






 本文详细介绍MongoDB中的排序、索引创建及聚合操作方法。包括sort()方法实现文档排序,createIndex()方法创建索引以提高查询效率,以及aggregate()方法进行数据聚合分析等核心功能。
本文详细介绍MongoDB中的排序、索引创建及聚合操作方法。包括sort()方法实现文档排序,createIndex()方法创建索引以提高查询效率,以及aggregate()方法进行数据聚合分析等核心功能。
一、排序
1、sort()方法
1)语法
db.COLLECTION_NAME.find().sort({KEY:1})
参数说明:
①KEY:指定排序的字段。
②1:升序方式。(默认按照)
-1:降序方式。
2)示例
1、根据年龄(year)进行升序排序,结果中只显示name、year两个字段

注意:
①第一个{}:存放where条件,为空表示返回集合中所有文档。
②第二个{}:要查询的字段有哪些,1表示显示,0表示不显示。
③默认情况下,"_id"字段为1,其它字段中只要有一个字段为1,则另一些字段就为0。
二、索引
1、索引:提高查询速度,有索引之后,仅需扫描索引列即可(不需扫描全部内容),
2、createIndex()方法(创建索引3.0.0版本后)
1)语法
db.COLLECTION_NAME.createIndex({<key>:<n>})
参数说明:
①key:要创建的索引字段(键)名。
②n
1:按升序创建索引,
0:按降序创建索引。
2) createIndex()可以接受的参数(可选参数)
|
参数 |
类型 |
描述 |
|
background |
Boolean |
true:指定以后台方式创建索引 false:默认情况 |
|
unique |
Boolean |
建立的索引是否唯一 true:创建唯一索引 false:默认情况 |
|
name |
string |
索引名称。 未指定,通过连接索引的字段名和排序顺序生成一个索引名称。 |
|
dropDups |
Boolean |
建立唯一索引时是否删除重复记录 true:创建唯一索引 false:默认情况 |
|
sparse |
Boolean |
文档中不存在的字段数据不启用索引 true:索引字段中不会查询出不包含对应字段的文档。 false:默认情况 |
|
expireAfterSeconds |
integer |
指定一个以秒为单位的数值,完成TTL设定,设定集合的生存时间 |
|
v |
index version |
索引的版本号。 mongod创建索引时运行的版本(默认情况下) |
|
weights |
document |
索引权重值(1-99999之间)。 该索引相对于其它索引字段的比重值 |
|
default_language |
string |
对于文本索引,停用词及词干和词器的规则列表(默认英语) |
|
language_override |
string |
对于文本索引,指定包含在文档中的字段名,语言覆盖默认的language(默认值为language) |
3)示例
1、在后台使用name字段(按升序)创建索引(增加background:true选项)
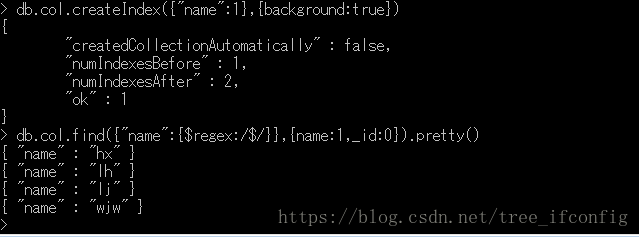
3、使用"name"、"year"字段创建索引
db.col.createIndex({"name":1,"year":1})
4)索引的其它方法
①db.COLLECTION_NAME.dropIndex(index) 移除集合指定的索引功能(index为需要删除的集合索引名)
②db.COLLECTION_NAME.getIndexes() 返回一个集合中的现有索引描述信息的文档数组
③db.COLLECTION_NAME.dropIndexes() 移除集合的索引功能
④db.COLLECTION_NAME.reIndex() 删除指定集合上所有索引,重新构建所有现有索引(该命令在大数据情况下特别影响性能)
⑤db.COLLECTION_NAME.totalIndexSize() 提供指定集合索引大小的报告信息
三、聚合
1、概念:
①聚合为集合文档数据提供各种处理数据方法,并返回计算结果。
②三种方式执行聚合命令:聚合管道方法、map-reduce方法(没第一种好,不用)、单一目标聚合方法
2、aggregate()方法(聚合管道方法)
1)概念
①聚合管道方法(合计流水线法),就是把集合里若干含数值型的文档及,其键对应的值进行各种分类统计。
②该方法支持分片集合操作。
2)语法
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
3)示例
对"col"集合根据"year"字段进行分组,并将字段值存到_id上,统计结果存到"num"字段

类似于:select year,count(*) from col group by year
4)一些聚合表达式
|
表达式 |
描述 |
示例 |
|
$sum |
计算总和 |
db.col.aggregate([{$group:{_id:”$year”,sum:{$sum:1}}}]) |
|
$avg |
计算平均值 |
db.col.aggregate([{$group:{_id:”$year”,avg_year:{$avg:”$year”}}}]) |
|
$min |
获取集合中所有文档对应值的最小值 |
db.col.aggregate([{$group:{_id:”$year”,min_year:{$min:”$year”}}}]) |
|
$max |
获取集合中所有文档对应值的最大值 |
db.col.aggregate([{$group:{_id:”$year”,max_year:{$max:”$year”}}}]) |
|
$push |
在结果文档中插入值到一个数组中 |
db.col.aggregate([{$group:{_id:”$year”,result:{$push:”year”}}}]) |
|
$addToSet |
在结果文档中插入值到一个数组中,但不创建副本。 |
db.col.aggregate([{$group:{_id:”$year”,result:{$addToSet:”$name”}}}]) |
|
$first |
根据资源文档的排序获取第一个文档数据 |
db.col.aggregate([{$group:{_id:”$year”,first_name:{$first:”$name”}}}]) |
|
$last |
根据资源文档的排序获取最后一个文档数据 |
db.col.aggregate([{$group:{_id:”$year”,last_name:{$last:”$name”}}}]) |
5)管道(MongoDB的聚合管道)-----------------处理文档的
(1)定义:一个管道处理完毕后将结果传递给下一个管道处理,管道操作可重复。
(2)表达式:处理输入文档并输出。
(3)常用的操作符:
|
操作符 |
说明 |
|
$project |
修改输入文档的结果。(可重命名、增加或删除域、创建计算结果和嵌套文档)。 |
|
$match |
用于过滤数据,只输出符合条件的文档,该操作为标准查询操作。 |
|
$limit |
限制MongoDB聚合管道返回的文档数。 |
|
$skip |
在聚合管道中,跳过指定数量的文档,并返回余下的文档。 |
|
$unwind |
将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。 |
|
$group |
将集合中的文档分组,可用于统计结果。 |
|
$sort |
将输入文档排序后输出 |
|
$geoNear |
输出接近某一地理位置的有序文档 |
(4)示例
①使用$project,只显示name和year字段。

②使用$match,用于获取year大于17小于或小于等于18记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理

③使用$skip,跳过前一个文档。
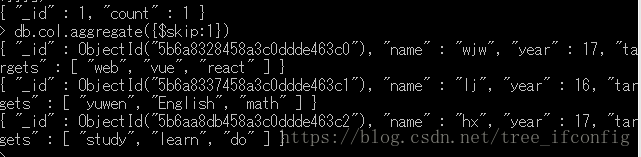
3、单一目标聚合方法
1) db.COLLECTION_NAME.count()
(1)语法
db.COLLECTION_NAME.count(query,options)
(2)命令说明
1、功能:统计集合里符合查询条件的文档数量。
2、参数说明:
①query:查询条件。
②options:选项。
option参数列表
|
名称 |
类型 |
说明 |
|
limit |
Integer |
限制要计数的文档的最大数量 |
|
Skip |
Integer |
计数前要跳过的文档数 |
|
Hint |
String或document |
对需要查询的索引进行提示或详细说明 |
|
maxTimeMS |
Integer |
设置允许查询运行的最长时间 |
|
ReadConcern |
String |
指定读取关注(默认local) 指定majority级别时,必须要满足以下三个天剑
|
(2)示例
1、统计符合条件的记录数(年龄大于15的人数)
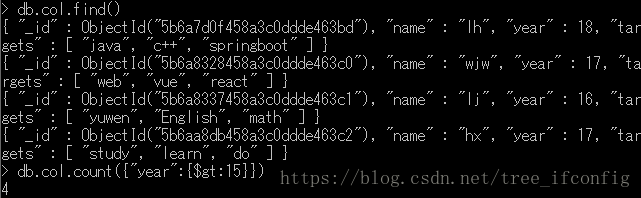
2)db.COLLECTION_NAME.distinct()
(1)语法
db.COLLECTION_NAME.distinct(<key>,query,option)
(2)命令说明
1、功能:统计集合里指定键的不同值,并返回结果。
2、参数说明:
①<key>:一个键名。
②query:集合查询条件。
③option:collations选项。
(3)示例
1、统计集合中_id的的不同值,并且返回。
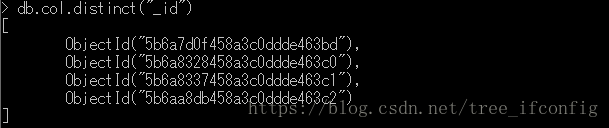

















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









