



 本文探讨了数据集分割、模型选择和评估的重要性,强调了训练集、验证集和测试集的合理分配。介绍了线性回归和逻辑回归,并讨论了正则化在控制模型偏差和方差中的作用。通过学习曲线分析,展示了高偏差和高方差问题,提出了解决欠拟合和过拟合的策略,帮助读者理解如何选取合适的正则化参数以提高模型的泛化能力。
本文探讨了数据集分割、模型选择和评估的重要性,强调了训练集、验证集和测试集的合理分配。介绍了线性回归和逻辑回归,并讨论了正则化在控制模型偏差和方差中的作用。通过学习曲线分析,展示了高偏差和高方差问题,提出了解决欠拟合和过拟合的策略,帮助读者理解如何选取合适的正则化参数以提高模型的泛化能力。
评估假设
分割数据集,典型比例为7:3,通常先打乱再分割,下标m表示样本来自测试集
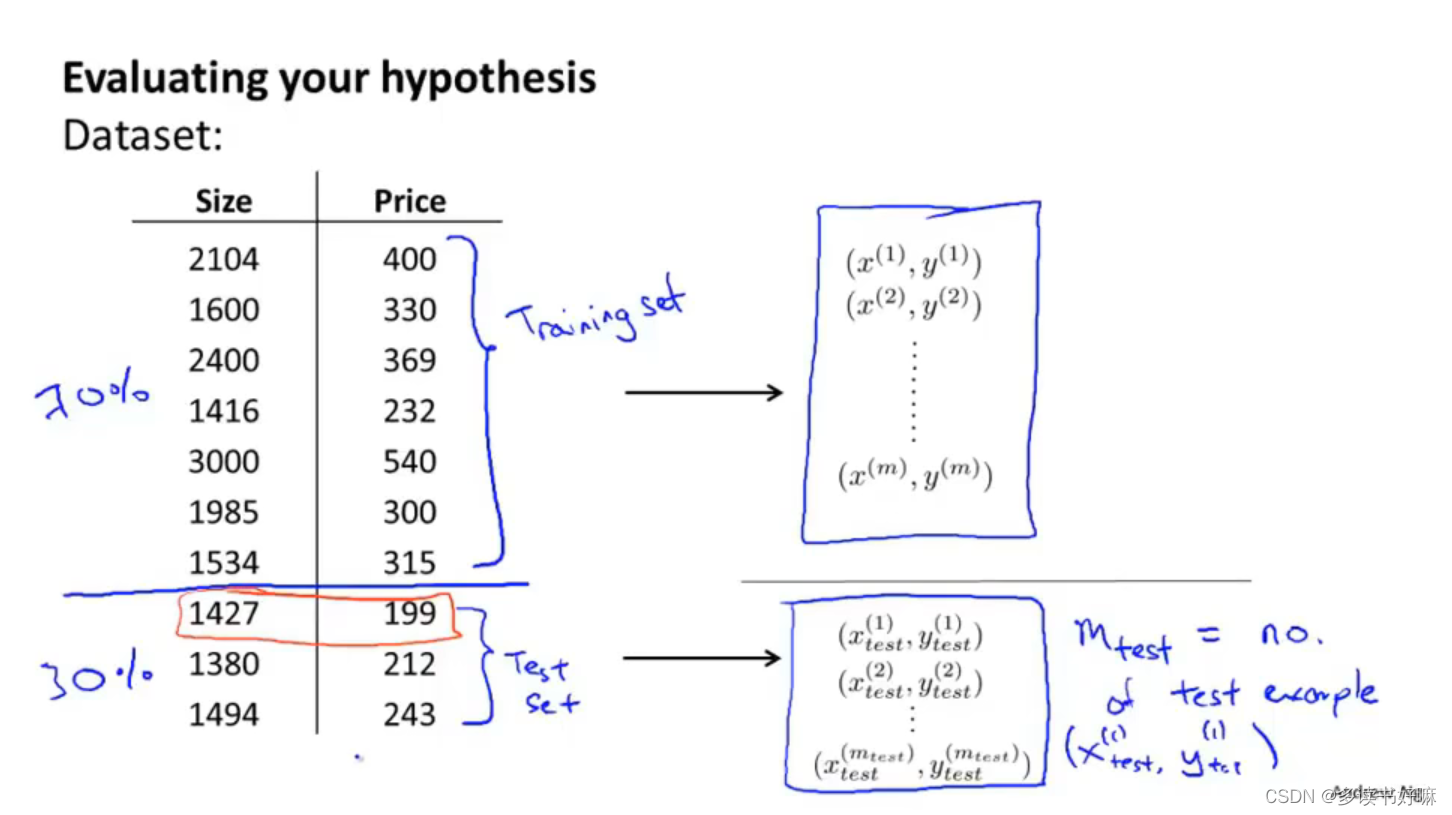
线性回归

逻辑回归

模型选择

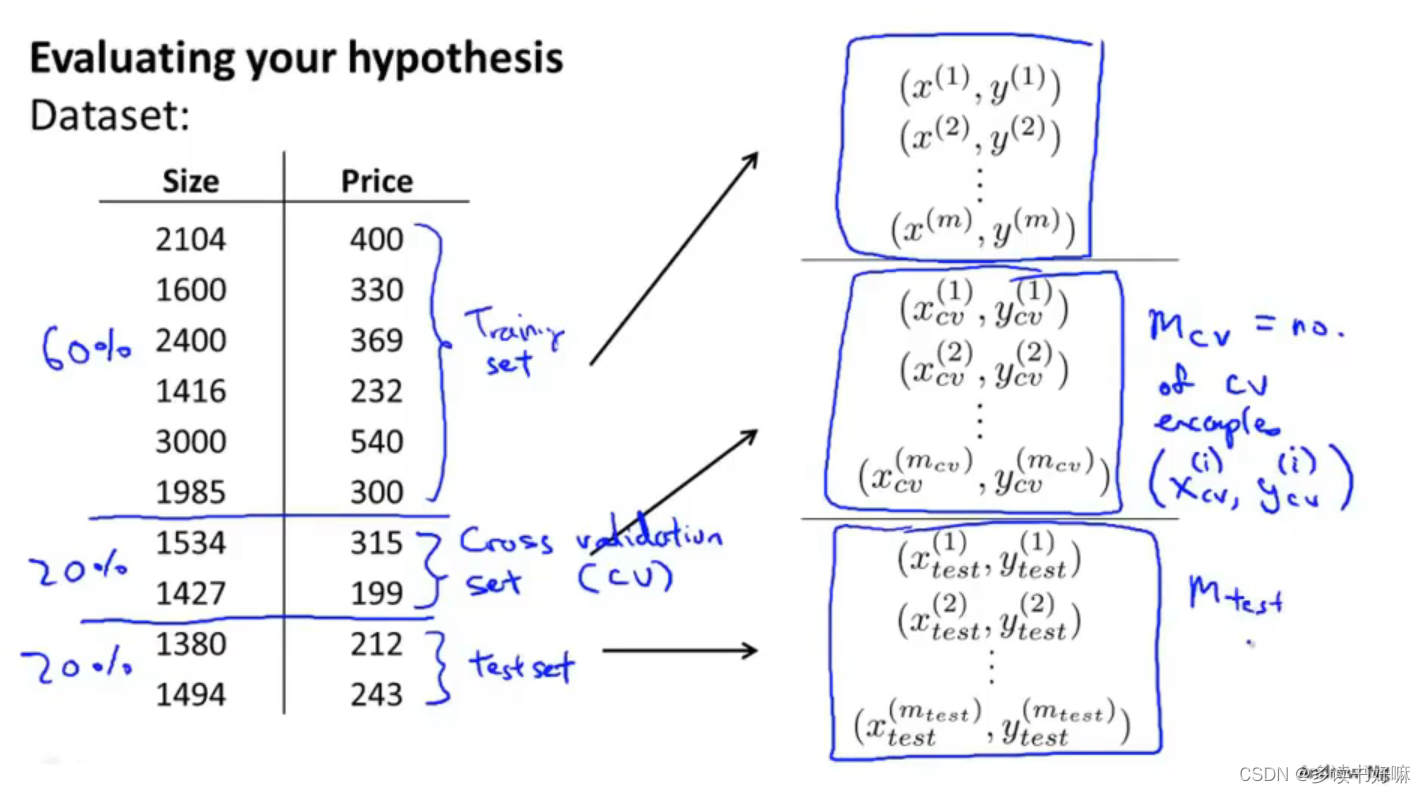
用训练集训练出来的模型再训练集上不能预测出其对于新样本的泛化能力,因此把数据集分成训练集、验证集、测试集,典型为6:2:2


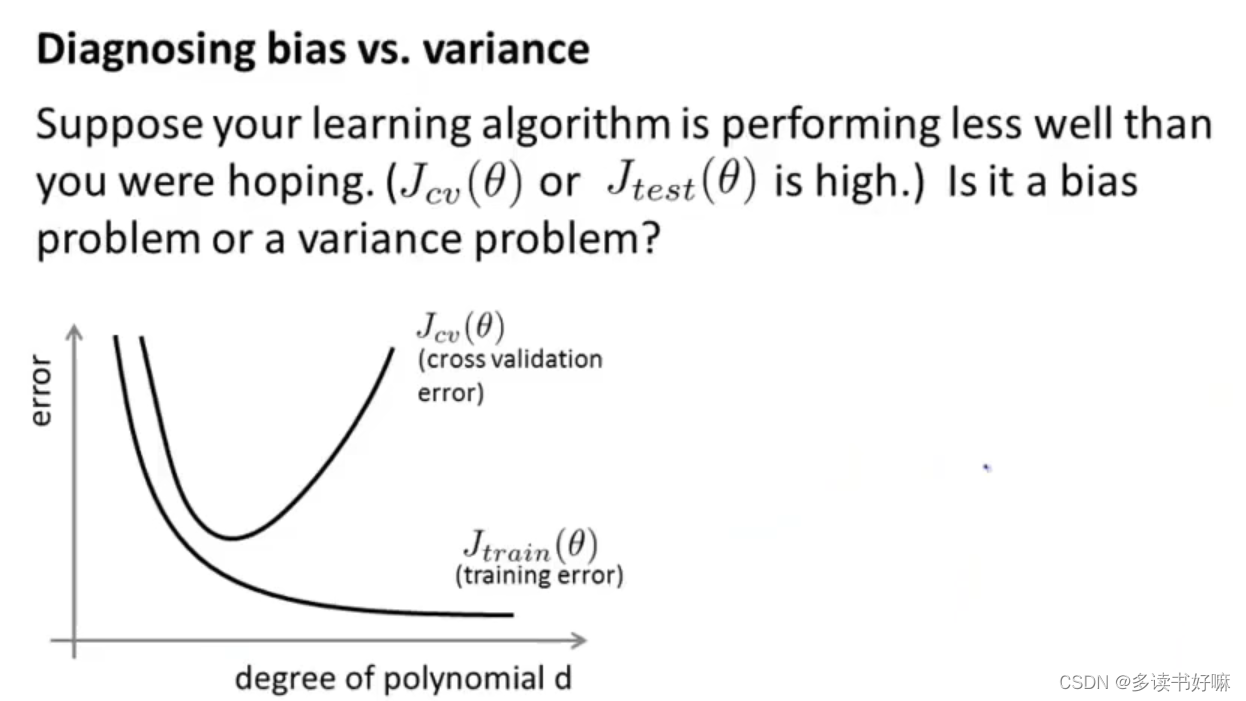
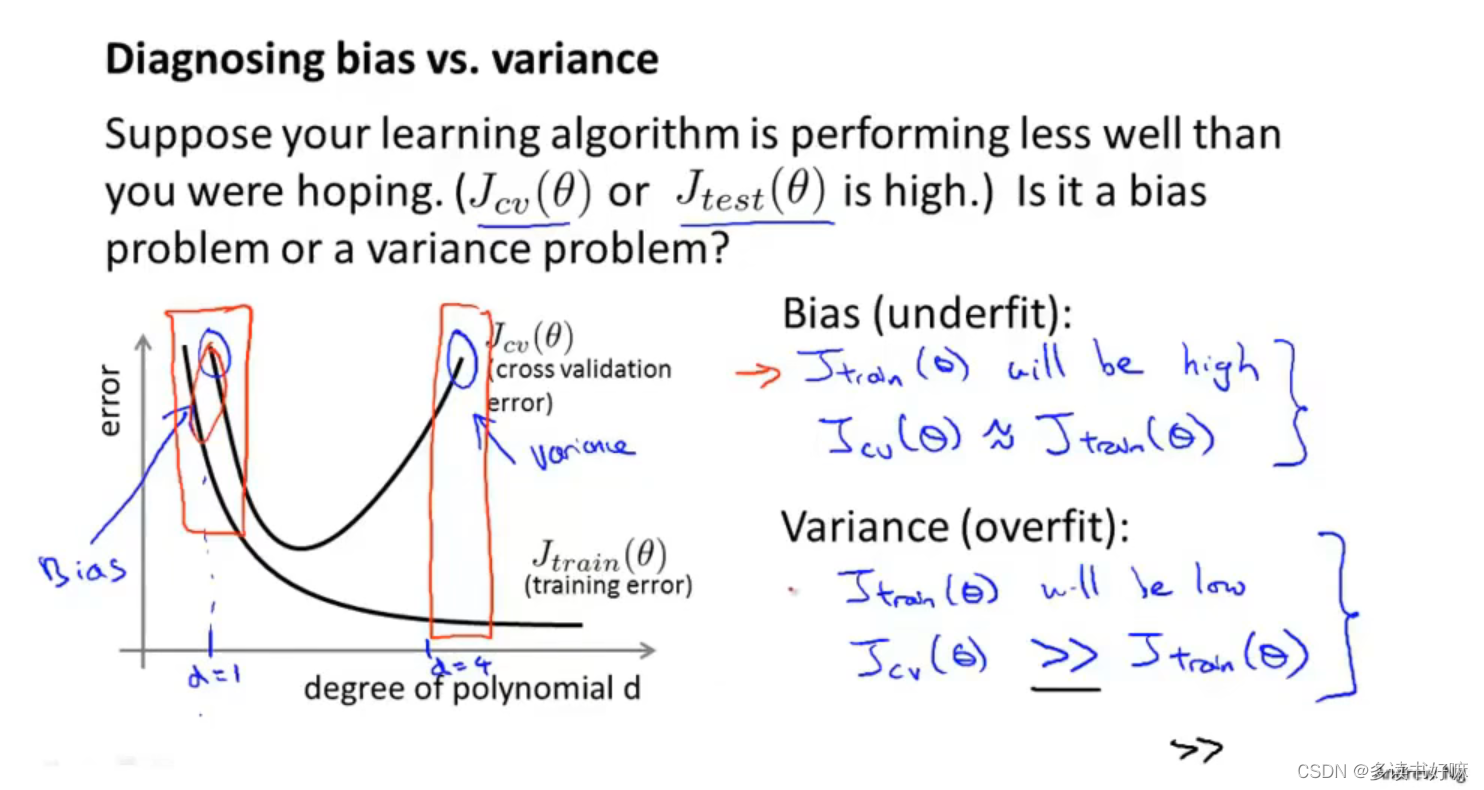
诊断偏差与方差

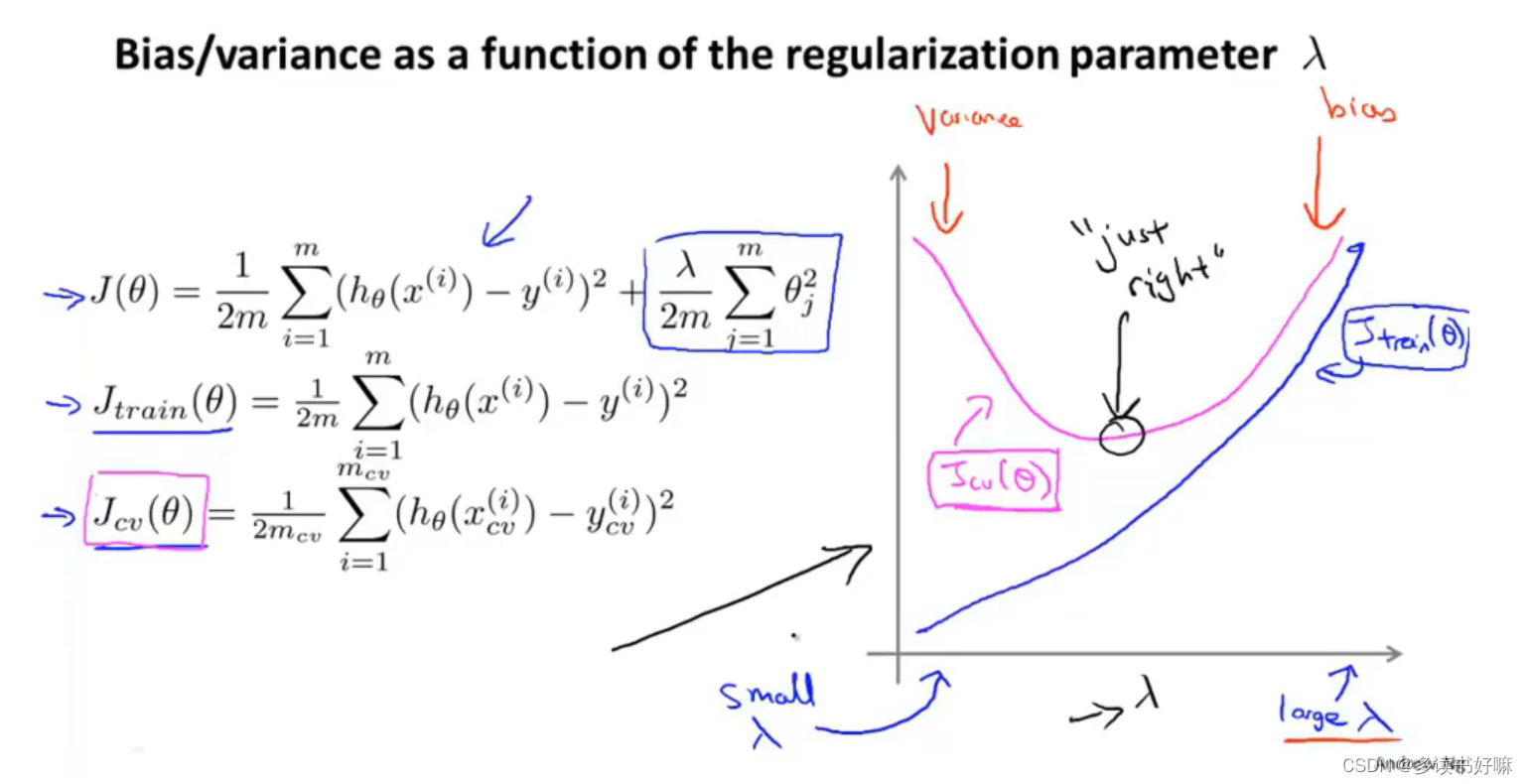
正则化与偏差、方差
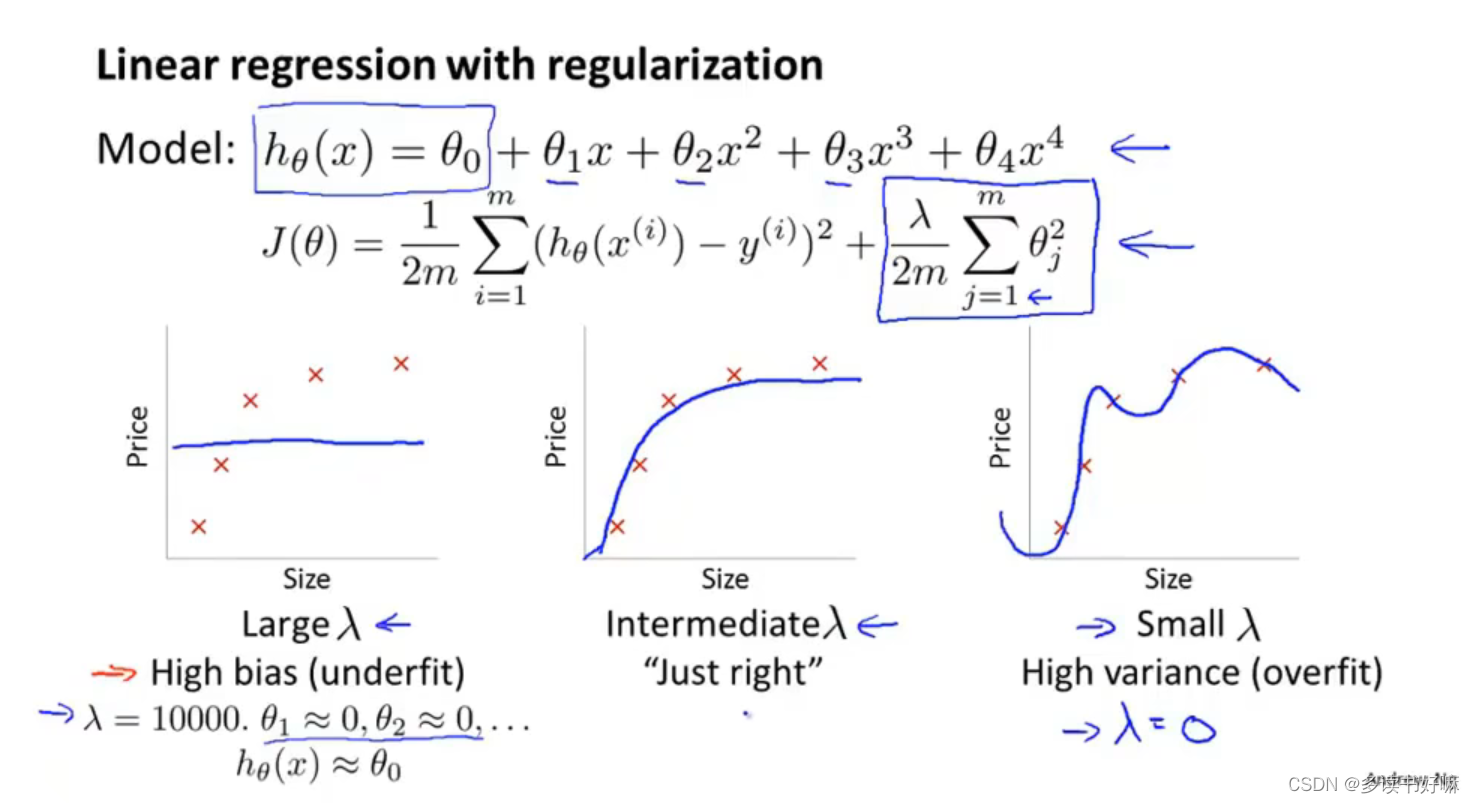
如何选取合适的正则化参数
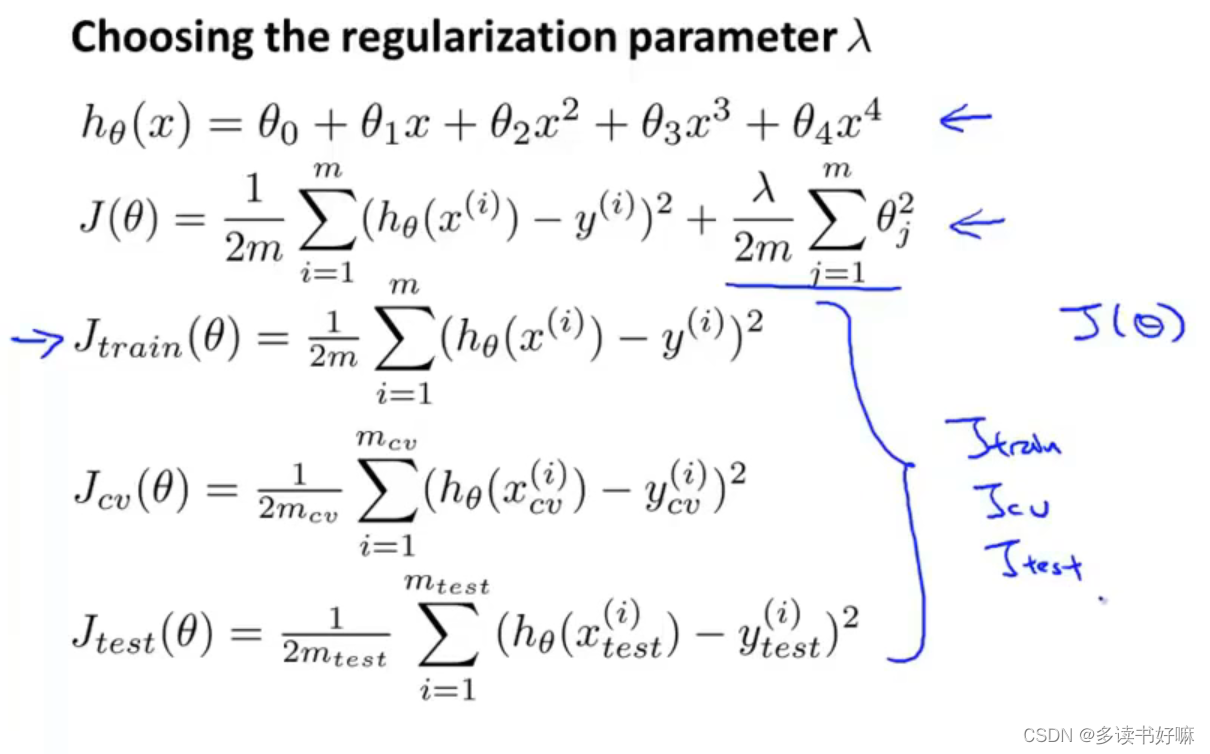
代价函数不用加正则化项

尝试不同参数,用交叉验证误差最小的之后可以用测试集来评估
学习曲线
数据用的越多,泛化性能越好,所以J_cv递减
数据越多,想对每一个样本都很好的拟合越困难,所以J_train递增
画出学习曲线有助于了解你算法可能处于的情况
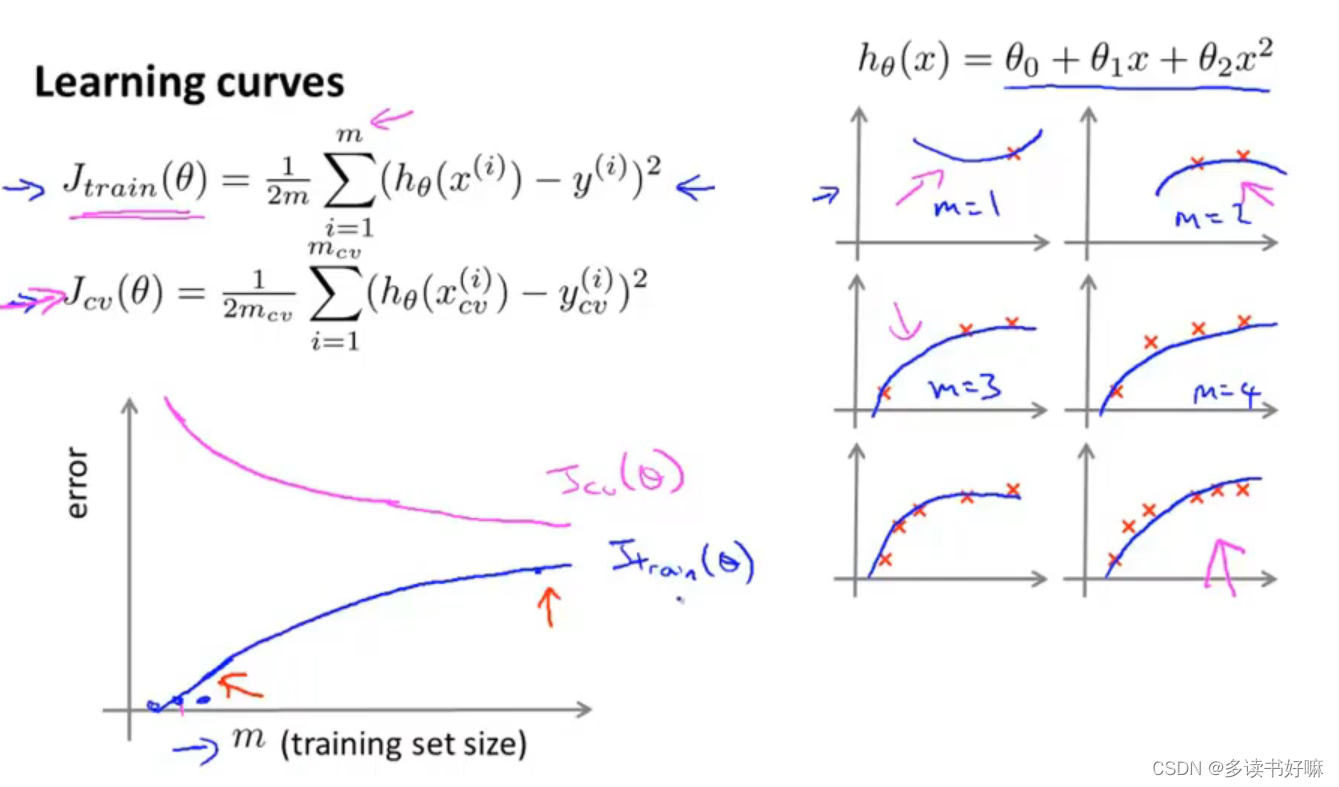
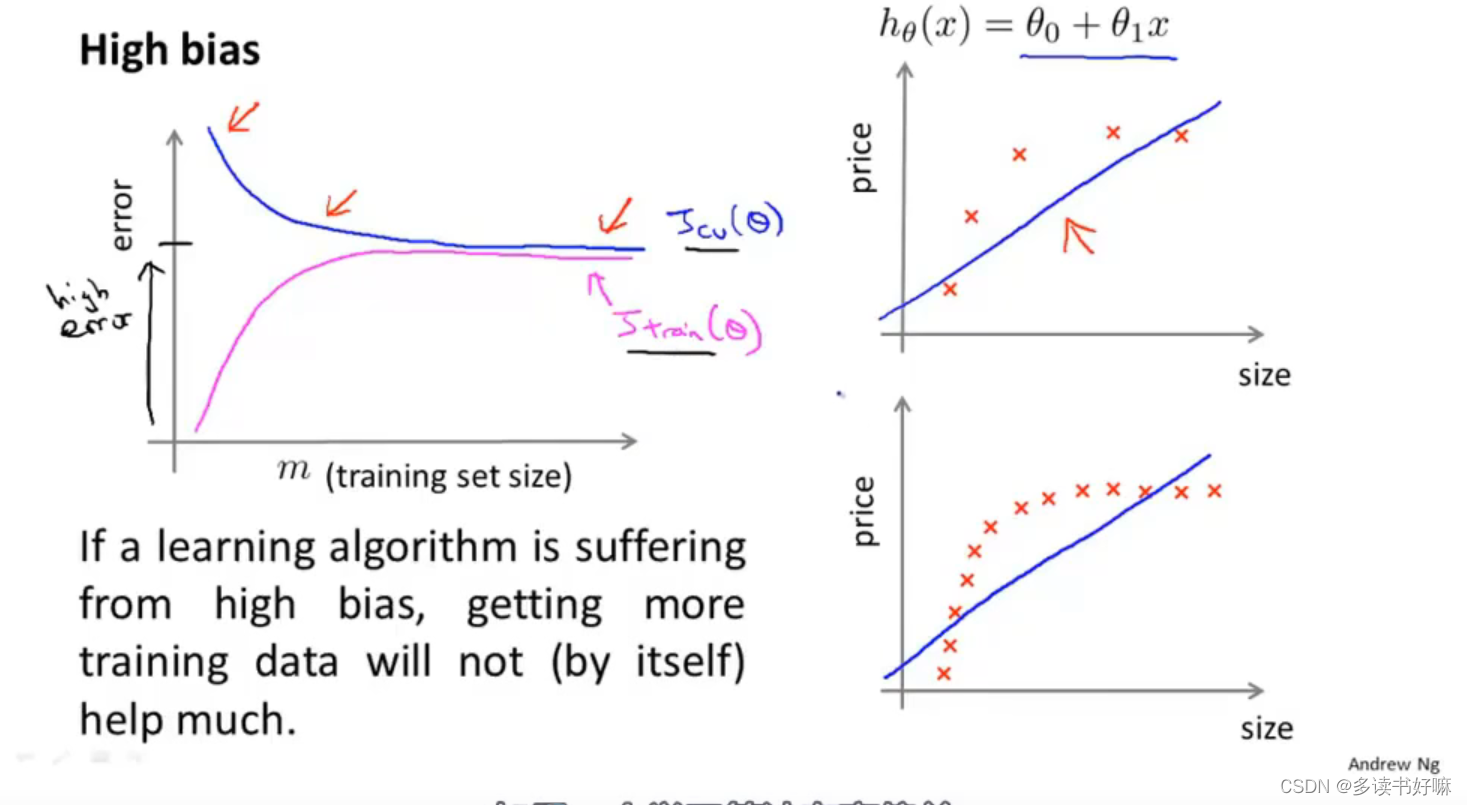
高偏差
事实上,一个学习算法有高偏差,随着m增加,两曲线趋平,且相等,此时再增加数据也没有太大的意义
高方差
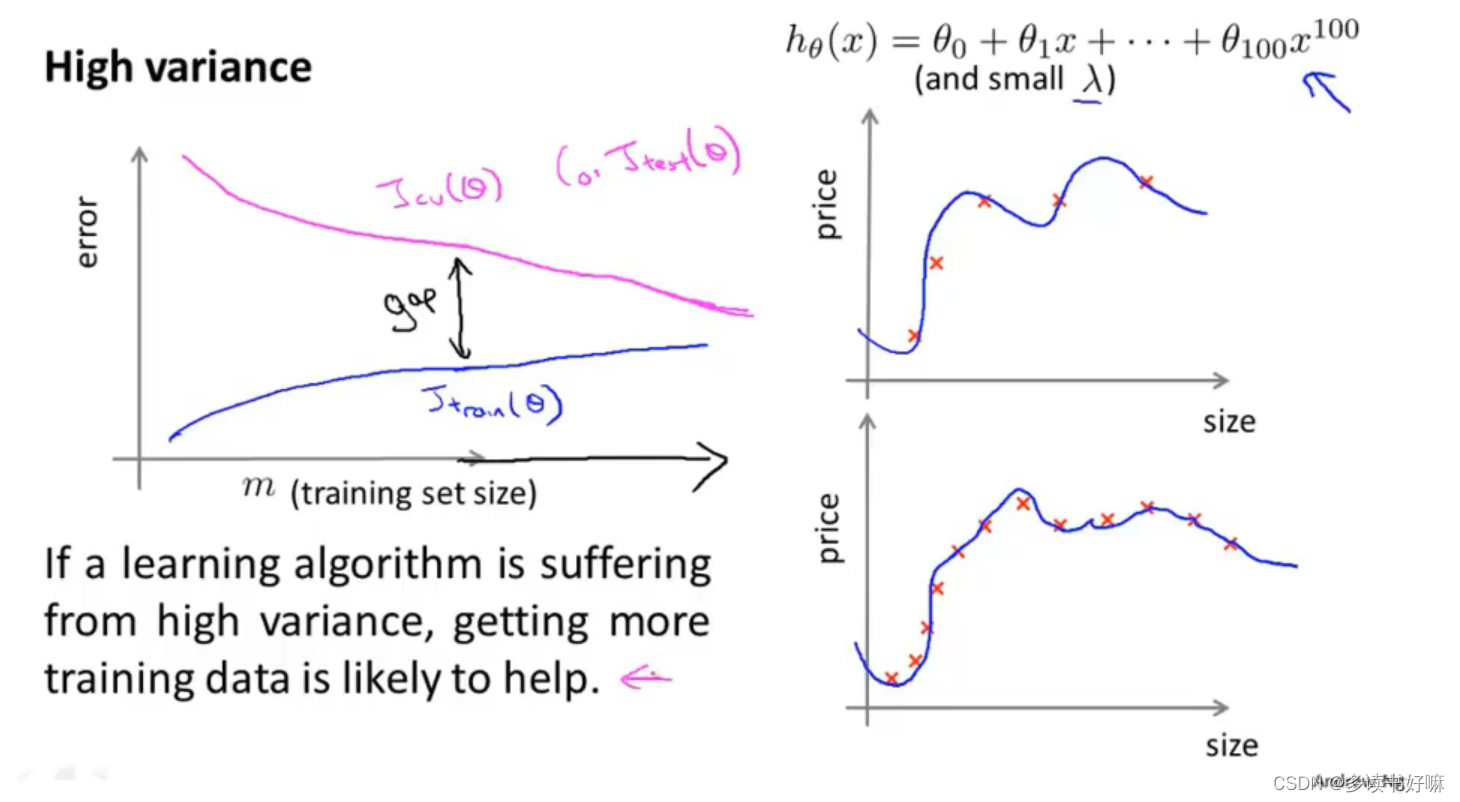
欠拟合(λ较大)会产生高偏差;过拟合(λ较小)过产生高方差
解决


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









