




 本文介绍了MongoDB中的索引和聚合操作。索引旨在提高查询效率,可以通过设置过期时间实现数据清理。聚合功能则包括不同类型的统计,如计数、按字段分组求和,以及使用管道命令进行复杂的数据处理。
本文介绍了MongoDB中的索引和聚合操作。索引旨在提高查询效率,可以通过设置过期时间实现数据清理。聚合功能则包括不同类型的统计,如计数、按字段分组求和,以及使用管道命令进行复杂的数据处理。
本篇主要学习索引和聚合,索引是为了加快查询速度,聚合是为了方便统计。
1 概述
索引的目的就是为了打标签,快速的进行数据检索。在mongodb 中数据索引的存储
$tree
.
├── admin
│ ├── collection-11--5764503550749656746.wt
│ ├── collection-14--6907424972913303461.wt
│ ├── collection-16--6907424972913303461.wt
│ ├── collection-20--6907424972913303461.wt
│ ├── collection-8--6907424972913303461.wt
│ ├── collection-9--5764503550749656746.wt
│ ├── index-10--5764503550749656746.wt
│ ├── index-12--5764503550749656746.wt
│ ├── index-13--5764503550749656746.wt
│ ├── index-15--6907424972913303461.wt
│ ├── index-17--6907424972913303461.wt
│ └── index-9--6907424972913303461.wt
├── journal
│ ├── WiredTigerLog.0000000003
│ └── WiredTigerPreplog.0000000001
├── local
│ ├── collection-0--5764503550749656746.wt
│ ├── collection-2--5764503550749656746.wt
│ ├── collection-4--5764503550749656746.wt
│ ├── collection-6--5764503550749656746.wt
│ ├── collection-7--5764503550749656746.wt
│ ├── index-1--5764503550749656746.wt
│ ├── index-3--5764503550749656746.wt
│ ├── index-5--5764503550749656746.wt
│ └── index-8--5764503550749656746.wt
├── _mdb_catalog.wt
├── mongod.lock
├── products
│ ├── collection-6--6907424972913303461.wt
│ └── index-7--6907424972913303461.wt
├── sizeStorer.wt
├── storage.bson
├── WiredTiger
├── WiredTiger.basecfg
├── WiredTiger.lock
├── WiredTiger.turtle
└── WiredTiger.wt

_mdb_catalog.wt里存储了所有集合的元数据,包括集合对应的WT table名字,集合的创建选项,集合的索引信息等,WT存储引擎初始化时,会从_mdb_catalog.wt里读取所有的集合信息,并加载元信息到内存。
集合名与WT table名的对应关系可以通过db.collection.stats()获取 。
2 创建索引
db.collection.createIndex(keys, options)
options 可选参数
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
mongo 索引有一个不同于mysql 的地方,就是可以通过索引来进行数据软化,通俗来说就是定期清理数据,这个用途是相当的棒。
数据清理的两种方式:
(1)通过设置过期时间。expireAfterSeconds 单位是秒。 创建索引的字段必须是Date 类型。
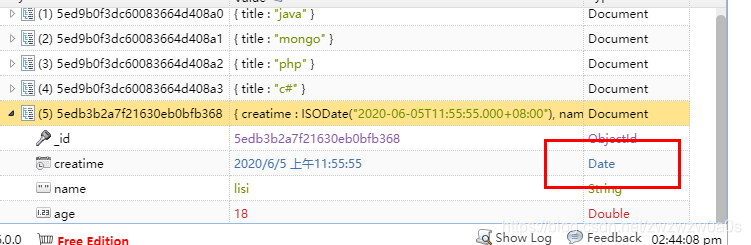
对字段cretime 进行索引设置。此种方式适用周期性过期,可以设置多少秒进行过期。
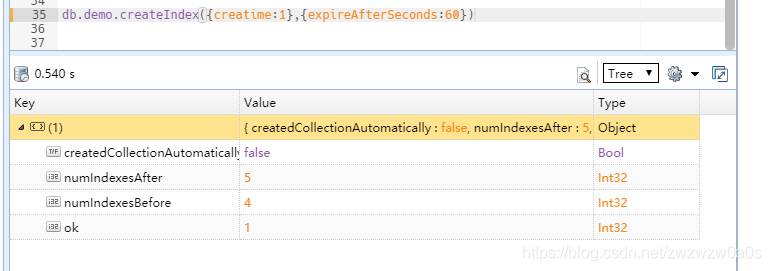
第二种方式,通过设置字段列的日期:ClearUpDate ,根据此字段的时间值进行删除。
db.demo.createIndex({"ClearUpDate": 1},{expireAfterSeconds: 0});
此种方式适用场景,某个时间点过期。可以在数据插入时,创建过期时间。
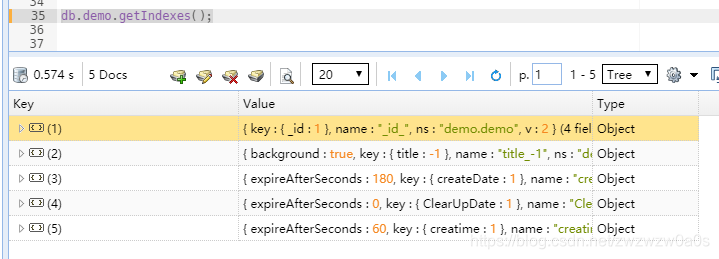
3. 查询集合索引
//查询全部索引
db.col.getIndexes()
//查询索引大小
db.col.totalIndexSize()
//删除全部索引
db.col.dropIndexes()
//根据索引名称删除
db.col.dropIndex("索引名称")
索引关键字段必须是 Date 类型。
非立即执行:扫描 Document 过期数据并删除是独立线程执行,默认 60s 扫描一次,删除也不一定是立即删除成功。
单字段索引,混合索引不支持。
4 聚合
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
聚合操作:
db.demo.aggregate([{$group: { _id: "$user",num:{$sum:1}}}]);
其中_id 不可变,$user 表示按那个字段分组,num 可随便定义,$sum 表示求和 , $sum 后面的值, 表示按那个基数求和
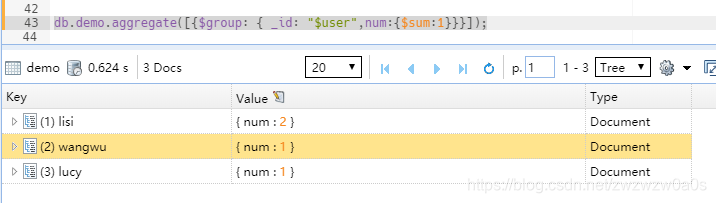
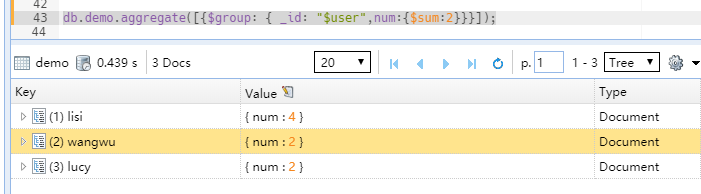
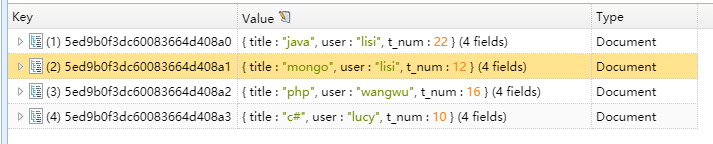
通过验证发现,当$sum 为数字1时,类似于select count(*),user from demo group by user
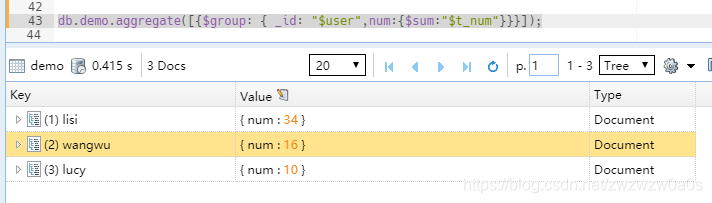
当$sum 的值为 引用变量时,类似于select sum(t_num) ,user from user group by user
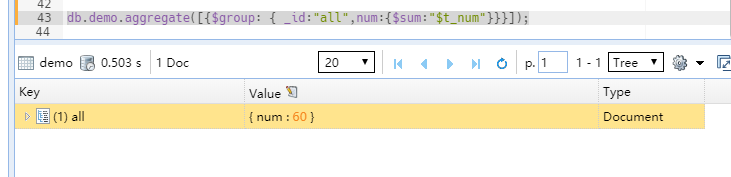
当_id 的值为空或者不存在时,统计全部数据,类似于 select sum(t_num) from user
组合命令:
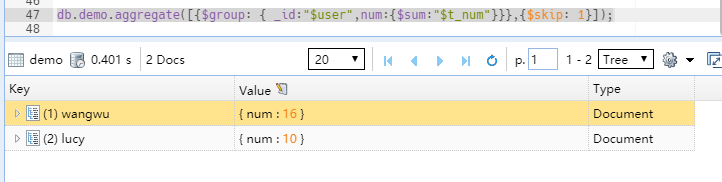
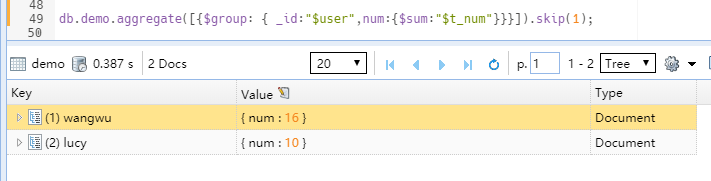
先聚合统计后跳过某一条。以上两种写法,效果一样。但是$skip 的位置决定了后续处理
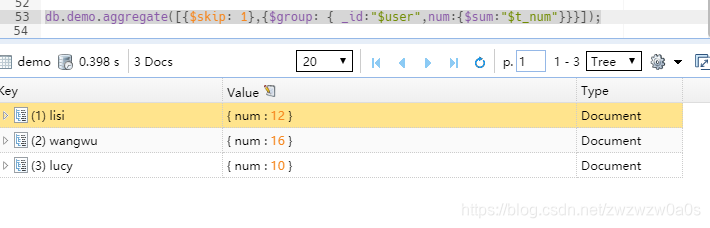
先跳过某一行,在进行统计。
总结 通过测试发现,此下的命令都为管道命令,管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
$match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
聚合表达式:
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
图片摘自网络。

















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









