







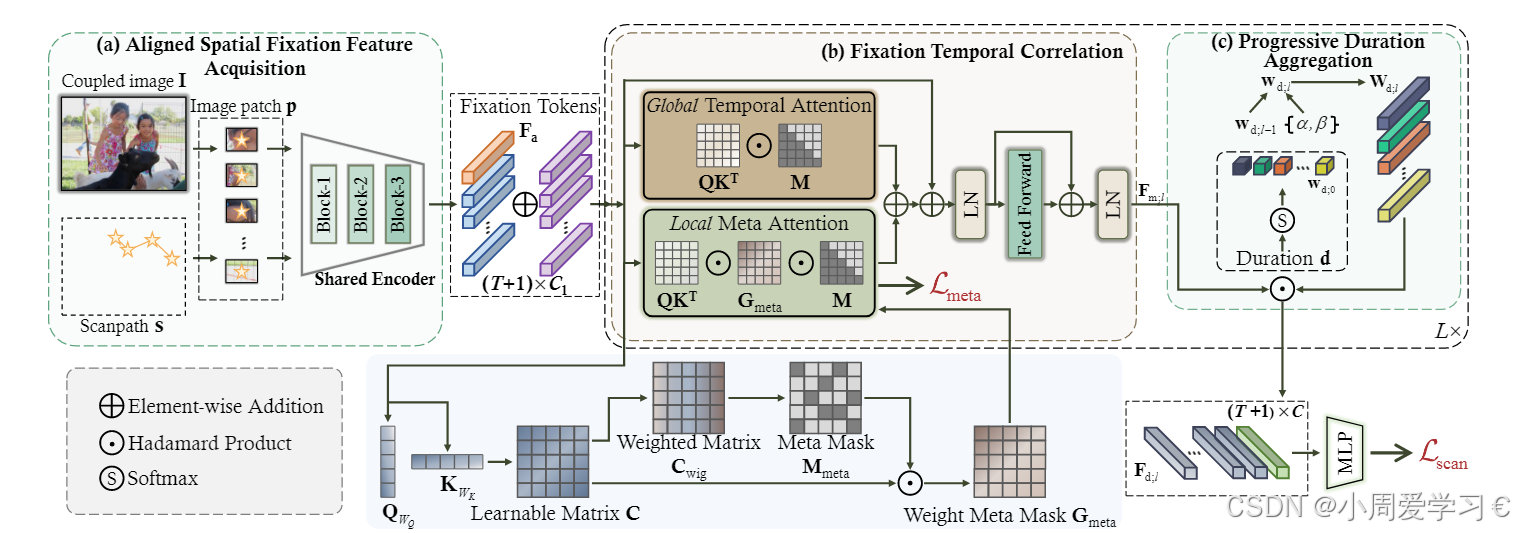


理解“语义偏差”以及为什么共享编码器能够消除它?
场景:不同老师给学生打分
假设有两位老师在评估学生的作文,任务是根据学生的作文给出一个分数。虽然每位老师都在评估同一篇作文,但他们的评分标准不同。
- 老师A:非常重视语法和句子结构,所以他会特别关注句子是否有语法错误,给出分数。
- 老师B:更加注重创意和想象力,所以她主要看作文是否有新颖的想法,给出分数。
现在,你拿到了两位老师的评分表。这时,你可能发现,即使是同一篇作文,因为老师关注的侧重点不同,两个老师给出的分数可能差距很大。这样的差距就是**“语义偏差”**——每个老师因为评估标准不同,对作文的理解(语义)也不同。
现在引入共享编码器
为了避免这种评分差异,你决定让所有作文都交给同一个老师来评分,比如让老师A评估所有的作文。因为现在只有一个老师评分,所有作文的评分标准是一致的,分数的差异就只反映了作文本身的质量,而不会因为不同老师的评估标准不同而产生偏差。
这就是“共享编码器”的作用。它像是一个“统一的老师”,保证所有输入(比如不同的图像区域或注视点)都按照同样的标准来处理和评估,从而消除不同处理器(老师)带来的语义偏差。
回到SpFormer中的例子:
在注视路径中,每个注视点代表图像中的一个局部区域。如果每个注视点都使用不同的编码器(比如不同的老师),那么提取出来的特征可能会因为编码器的差异而不一致(即语义偏差),无法准确对比或整合。
使用共享编码器,意味着所有注视点的图像区域都通过相同的特征提取器处理(像让同一个老师评分所有作文)。这样可以确保特征是一致的,提取出的特征可以在同一语义空间中进行比较或分析,避免了不同编码器带来的不一致问题。
总结:
- 语义偏差:不同的特征提取方式导致对相同数据的理解或表示不一致。
- 共享编码器:确保所有数据通过同一标准处理,消除不一致的特征表示,保证在同一语义空间中进行对比和分析。
全局时间注意力的运作过程
-
输入特征:
- 假设我们有一系列的注视点,每个注视点都有自己的特征表示(例如颜色、形状、位置等),这些特征可以被看作是一个向量。
-
查询、键、值的构建:
- 对于每个注视点,我们生成三个不同的表示:
- 查询(Q):每个注视点的特征向量用于表示该点想要获取的信息。
- 键(K):每个注视点的特征向量用于表示它自己所包含的信息。
- 值(V):与键对应的信息,可以理解为与该注视点相关的上下文信息。
- 对于每个注视点,我们生成三个不同的表示:
-
计算注意力权重:
- 模块通过计算查询和键之间的相似度(通常用点积来完成)来生成一个权重矩阵,这个矩阵表示每个注视点对其他注视点的关注程度。
- 这一步类似于评估一个人对其他社交网络成员的关注程度:谁在谈论谁,谁和谁之间有联系。
-
结合全局特征:
- 使用Hadamard积(逐元素相乘)将这个权重矩阵与全局特征矩阵(M)结合。这就像是在强化网络中某些重要联系,让它们在模型中变得更加突出。
-
输出结果:
- 最后,结合后的信息输出一个表示,包含了注视点之间的全局时间依赖关系。这个输出捕捉了哪些注视点在时间上是相关的,帮助模型理解在一个特定时间内关注的内容。
场景:观看篮球比赛
想象你在观看一场篮球比赛,你的目光在场上不同的球员之间快速移动。这里可以用全局时间注意力来解释你注意力的变化。
注视点:
- 你在比赛中可能注视不同的球员,比如队员A、队员B、队员C等。每个球员的表现和位置在你眼中都是“注视点”。
查询、键、值:
- 查询(Q):当你看到队员A准备投篮时,你的查询是“这个投篮会不会进?”
- 键(K):队员B和队员C的状态(比如他们是否在防守)作为键,反映了他们的表现和位置。
- 值(V):队员B和C的实际表现,比如他们的历史投篮命中率或者防守强度,作为值。
计算注意力权重:
- 你会判断队员A的投篮是否受到了B或C的影响。如果B在防守,队员A的投篮可能会受到压制;如果C在远离A,A投篮的机会可能更好。
- 这个判断过程类似于计算查询和键的相似度,确定A与B、C之间的关系。
结合全局特征:
- 比赛的整体情况(例如,比分、剩余时间、场上节奏等)就像全局特征矩阵M,帮助你综合判断整个比赛的动态。
输出结果:
- 通过结合这些信息,你的注意力会更集中在队员A的投篮上,理解他投篮成功的可能性。这个过程反映了全局时间注意力在捕捉时间相关性的功能。
场景:图像中的对象识别
想象我们有一幅图像,里面有多个对象,比如一个狗、一只猫和一个球。现在我们使用全局时间注意力来理解这些对象之间的关系。
注视点:
- 你可能对图像中的不同对象(狗、猫、球)进行注视。每个对象就是一个注视点。
查询、键、值的构建:
- 查询(Q):假设你现在关注的是“狗”,想要判断它在图像中的行为(例如,它是否在追球)。
- 键(K):键可以是图像中猫和球的特征,比如它们的位置、形状和颜色。这些信息帮助模型理解狗的行为可能受哪些因素影响。
- 值(V):与每个键对应的值可以是对象的详细信息,比如猫是否在静止或球的位置。
计算注意力权重:
- 模型计算狗的查询与猫和球的键之间的相似度。例如,狗的特征向量可能与球的特征向量更相似,因为狗可能在追球。这一过程类似于评估图像中对象之间的关系。
结合全局特征:
- 这里的全局特征可以是整个图像的上下文信息,比如图像的整体布局、背景和光照。这些特征帮助模型综合判断狗、猫和球之间的关系。
输出结果:
- 最终,结合后的输出会为狗的行为生成一个表示,说明它可能在追球,或者正在与猫互动。这个输出捕捉了对象之间的关系和动态。
Hadamard积(∘)的操作方法是什么

M掩码 是下三角矩阵的作用是什么
掩码矩阵 MMM 如果是下三角矩阵,主要用于控制自注意力机制中的信息流,确保模型在处理序列数据时遵循因果关系。具体作用如下:
1. 因果注意力
阻止未来信息泄露:在时间序列或文本处理任务中,模型在预测当前时刻的输出时,不应访问未来的信息。下三角矩阵的掩码确保在计算注意力时,只有当前和之前的时间步的信息被考虑,后面的时间步会被遮蔽。
保持时序一致性:这种设计使得模型的行为符合时间的顺序,使得模型在训练和推理时都能保持一致,避免由于未来信息影响当前决策而导致的错误。
2. 计算方式
- 实现方式:下三角矩阵通常是由 1 和 0 组成,1 表示可以访问的信息,0 表示不可以访问的信息。这样的设计确保在 softmax 计算注意力权重时,被遮蔽的部分会被设为一个很大的负值(如 −∞-\infty−∞),使得其在 softmax 后变为 0。
3. 实际例子
- 序列预测:在自然语言处理(NLP)任务中,如语言模型的训练,模型需要预测下一个单词。下三角掩码确保当前单词的预测只依赖于之前的单词,而不会看到后面的单词,保持生成过程的合理性。
系列消融研究
“系列消融研究”(Ablation Studies)是一种常用的实验方法,特别是在机器学习和深度学习领域,用于评估模型中不同组件的贡献。通过逐步移除或修改模型的某些部分,研究人员可以观察这些变化对模型性能的影响。
具体步骤
- 选择基准模型:首先构建一个完整的模型作为基准。
- 逐步消融:系统地移除或替换模型中的一个或多个组件。例如,可以去掉某个特定的注意力机制、特征提取层或正则化策略。
- 评估性能:对每个修改后的模型进行性能评估,通常会使用相同的数据集和指标进行比较。
- 分析结果:通过比较消融前后模型的性能变化,判断被移除或修改的组件对最终结果的贡献。
目的
- 理解模型的组成:帮助研究人员更好地理解模型各个部分的作用。
- 优化模型:通过识别出对性能贡献较小的部分,帮助优化模型架构。
- 验证假设:验证特定设计选择是否真的有效。
举例
如果你有一个视觉模型,可能会进行以下消融研究:
- 去掉注意力机制:观察模型性能是否下降。
- 替换特征提取层:用不同的卷积层替换当前层,看看性能变化。
- 修改超参数:改变学习率或正则化参数的设置,评估对训练效果的影响。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









