







 本文深入探讨B树与B+树的概念,分析它们在磁盘存储中的应用,重点阐述MongoDB的wiredTiger存储引擎如何利用B+树实现索引。wiredTiger的叶子节点以page方式存储数据,结合page header和block header定位数据。MongoDB采用Copy on write策略,数据先写入内存,通过checkpoint持久化,并利用WAL确保数据安全性。
本文深入探讨B树与B+树的概念,分析它们在磁盘存储中的应用,重点阐述MongoDB的wiredTiger存储引擎如何利用B+树实现索引。wiredTiger的叶子节点以page方式存储数据,结合page header和block header定位数据。MongoDB采用Copy on write策略,数据先写入内存,通过checkpoint持久化,并利用WAL确保数据安全性。
本篇文章主要是回顾一下B-tree(B树) B+tree(B+数) 数据结构在磁盘存储方面的应用,以及理解目前Mysql 数据库和Mongo 数据库底层的数据存储结构。
参照文章:
B-tree 和B+tree :
https://www.cnblogs.com/vianzhang/p/7922426.html
Mongo wireTiger 存储引擎分析:
https://source.wiredtiger.com/3.2.1/tune_page_size_and_comp.html
https://mongoing.com/archives/35143
https://www.cnblogs.com/olinux/p/6108203.html
1 B 树与 B+ 树介绍
B 树中文名 :平衡多路查找树,为了磁盘等外存储设备设计的一种平衡查找树。 B+ 树 是基于B树的一个变种。都是为了数据存储和检索而设计的一种结构。
B 树的特点:
每个节点的构成:
1. 节点数据;
2. 节点索引;
3. 指向子结点的指针;
m 阶树
1.每个节点最多拥有m个子树
2.根节点至少有2个子树
3.分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
4.所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列借个图,图来自参照博客

B+树与 B树的结构相同,区别就是B+ 的数据存放在叶子节点,而B数每个节点都有。
通俗来说,选用B-tree 还是B+ tree 跟使用场景有关,B 树的特点, 索引和数据都存在节点,每个节点的索引存储就会少,势必深度会增加,树深度大了,跟磁盘IO的交换次数就会变多,查询性能就会下降。但是优点是,索引跟数据在同一节点,查找索引数据非常快。B+ 树,从结构上来说与B树没什么区别,主要是将数据存储放到了叶子节点,从而索引存储的数量变多,树的深度降低。
Mysql Innodb 存储引擎选择B+树,其一是树的深度降低了,因为数据存储在叶子节点的原因,可以减少IO和磁盘的交互次数,其二 在树的叶子节点做了一个链式环结构,因为B+树的特性,叶子节点是有序排列的,通过指针的方式叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便。
2 mongo wiredTiger 的索引原理
首先wiredTiger 存储的引擎数据存储使用的是B+Tree 结构。 与 Mysql innodb 不同的时,它的叶子节点之间没有通过链式结构形成一个链表,而是每个叶子节点以page 的方式存储了数据。参照图:摘自mongo中文社区
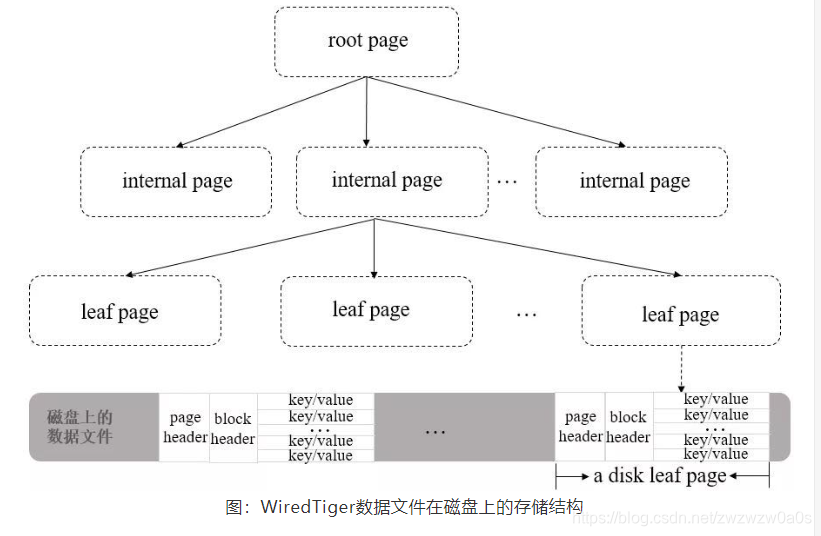
可以看到leaf page 上存储的数据主要由 page header ,block header , key/value 数据构成。
page header : 页的类型、页中实际载荷数据的大小、页中记录条数
block header: 块在磁盘上的寻址位置、数据checksum 等
在mongo 中是通过page 页来分配block 进行数据存储的,如果要定位某一行数据(key/value)的位置,可以先通过block的位置找到此page(相对于文件起始位置的偏移量),再通过page找到行数据的相对位置,最后可以得到行数据相对于文件起始位置的偏移量offsets。
而内存中除了B+tree 外又多了几种数据结构 ,一种是数组,主要是WT_ROW 和 WT_UPDATE 使用,一种是跳跃表主要是
WT_INSERT_HEAD 使用。
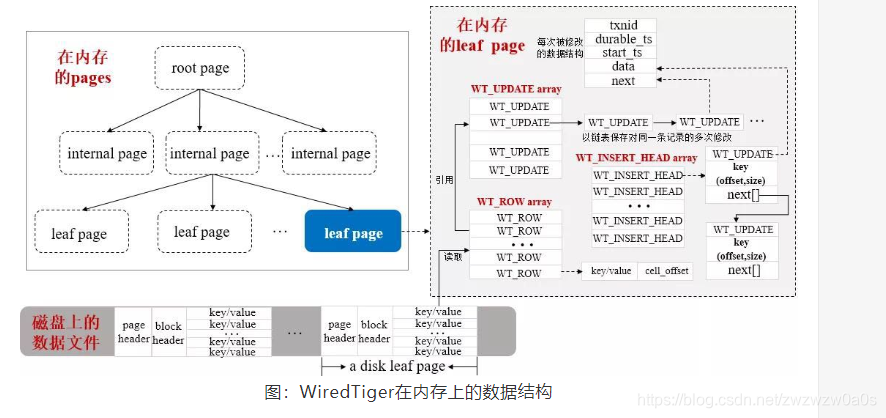
总结 mongo 采用Copy on write 的方式写数据,会先写到内存cache 中,会通过checkpoint 的方式来进行数据持久化,默认是60s 或少log 文件达到2G。 checkpoint 时,并不是在原来的节点上进行,而是写入新分配的page 上,copy 快照的方式。每次都会产生一个新的root page. 同时数据都会写入WAL 中。 当数据库crash 后,恢复是从WAL 中进行最新数据的恢复。

















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









