






 超级会员免费看
超级会员免费看
scrapy项目-爬取某招聘网站信息
目标
网站:职位 | 网易社会招聘
需求
-
爬取python职位所有数据
-
爬取职位名称,职位类型,基本要求,基本学历,经验要求,地区
-
保存csv文件
步骤
-
分析网站,抓取数据包
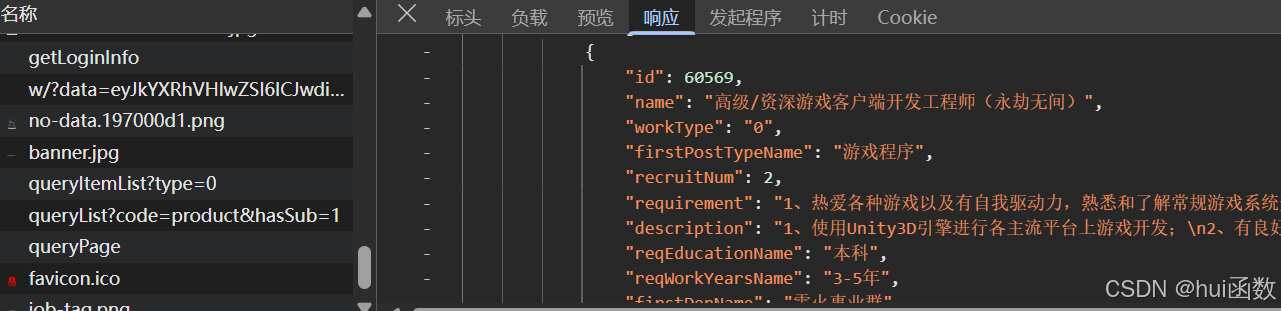
这里找到了就是queryPage数据包里面
-
看看请求需要带什么参数
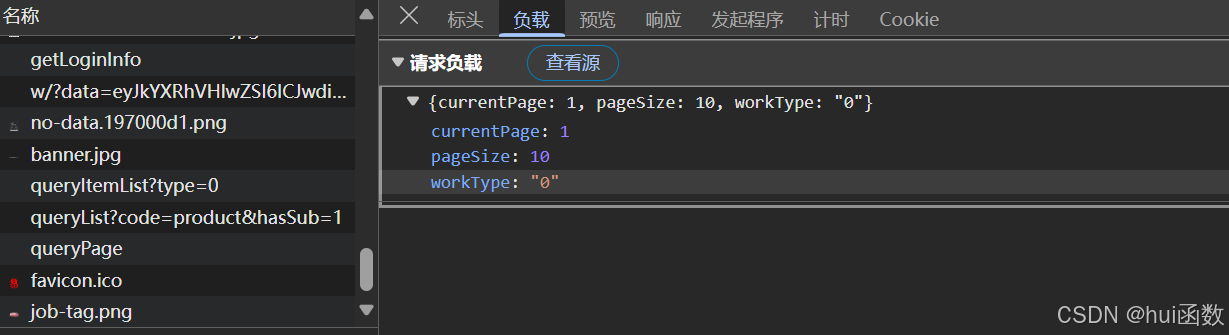
发现要带3个参数,先进行一页的抓取,然后再进行多页的抓取
-
创建scrapy项目,创建爬虫,开始写抓取第一页的代码,然后写分页数据
代码
spider/items.py

网站:职位 | 网易社会招聘
爬取python职位所有数据
爬取职位名称,职位类型,基本要求,基本学历,经验要求,地区
保存csv文件
分析网站,抓取数据包
这里找到了就是queryPage数据包里面
看看请求需要带什么参数
发现要带3个参数,先进行一页的抓取,然后再进行多页的抓取
创建scrapy项目,创建爬虫,开始写抓取第一页的代码,然后写分页数据
spider/items.py
 2914
1468
139
184
2914
1468
139
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























