






一、关于Hive
1.1、什么是Hive
Hive是基于Hadoop的数据仓库建模工具之一。
Hive可以使用类sql方言,对存储在hdfs上的数据进行分析和管理。传入一条交互式sql在海量数据中查询分析结果的工具。
1、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
2、Hive处理的数据存储在HDFS上。
3、Hive是将SQL语句转译成MapReduce任务,在yarn上执行。
1.2、Hive的优缺点
优点:
1、支持SQL语法查询,不用写复杂的MapReduce程序,易于上手 。
2、基于MapReduce算法,处理大数据,优势明显。
3、Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
1、Hive的执行延迟比较高,因为启动并运行一个MapReduce程序本身需要消耗非常多的资源;因此Hive常用于数据分析,适用于对实时性要求不高的场合。
2、Hive的HQL语句表达能力有限, 比如,迭代式算法无法表达、数据挖掘方面不擅长。
3、Hive处理小数据没有优势。
4、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
1.3、Hive的整体架构
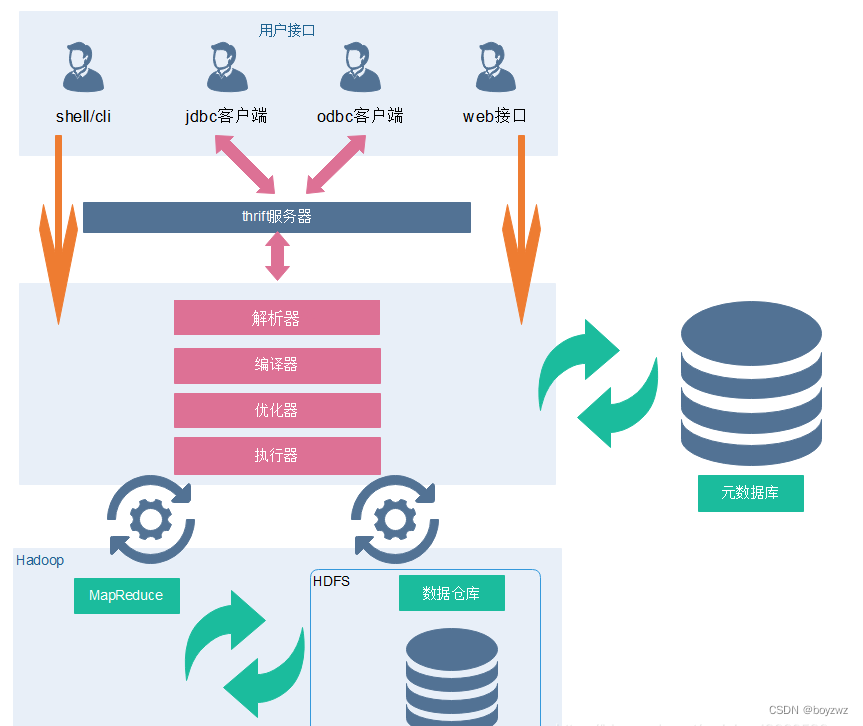
1、用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问 hive)
2、元数据:Metastore
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3、驱动器:Driver
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2) 编译器(Physical Plan):将AST编译生成逻辑执行计划。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
二、Hive安装
三、Hive操作
1、建表
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','// 必选,指定列分隔符
LOCATION '/input1'; // 指定Hive表的数据的存储位置,一般在数据已经上传到HDFS,想要直接使用,会指定Location,通常Locaion会跟外部表一起使用,内部表一般使用默认的location
2、加载数据
1、加载HDFS上的数据
load data inpath '/input1/students.txt' into table students;
// 将HDFS上的/input1目录下面的数据移动至 students表对应的HDFS目录下 ;原本目录下数据就没了。
2、加载本地数据
// 清空表
truncate table students;
// 加上 local 关键字 可以将Linux本地目录下的文件 上传到 hive表对应HDFS 目录下 原文件不会被删除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
// overwrite 覆盖加载
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
3、内部表与外部表
内部表:默认建表是内部表,内部表数据由Hive自身管理;删除内部表会直接删除表的元数据和存储数据
外部表:建表使用external修饰的为外部表,外部表数据由HDFS管理; 删除外部表只会删除表的元数据,HDFS上的数据文件不会被删除。
四、Hive函数
1、count(*)、count(1) 、count('字段名') 区别
从执行结果来看
-
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL 最慢的
-
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL 最快的
-
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计 仅次于count(1)
从执行效率来看
-
如果列为主键,count(列名)效率优于count(1)
-
如果列不为主键,count(1)效率优于count(列名)
-
如果表中存在主键,count(主键列名)效率最优
-
如果表中只有一列,则count(*)效率最优
-
如果表有多列,且不存在主键,则count(1)效率优于count(*)
在工作中如果没有特殊的要求,就使用count(1)来进行计数。
2、Hive中执行顺序
1.from
2.join on 或 lateral view explode(需炸裂的列) tbl as 炸裂后的列名
3.where
4.group by
5.聚合函数 如Sum() avg() count(1)等
6.having 在此开始可以使用select中的别名
7.select 若包含over()开窗函数,此时select中的内容作为窗口函数的输入,窗口中所选的数据范围也是在group by,having之后,并不是针对where后的数据进行开窗,这点要注意。需要注意开窗函数的执行顺序及时间点。
8.distinct
9.order by
10.limit
3、常用函数
1、where 条件里不支持不等式子查询,实际上是支持 in、not in、exists、not exists ;当比较条件时可添加一列如"1 as cid",让两表进行join,在进行比较。
2、Hive中对大小写不敏感
3、Hive中对null值进行计算时,都会变成null;可用nvl()函数将null变为0进行计算;
eg:select id,nvl(x,0) from vels; //x为null就是0
判断null时,可用 is null 进行判断
4、使用explain查看SQL执行计划;(explain select ... from...)
查看更加详细的计划可加上extended;(explain extended select ... from...)
5、数值计算
取整函数(四舍五入):round
向上取整:ceil
向下取整:floor
6、条件函数
if:
if(表达式,如果表达式成立的返回值,如果表达式不成立的返回值)
if(1>0,1,0) //1
case when:
select score
,case when score>120 then '优秀'
when score>100 then '良好'
when score>90 then '及格'
else '不及格'
end as pingfen
from score limit 20;注意:END只是作为条件的结束语句,后面字段为别名,没有特殊含义
7、日期函数
current_date :当前日期
date_add:加 date_add('2022-6-8',1)
date_sub:减 date_sub('2022-6-8',1)
datediff:日期相减 datediff('2022-6-8','2022-6-7')
unix_timestamp:获取当前unix时间戳 unix_timestamp()
from_unixtime:转化unix时间戳到当前时区的时间格式
eg:from_unixtime(135447443,'YYYY-MM-dd')
结合可得到转换日期格式(将时间转为时间戳,再将时间戳转为指定格式):
unix_timestamp('2022/06/08','yyyy/MM/dd')
from_unixtime(unix_timestamp('2022/06/08','yyyy/MM/dd'),'YYYY-MM-dd')

8、字符串函数
concat:字符串拼接 concat('123','456') //123456
concat('123','456',null) //null
concat_ws:指定分隔符拼接(如果有null,会自动忽略)
select concat_ws('~','2022-6-8','2022-6-9');
substring():截取(从1开始计数) substring('字符串',1,2) 从1位置截取,截取2位
split:切分 split('a,b,c',',') 以','切分
explode:一行转多行 explode(split('a,b,c',','))

4、聚合窗口函数
sum(求和)
min(最小)
max(最大)
avg(平均值)
count(计数)
lag(获取当前行上一行的数据)
-- 聚合格式
select sum(字段名) over([partition by 字段名] [ order by 字段名]) as 别名 from 表名;sum(score) over(partition by subject order by score rows between 1 preceding and 1 following) as sum6
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
5、排序开窗函数
-
RANK() 排序相同时会重复,总数不会变
-
DENSE_RANK() 排序相同时会重复,总数会减少
-
ROW_NUMBER() 会根据顺序计算
-
PERCENT_RANK()计算给定行的百分比排名。可以用来计算超过了百分之多少的人(当前行的rank值-1)/(分组内的总行数-1)
-- 排序窗口格式
select rank() over([partition by 字段名] [ order by 字段名]) as 别名 from 表名;

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









