






 超级会员免费看
超级会员免费看
目录
引言
网络数据采集技术在当今信息时代具有重要研究价值,本文以番茄小说网为例,从技术学习角度详细介绍目录采集系统的实现原理。本项目采用Python编程语言,结合主流网络请求和解析库,为学习者提供网页数据提取的技术实践案例。
效果展示
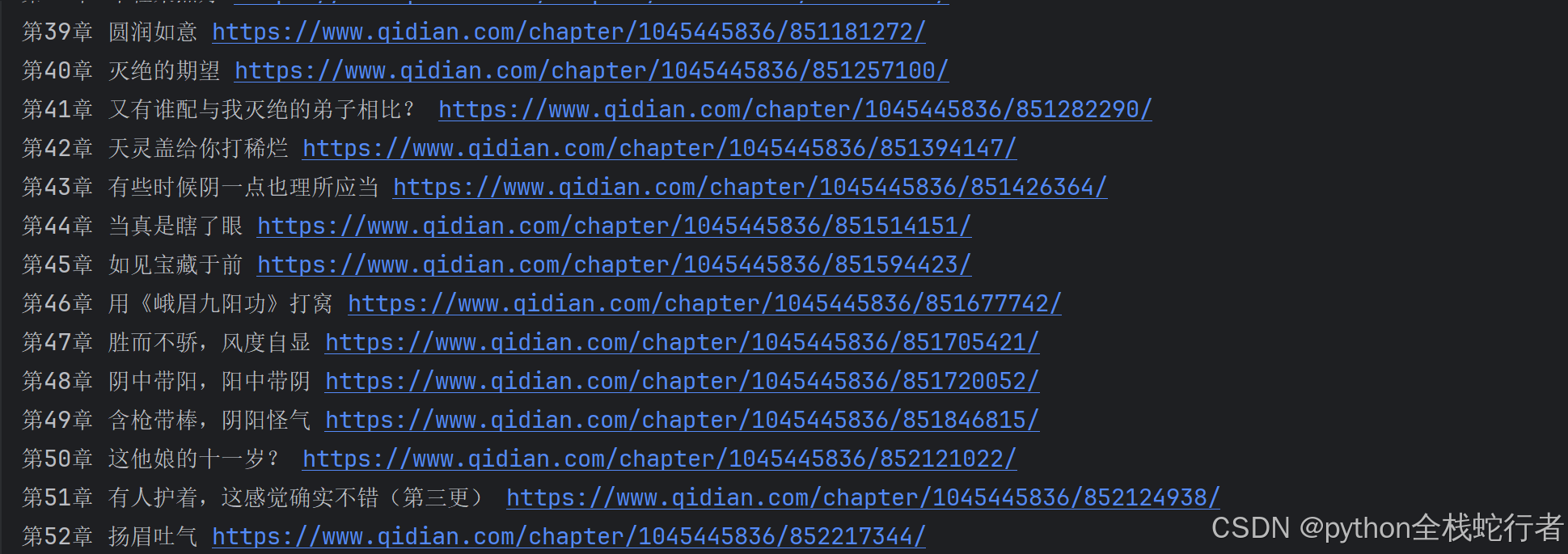
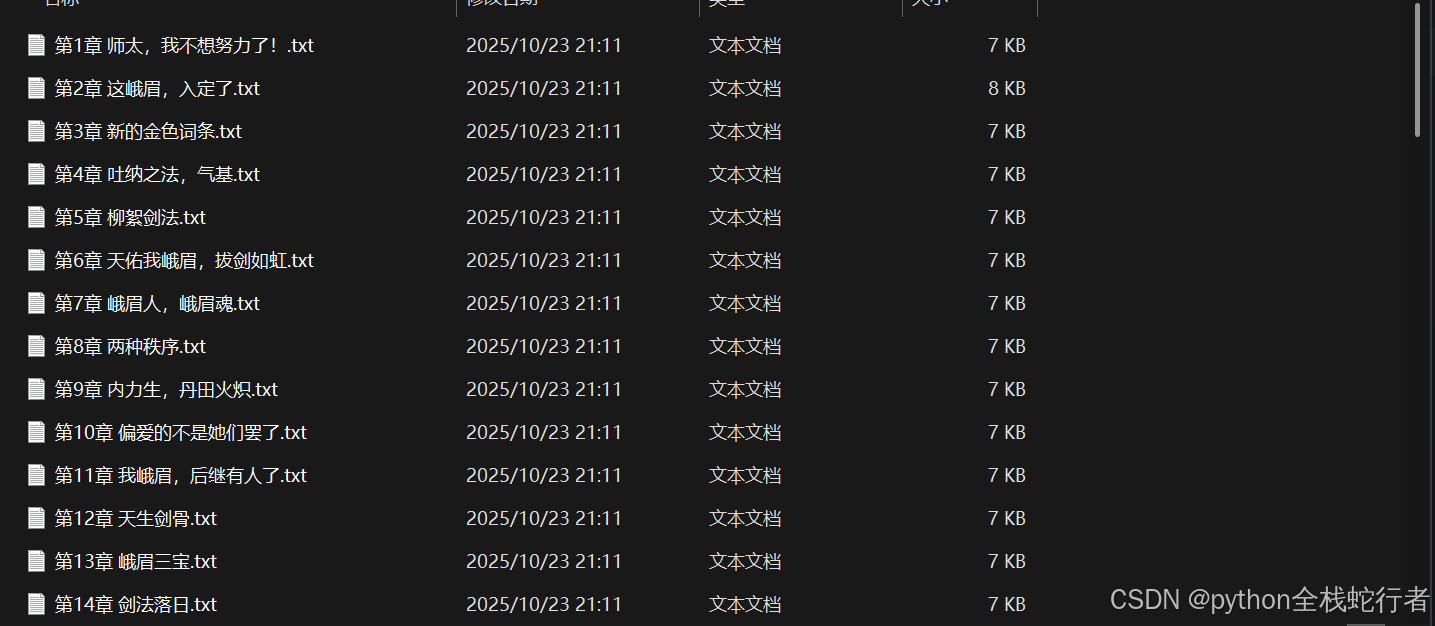
通过本项目实现的爬虫程序,可以自动完成以下功能:
-
自动访问小说目录页面
-
精准提取所有章节标题和链接

目录
网络数据采集技术在当今信息时代具有重要研究价值,本文以番茄小说网为例,从技术学习角度详细介绍目录采集系统的实现原理。本项目采用Python编程语言,结合主流网络请求和解析库,为学习者提供网页数据提取的技术实践案例。
通过本项目实现的爬虫程序,可以自动完成以下功能:
自动访问小说目录页面
精准提取所有章节标题和链接
 7697
2万+
1483
141
7697
2万+
1483
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文



























