta Block:记录的元数据,但是这个信息在大多数的HFile中不存在
-
File Info:记录的HFile的描述信息
-
Data lndex:记录的是每一个Data Block的起始字节和结束字节
-
Meta lndex:记录的是每一个Meta Block的起始字节和结束字节
-
Trailer:固定4个字节大小,记录的File Info、Data lndex和Meta lndex的起始字节
ii.在读取HFile的时候,需要先读取Trailer,获取到Data Index的位置,然后从Data Index中去锁定每一个Data Block的位置,然后才能去读取Data Block
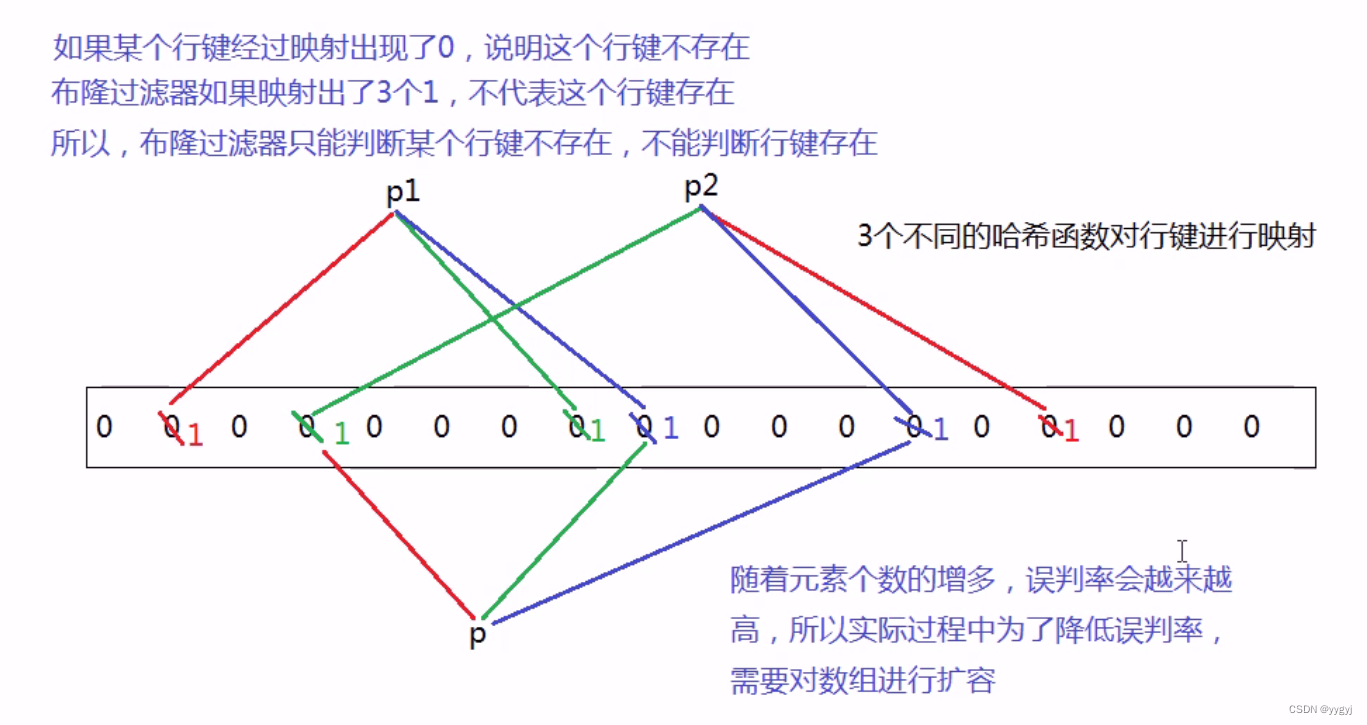
b. HFilev2版本中新添了Bloom Filter-布隆过滤器-HFile中的每一个行键都会经过布隆过滤器进行映射
二、HBase读流程
1.首先锁定对应的HRegionServer
2.先从BlockCache中读取,如果读不到,则读取memStore中的数据,如果也读不到,则从HFile读取
3.如果从HFile中读取,需要先筛选(范围+布隆过滤)符合条件的HFile4.在HFile中,会根据行键筛选出符合范围的Data Block
5.如果能够读取到,那么这条数据所在的Data Block会整体缓存到BlockCache中
注意:HBase是一个伪实时的数据库–-缓存
Redis
cassandra 非MS ----CAP WNR
hbase调优
1.调整data block
2.适当关闭数据块缓存
3.开启布隆过滤器
4.开启数据压缩
5.设置scan缓存
6.显示的指定列
7.关闭ResultScanner
8.使用批量读
9.关闭wal日志
10.允许自动冲刷
11.提前创建HRegion
12.调整ZooKeeper Session的有效时长
phoenix安装使用(利用phoenix类sql去操作hbase)
1.sql语句类sql
2.不稳定
3.关闭不方便
hbase优化,详细说明
1.调节数据块(data block)的大小HFile数据块大小可以在列族层次设置。这个数据块不同于之前谈到的HDFS数据块,其默认值是65536字节,或64KB。数据块索引存储每个HFile数据块的起始键。数据块大小的设置影响数据块索引的大小。数据块越小,索引越大,从而占用更大内存空间。同时加载进内存的数据块越小,随机查找性能更好。但是,如果需要更好的序列扫描性能,那么一次能够加载更多HFile数据进入内存更为合理,这意味着应该将数据块设置为更大的值。相应地,索引变小,将在随机读性能上付出更多的代价可以在表实例化时设置数据块大小:hbase(main):002:0> create ‘mytable’,{NAME => ‘colfam1’, BLOCKSIZE => ‘65536’}
2.适当时机关闭数据块缓存把数据放进读缓存,并不是一定能够提升性能。如果一个表或表的列族只被顺序化扫描访问或很少被访问,则Get或Scan操作花费时间长一点是可以接受的。在这种情况下,可以选择关闭列族的缓存关闭缓存的原因在于:如果只是执行很多顺序化扫描,会多次使用缓存,并且可能会滥用缓存,从而把应该放进缓存获得性能提升的数据给排挤出去,所以如果关闭缓存,不仅可以避免上述情况发生,而且可以让出更多缓存给其他表和同一表的其他列族使用。数据块缓存默认是打开的可以在新建表或更改表时关闭数据块缓存属性:hbase(main):002:0> create ‘mytable’, {NAME => ‘colfam1’, BLOCKCACHE => ‘false’}
3.开启布隆过滤器布隆过滤器(Bloom Filter)允许对存储在每个数据块的数据做一个反向测验。当查询某行时,先检查布隆过滤器,看看该行是否不在这个数据块。布隆过滤器要么确定回答该行不在,要么回答不知道。因此称之为反向测验。布隆过滤器也可以应用到行内的单元格上,当访问某列标识符时先使用同样的反向测验使用布隆过滤器也不是没有代价,相反,存储这个额外的索引层次占用额外的空间。布隆过滤器的占用空间大小随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以压榨整个系统的性能潜力可以在列族上打开布隆过滤器: create ‘mytable’, {NAME => ‘colfam1’, BLOOMFILTER => ‘ROWCOL’}布隆过滤器参数的默认值是NONE。另外,还有两个值:ROW表示行级布隆过滤器;ROWCOL表示列标识符级布隆过滤器。行级布隆过滤器在数据块中检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的空间开销高于ROW布隆过滤器。
4.开启数据压缩HFile可以被压缩并存放在HDFS上,这有助于节省硬盘I/O,但是读写数据时压缩和解压缩会抬高CPU利用率。压缩是表定义的一部分,可以在建表或模式改变时设定。除非确定压缩不会提升系统的性能,否则推荐打开表的压缩。只有在数据不能被压缩,或者因为某些原因服务器的CPU利用率有限制要求的情况下,有可能需要关闭压缩特性HBase可以使用多种压缩编码,包括LZO、SNAPPY和GZIP,LZO和SNAPPY是其中最流行的两种当建表时可以在列族上打开压缩:create ‘mytable’, {NAME => ‘colfam1’, COMPRESSION => ‘SNAPPY’}注意,数据只在硬盘上是压缩的,在内存中(MemStore或BlockCache)或在网络传输时是没有压缩的
5.设置Scan缓存HBase的Scan查询中可以设置缓存(客户端缓存),定义一次交互从服务器端传输到客户端的行数,设置方法是使用Scan类中setCaching()方法,这样能有效地减少服务器端和客户端的交互,更好地提升扫描查询的性能HTable table = new HTable(config, Bytes.toBytes(tableName));Scan scanner = new Scan();/* batch and caching /scanner.setBatch(0);scanner.setCaching(10000);ResultScanner rsScanner = table.getScanner(scanner);for (Result res : rsScanner) {final List list = res.list();String rk = null;StringBuilder sb = new StringBuilder();for (final KeyValue kv : list) {sb.append(Bytes.toStringBinary(kv.getValue()) + “,”);rk = getRealRowKey(kv);}if (sb.toString().length() > 0)sb.setLength(sb.toString().length() - 1);System.out.println(rk + “\t” + sb.toString());}rsScanner.close();
6.显式地指定列当使用Scan或Get来处理大量的行时,最好确定一下所需要的列。因为服务器端处理完的结果,需要通过网络传输到客户端,而且此时,传输的数据量成为瓶颈,如果能有效地过滤部分数据,使用更精确的需求,能够很大程度上减少网络I/O的花费,否则会造成很大的资源浪费。如果在查询中指定某列或者某几列,能够有效地减少网络传输量,在一定程度上提升查询性能。下面代码是使用Scan类中指定列的addColumn()方法HTable table = new HTable(config, Bytes.toBytes(tableName));Scan scanner = new Scan();/ 指定列 /scanner.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));ResultScanner rsScanner = table.getScanner(scanner);for (Result res : rsScanner) {final List list = res.list();String rk = null;StringBuilder sb = new StringBuilder();for (final KeyValue kv : list) {sb.append(Bytes.toStringBinary(kv.getValue()) + “,”);rk = getRealRowKey(kv);}if (sb.toString().length() > 0)sb.setLength(sb.toString().length() - 1);System.out.println(rk + “\t” + sb.toString());}rsScanner.close();
7.关闭ResultScannerResultScanner类用于存储服务端扫描的最终结果,可以通过遍历该类获取查询结果。但是,如果不关闭该类,可能会出现服务端在一段时间内一直保存连接,资源无法释放,从而导致服务器端某些资源的不可用,还有可能引发RegionServer的其他问题。所以在使用完该类之后,需要执行关闭操作。这一点与JDBC操作MySQL类似,需要关闭连接。代码的最后一行rsScanner.close()就是执行关闭ResultScanner。
8.使用批量读通过调用HTable.get(Get)方法可以根据一个指定的行键获取HBase表中的一行记录。同样HBase提供了另一个方法,通过调用HTable.get(List)方法可以根据一个指定的行键列表,批量获取多行记录。使用该方法可以在服务器端执行完批量查询后返回结果,降低网络传输的速度,节省网络I/O开销,对于数据实时性要求高且网络传输RTT高的场景,能带来明显的性能提升。
9.使用批量写通过调用HTable.put(Put)方法可以将一个指定的行键记录写入HBase,同样HBase提供了另一个方法,通过调用HTable.put(List)方法可以将指定的多个行键批量写入。这样做的好处是批量执行,减少网络I/O开销。
10.关闭写WAL日志在默认情况下,为了保证系统的高可用性,写WAL日志是开启状态。写WAL开启或者关闭,在一定程度上确实会对系统性能产生很大影响,根据HBase内部设计,WAL是规避数据丢失风险的一种补偿机制,如果应用可以容忍一定的数据丢失的风险,可以尝试在更新数据时,关闭写WAL。该方法存在的风险是,当RegionServer宕机时,可能写入的数据会出现丢失的情况,且无法恢复。关闭写WAL操作通过Put类中的writeToWAL()设置。可以通过在代码中添加:put.setWriteToWAL(false);
11.设置AutoFlushHTable有一个属性是AutoFlush,该属性用于支持客户端的批量更新。该属性默认值是true,即客户端每收到一条数据,立刻发送到服务端。如果将该属性设置为false,当客户端提交Put请求时,将该请求在客户端缓存,直到数据达到某个阈值的容量时(该容量由参数hbase.client.write.buffer决定)或执行hbase.flushcommits()时,才向RegionServer提交请求。这种方式避免了每次跟服务端交互,采用批量提交的方式,所以更高效。但是,如果还没有达到该缓存而客户端崩溃,该部分数据将由于未发送到RegionServer而丢失。这对于有些零容忍的在线服务是不可接受的。所以,设置该参数的时候要慎重。可以在代码中添加:table.setAutoFlush(false);table.setWriteBufferSize(121024*1024);
12.预创建Region在HBase中创建表时,该表开始只有一个Region,插入该表的所有数据会保存在该Region中。随着数据量不断增加,当该Region大小达到一定阈值时,就会发生分裂(Region Splitting)操作。并且在这个表创建后相当长的一段时间内,针对该表的所有写操作总是集中在某一台或者少数几台机器上,这不仅仅造成局部磁盘和网络资源紧张,同时也是对整个集群资源的浪费。这个问题在初始化表,即批量导入原始数据的时候,特别明显。为了解决这个问题,可以使用预创建Region的方法Hbase内部提供了RegionSplitter工具:${HBASE_HOME}/bin/hbase org.apache.hadoop.hbase.util.RegionSplitter test2 HexStringSplit -c 10 -f cf1其中,test2是表名,HexStringSplit表示划分的算法,参数-c 10表示预创建10个Region,-f cf1表示创建一个名字为cf1的列族。
13.调整ZooKeeper Session的有效时长参数zookeeper.session.timeout用于定义连接ZooKeeper的Session的有效时长,这个默认值是180秒。这意味着一旦某个RegionServer宕机,HMaster至少需要180秒才能察觉到宕机,然后开始恢复。或者客户端读写过程中,如果服务端不能提供服务,客户端直到180秒后才能觉察到。在某些场景中,这样的时长可能对生产线业务来讲不能容忍,需要调整这个值此参数在HBase-site.xml中,

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









