






JAVA:
finally的作用:当try里面的代码没有异常的时候,会执行该try块对应的finally块,并继续执行finally之后的代码。当try里面的代码出现异常的时候,会执行该try块对应的catch块和finally块,且即使catch中有返回finally也是要执行。也就是先执行完finally中的语句,再返回catch中的return。
SLEEP WAIT 的区别
sleep和wait的区别有:
1,这两个方法来自不同的类分别是Thread和Object
2,最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3,wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在
任何地方使用
synchronized(x){
x.notify()
//或者wait()
}
4,sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
JAVA内存回收机制
Java 的内存管理就是对象的分配和释放问题。分配内存的方式多种多样,取决于该种语言的语法结构。但不论是哪一种语言的内存分配方式,最后都要返回所分配的内存块的起始地址,即返回一个指针到内存块的首地址。在Java 中所有对象都是在堆(Heap)中分配的,对象的创建通常都是采用new或者是反射的方式,但对象释放却有直接的手段,所以对象的回收都是由Java虚拟机通过垃圾收集器去完成的。这种收支两条线的方法确实简化了程序员的工作,但同时也加重了JVM的工作,这也是Java 程序运行速度较慢的原因之一。因为,GC 为了能够正确释放对象,GC 必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC 都需要进行监控。监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再
被引用。Java 使用有向图的方式进行内存管理,可以消除引用循环的问题,例如有三个对象,相互引用,只要它们和根进程不可达,那么GC 也是可以回收它们的。在Java 语言中,判断一块内存空间是否符合垃圾收集器收集标准的标准只有两个:一个是给对象赋予了空值null,以下再没有调用过,另一个是给对象赋予了新值,即重新分配了内存空间。
java的线程同步机制
由于同一进程的多个线程共享同一片存储空间,在带来方便的同时,也带来了访问冲突这个严重的问题。Java语言提供了专门机制以解决这种冲突,有效避免了同一个数据对象被多个线程同时访问。
需要明确的几个问题:
1) synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果 再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
2)无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
3)每个对象只有一个锁(lock)与之相关联。
4)实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
1.在方法中创建一个线程对象,重新线程的run()方法
- Thread thread1=new Thread(){
- @Override
- public void run() {
- while(true){
- try {
- Thread.sleep(500);
- System.out.println("<Runable-1>/t"+Thread.currentThread().getName());
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- };
- thread1.start();
数据库范式
5. 通俗地理解三个范式
通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解):
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余.
没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
第一范式
存在非主属性对码的部分依赖关系 R(A,B,C) AB是码 C是非主属性 B-->C B决定C C部分依赖于B
第一范式
定义:如果关系R 中所有属性的值域都是单纯域,那么关系模式R是第一范式的
那么符合第一模式的特点就有
1)有主关键字
2)主键不能为空,
3)主键不能重复,
4)字段不可以再分
第二范式
存在非主属性对码的传递性依赖 R(A,B,C) A是码 A -->B ,B-->C
定义:如果关系模式R是第一范式的,而且关系中每一个非主属性不部分依赖于主键,称R是第二范式的。
所以第二范式的主要任务就是
满足第一范式的前提下,消除部分函数依赖。
第三范式
不存在非主属性对码的传递性依赖以及部分性依赖 ,
StudyNo | Name | Sex | Email | bounsLevel | bouns
20040901 john Male kkkk@ee.net 优秀 $1000
20040902 mary famale kkk@fff.net 良 $600
这个完全满足了第二范式,但是bounsLevel和bouns存在传递依赖
更改为:
StudyNo | Name | Sex | Email | bouunsNo
20040901 john Male kkkk@ee.net 1
20040902 mary famale kkk@fff.net 2
bounsNo | bounsLevel | bouns
1 优秀 $1000
2 良 $600
这里我比较喜欢用bounsNo作为主键,
基于两个原因
1)不要用字符作为主键。可能有人说:如果我的等级一开始就用数值就代替呢?
2)但是如果等级名称更改了,不叫 1,2 ,3或优、良,这样就可以方便更改,所以我一般优先使用与业务无关的字段作为关键字。
一般满足前三个范式就可以避免数据冗余。
C++
1 char 在C语言中是1个字节,int是4个字节
char在JAVA中是2个字节
2.sizeof(struct )大小
struct 子项在内存中的按顺序排列,在没有#progma pack(n)参数的情况,各个子项的对齐系数为自己长度。
在有#progma pack(n)参数的情况,各子项的对齐系数为min(自己长度,n);
struct 整体的对其系数为子项对齐系数最大值
struct A{
char a; //字长1对其系数1
char b; //字长1对其系数1
char c; //字长1对其系数1
};//整体对其系数为1
sizeof(struct A)值是 3

struct B {
int a; //对其系数4
char b; //对其系数1
short c; //对其系数2
};//整体对其系数4
sizeof(strcut B)值是 8

short c对其系数2必须和偶地址对其,int a同理也与能4的倍数地址对其。
粉色内存被结构占用
struct C {
char b; //对其系数1
int a; //对其系数4
short c; //对其系数2
};//整体对其系数4
sizeof(struct C)的值是 12
如图

int a 从4的倍数地址开始,所以开始地址是4,因为结构整体对其系数为4,因此short c后的两个内存被占用,使大小为4的倍数。
sizeof(struct C)=12
#progma pack (2)
struct D {
char b; //对其系数min(长度=1,n=2)=1
int a; //对其系数min(长度=4,n=2)=2
short c; //对其系数min(长度=2,n=2)=2
};//整体对其系数2
sizeof(struct D)值是
如图

#progma pack (2) 对int a的放置产生影响,
#progma pack (n) 只能取1、2、4
因此 sizeof(struct D)=8
3.strcpy安全性
原型声明:extern char *strcpy(char *dest,const char *src); 实际使用时,要求调用前预先申请dest指针的内存空间,但是可能此空间的长度小于src的长度。此函数在复制字符串时,将会从src开始,一直碰到NULL为止,这样在复制时就可能超出dest的范围,导致内存错误。 strcpy_s多了一个dest空间长度的参数,会控制复制字符串的过程,不会越界,因而这个函数是安全的4.求秩:
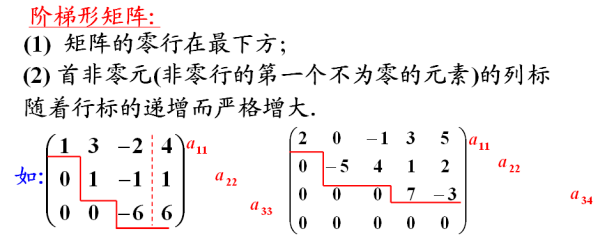
秩就是非零特征值(非0行数)的个数
5:变量的内存分配,区别
可以看出:
1. 变量在内存地址的分布为:堆-栈-代码区-全局静态-常量数据
2. 同一区域的各变量按声明的顺序在内存的中依次由低到高分配空间(只有未赋值的全局变量是个例外)。
3. 全局变量和静态变量如果不赋值,默认为0。 栈中的变量如果不赋值,则是一个随机的数据。
4. 编译器会认为全局变量和静态变量是等同的,已初始化的全局变量和静态变量分配在一起,未初始化的全局变量和静态变量分配在另一起。
可以看出,主函数中栈的地址都要高于子函数中参数及栈地址,证明了 栈的伸展方向是由高地址向低地址扩展的 。主函数和子函数中静态数据的地址也是相邻的,说明程序会将已初始化的全局变量和表态变量分配在一起,未初始化的全局变量和表态变量分配在另一起。6.深拷贝
浅拷贝是指源对象与拷贝对象共用一份实体,仅仅是引用的变量不同(名称不同)。对其中任何一个对象的改动都会影响另外一个对象。举个例子,一个人一开始叫张三,后来改名叫李四了,可是还是同一个人,不管是张三缺胳膊少腿还是李四缺胳膊少腿,都是这个人倒霉。
深拷贝是指源对象与拷贝对象互相独立,其中任何一个对象的改动都不会对另外一个对象造成影响。举个例子,一个人名叫张三,后来用他克隆(假设法律允许)了另外一个人,叫李四,不管是张三缺胳膊少腿还是李四缺胳膊少腿都不会影响另外一个人。比较典型的就是Value(值)对象,如预定义类型Int32,Double,以及结构(struct),枚举(Enum)等。
7.虚函数
什么是虚函数(如果不知道虚函数为何物,但有急切的想知道,那你就应该从这里开始) 简单地说,那些被virtual关键字修饰的成员函数,就是虚函数。虚函数的作用,用专业术语来解释就是实现多态性(Polymorphism),多态性是将接口与实现进行分离;用形象的语言来解释就是实现以共同的方法,但因个体差异而采用不同的策略。
8.虚析构
纯虚成员函数通常没有定义;它们是在抽象类中声明,然后在派生类中实现。

















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









