




Linux深入理解内存管理27(基于Linux6.6)---内存管理 slub 算法介绍
一、概述
在 Linux 内核中,内存管理的核心机制之一是如何高效地分配和回收内存。内核采用了多种内存分配算法来优化这一过程,两个主要的内存分配算法是伙伴算法(Buddy Allocator)和SLUB 分配器(SLUB Allocator)。这两种算法各自用于不同的内存管理场景,协同工作以提高内核的内存分配效率。
1. 伙伴算法(Buddy Allocator)
伙伴算法用于页级内存的分配和回收,特别适合大块连续内存的分配。它的核心思想是将内存视为若干个页面(通常为4KB),并以2的幂次方的大小进行管理。每个内存块(或者页)被划分成不同大小的“伙伴”,这些伙伴具有相同的大小并且是连续的。
伙伴算法的工作原理:
- 内存块分割:当请求的内存大小不匹配时,内存分配器会将较大的内存块递归地分割成两个大小相同的小块(即伙伴)。例如,要求分配一个较小的内存块时,内存分配器会将一个更大的内存块分成两部分,直到找到一个恰好满足请求大小的内存块。
- 内存块合并:当内存被释放时,内核会检查是否存在与释放的内存块相邻的伙伴。如果相邻的伙伴空闲,两个伙伴可以合并成一个更大的块,进一步提高内存管理的效率。
伙伴算法的特点:
- 高效的内存合并和分割:伙伴算法的分割和合并过程是非常高效的,它通过递归分割(或者合并)来快速找到合适的内存块。
- 减少外部碎片:由于内存块的大小是2的幂次方,因此较大内存请求的内存块往往能够尽量减少内存碎片。
- 内存碎片问题:伙伴算法面临一个问题,即内部碎片。因为每次分配的内存块的大小是固定的2的幂次方,可能会导致分配的内存比实际需求稍大,产生一些空间浪费。
使用场景:
伙伴算法主要用于管理大块的连续内存,通常用于物理内存页面的分配,特别是在低层的内存管理(如页框分配)中发挥作用。
2. SLUB 分配器
SLUB 分配器(Simple List-based Unqueued Block Allocator)是 Linux 内核的高级内存分配器,它主要用于内核对象的内存分配,尤其是在多核系统中。SLUB 分配器是一种 基于缓存的内存分配器,它通过“缓存池”(kmem_cache)来管理和分配内存对象。
SLUB 分配器的工作原理:
- 缓存池:SLUB 分配器通过管理内核对象类型的缓存池(
kmem_cache)来分配和回收内存。每个缓存池对应一种内核对象(如struct task_struct或struct file)。每个缓存池内部包含多个内存页面,每个页面包含多个大小相同的对象。 - 内存对象分配:当需要分配一个内存对象时,SLUB 会从缓存池中分配空闲的内存对象。如果当前缓存池中的页面无法满足需求,SLUB 会向操作系统请求更多的内存页面来扩展缓存池。
- 对象回收:对象被释放时,会被标记为“可回收”,然后放回缓存池的空闲链表中。缓存池采用延迟回收的策略,不会立即合并和释放页面,而是根据系统负载的需要进行优化。
SLUB 的特点:
- 高效的内存管理:SLUB 的设计简洁且高效,特别是在多核处理器上表现优越。它减少了不同 CPU 核心之间的锁争用,提升了并发性能。
- 较低的锁竞争:与其他分配器(如 SLAB)相比,SLUB 分配器采用了更简化的设计,减少了内存分配中的锁竞争问题,适合大规模的并发环境。
- 延迟回收和合并:SLUB 分配器在回收内存时采用延迟回收策略,即不马上合并和释放内存,而是等到一定的条件满足时才回收,以减少系统的开销。
使用场景:
SLUB 分配器用于管理内核中需要频繁分配和回收的内存对象(如进程结构体、文件结构体、网络缓冲区等)。它提供了一个高效、灵活的内存管理机制,适合在内核中处理各种内存对象。
3. 伙伴算法与 SLUB 分配器的关系
- 伙伴算法的作用:伙伴算法主要用于管理和分配物理内存页面,它是内核低层次的内存分配算法,负责分配较大的、连续的内存块。
- SLUB 分配器的作用:SLUB 分配器则主要用于内核对象的分配,管理内存中的小块对象。SLUB 基于缓存池来实现内存对象的快速分配和回收,通常用于管理频繁分配和释放的内核数据结构。
两者的关系如下:
- 伙伴算法为 SLUB 提供了基础内存支持:SLUB 的缓存池最终需要通过伙伴算法来分配大块的物理内存页面。
- SLUB 分配器提高了内存管理的效率:SLUB 可以更高效地管理和分配内核中的小块对象,而伙伴算法则用于大块的内存分配。SLUB 能够在高并发环境下高效地工作,减少了对系统资源的争用。
4. Slub系统的框图
内核管理页面使用了2个算法:伙伴算法和slub算法,伙伴算法以页为单位管理内存,但在大多数情况下,程序需要的并不是一整页,而是几个、几十个字节的小内存。于是需要另外一套系统来完成对小内存的管理,这就是slub系统。slub系统运行在伙伴系统之上,为内核提供小内存管理的功能。
slub把内存分组管理,每个组分别包含 8、64、512、…2048个字节,在4K页大小的默认情况下,另外还有两个特殊的组,分别是96B和192B,共11组。之所以这样分配是因为如果申请2^12B大小的内存,就可以使用伙伴系统提供的接口直接申请一个完整的页面即可。
slub就相当于零售商,它向伙伴系统“批发”内存,然后在零售出去。一下是整个slub系统的框图:
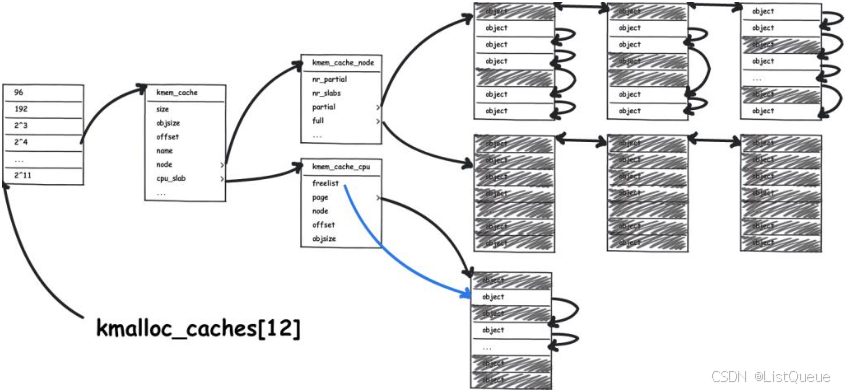
源于kmalloc_caches[12]这个数组,该数组的定义如下:
struct kmem_cache *kmalloc_caches[KMALLOC_SHIFT_HIGH + 1];
每个数组元素对应一种大小的内存,可以把一个kmem_cache结构体看做是一个特定大小内存的零售商,整个slub系统中共有12个这样的零售商,每个“零售商”只“零售”特定大小的内存,例如:有的“零售商”只"零售"8Byte大小的内存,有的只”零售“16Byte大小的内存。
每个零售商(kmem_cache)有两个“部门”,一个是“仓库”:kmem_cache_node,一个“营业厅”:kmem_cache_cpu。“营业厅”里只保留一个slab,只有在营业厅(kmem_cache_cpu)中没有空闲内存的情况下才会从仓库中换出其他的slab。
所谓slab就是零售商(kmem_cache)批发的连续的整页内存,零售商把这些整页的内存分成许多小内存,然后分别“零售”出去,一个slab可能包含多个连续的内存页。slab的大小和零售商有关。
二、Slub的分配原理
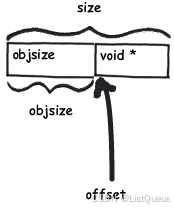
slub管理器从伙伴系统哪里每次批发2^order个页面,之后这些物理页面被按照对象大小(objsize)组织成单向链表。由于单项链表的指针要分配额外的存储空间,所以一个对象的实际大小要大约分配给程序使用的大小。kmem_cache中的size就表示实际大小,而objsize表示分配出去可以使用的大小。在多CPU的系统中,为了防止过多使用自旋锁带来的性能开销,每一个CPU有一个kmem_cache_cpu结构,仓库中货物主要是通过kmem_cache_cpu结构管理。oid*指向的是下一个空闲的object的首地址,这样object就连成了一个单链表。
- slub系统刚刚创建处理,第一次申请slub内存。
此时slub系统刚刚建立起来,营业厅(kmem_cache_cpu)和仓库(kmem_cache_node)中没有任何可用的slub可以使用,此时只能向伙伴同中申请可用的内存项,并把这些页面分成很多的object,取出其中一个object标志为已被占用,并返回给用户,其余的object标志为空闲并放在kmem_cache_cpu中保存。
- slub的kmem_cache_cpu中保存的slab上有空闲的object可以使用。
直接把kmem_cache_cpu中保存的一个空闲object返回给用户,并把freelist指向下一个空闲的object。
- kmem_cache_cpu中已经没有空闲的object了,但kmem_cache_node的partial中有空闲的object。
从kmem_cache_node的partial变量中获取有空闲object的slab,并把一个空闲的object返回给用户。
- 在kmem_cache_cpu和kmem_cache_node中都没有空闲页面了。
slub已经连续申请了很多页,现在kmem_cache_cpu中保存的物理页面上已经没有空闲的object可以使用了,而此时kmem_cache_node中也没有空闲页面了,只能向内存管理器(伙伴系统)申请slub,并把该slub初始化,返回第一个obect。
向slub系统释放内存块(object)时,如果kmem_cache_cpu中缓存的slab就是该object所在的slab,则把该object放在空闲链表中即可,如果kmem_cache_cpu中缓存的slab不是该object所在的slab,然后把该object释放到该object所在的slab中。在释放object的时候可以分为一下三种情况:
- object在释放之前slab是full状态的时候(slab中的object都是被占用的),释放该object后,这是该slab就是半满(partail)的状态了,这时需要把该slab添加到kmem_cache_node中的partial链表中。
- slab是partial状态时(slab中既有object被占用,又有空闲的),直接把该object加入到该slab的空闲队列中即可。
- 该object在释放后,slab中的object全部是空闲的,还需要把该slab释放掉。
在分配缓存块的时候,要分两种路径,fast path和slow path,也就是快速通道和普通通道。其中 kmem_cache_cpu 就是快速通道,kmem_cache_node 是普通通道。每次分配的时候,要先从 kmem_cache_cpu 进行分配。如果 kmem_cache_cpu 里面没有空闲的块,那就到 kmem_cache_node 中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。
三、Slub分配和释放API
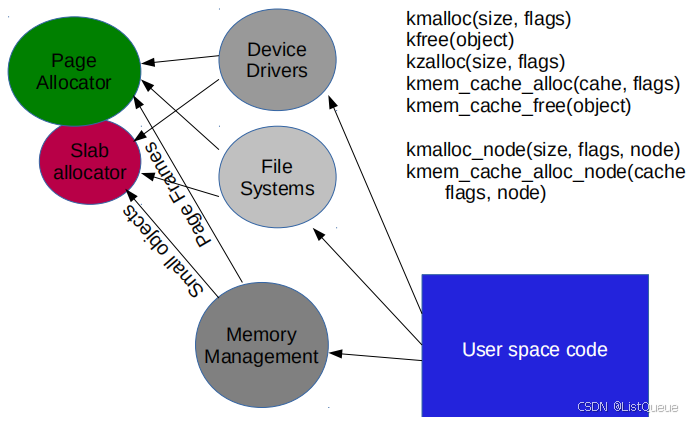
对于内核的申请内存,有两种方式,一种是通过伙伴系统申请page allocator,一种是通过slab allocatorr,对于内核有驱动模块,文件系统等方式会申请内存。其主要的方式有两种
- 提供特定类型的内核缓存方式
内核为专用高速缓存的申请和释放提供了一套完整的接口,根据所传入的参数为具体的对象分配 slab 缓存kmem_cache_create() 用于对一个指定的对象创建高速缓存。它从 cache_cache 普通高速缓存中为新的专有缓存分配一个高速缓存描述符,并把这个描述符插入到高速缓存描述符形成的 cache_chain 链表中kmem_cache_alloc() 在其参数所指定的高速缓存中分配一个 slab。相反, kmem_cache_free() 在其参数所指定的高速缓存中释放一个 slab
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,
unsigned int align, unsigned int flags,
void (*ctor)(void *));//创建slab描述符kmem_cache,此时并没有真正分配内存
- 供一般的内存分配方式,适合于所有的device drivers
kmalloc(size,flags)分配长度为size字节的一个内存区,并返回指向该内存区起始处的一个void指针,如果没有足够内存,则结果为NULL指针kfree(*ptr)释放 *ptr指向的内存区。
四、Kmalloc分配函数
__kmalloc,其处理流程如下:
mm/slab_common.c
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc_node(size, flags, NUMA_NO_NODE, _RET_IP_);
}
EXPORT_SYMBOL(__kmalloc);
static __always_inline
void *__do_kmalloc_node(size_t size, gfp_t flags, int node, unsigned long caller)
{
struct kmem_cache *s;
void *ret;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) {
ret = __kmalloc_large_node(size, flags, node);
trace_kmalloc(caller, ret, size,
PAGE_SIZE << get_order(size), flags, node);
return ret;
}
s = kmalloc_slab(size, flags);
if (unlikely(ZERO_OR_NULL_PTR(s)))
return s;
ret = __kmem_cache_alloc_node(s, flags, node, size, caller);
ret = kasan_kmalloc(s, ret, size, flags);
trace_kmalloc(caller, ret, size, s->size, flags, node);
return ret;
}
- 如果超过KMALLOC_MAX_CACHE_SIZE(如果为slub,则为2页),则使用伙伴系统通过kmalloc_large()函数从页面分配器分配页面。。
- 检索适当的kmalloc slab缓存。
- 获得kmalloc缓存中分配的。
/*
* Find the kmem_cache structure that serves a given size of
* allocation
*/
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{
unsigned int index;
if (size <= 192) {
if (!size)
return ZERO_SIZE_PTR;
index = size_index[size_index_elem(size)];
} else {
if (WARN_ON_ONCE(size > KMALLOC_MAX_CACHE_SIZE))
return NULL;
index = fls(size - 1);
}
return kmalloc_caches[kmalloc_type(flags)][index];
}
size为1至192,则使用已创建的size_index []表来计算索引,193至KMALLOC_MAX_SIZE(对于slub,则为2页),则将计算并返回所需的位数。
193〜256→8
257〜512→9
513〜1024 → 10
1025〜2048 → 11
2049〜4096 → 12
4097〜8192 → 13
- 最后如果开启了DMA内存配置且设置了GFP_DMA标志,将结合索引值通过kmalloc_dma_caches返回kmem_cache管理结构信息,否则将通过kmalloc_caches返回该结构。
由此可以看出kmalloc()实现较为简单,起分配所得的内存不仅是虚拟地址上的连续存储空间,同时也是物理地址上的连续存储空间。
slab(或slub/slob)对内存进行了二次管理,使系统可以申请小块内存。Slab先从buddy拿到数个页的内存,然后切成固定的小块(称为object),再分配出去。从/proc/slabinfo中可以看到系统内有很多slab,每个slab管理着数个页的内存,它们可分为两种:一个是各模块专用的,一种是通用的。
- 一类是内核里常用的数据结构,如TCPv6,UDPv6等,由于内核经常要申请和释放这类数据结构,所以就针对这些数据结构做一个slab,然后再次申请这类结构体时就总是从这个slab里来申请一个object(使用kmem_cache_alloc()申请)。
- 另一类是一些小粒度的内存申请,如slabinfo中的kmalloc-16,kmalloc-32等(使用kmalloc()申请)。
五、总结
5.1、SLUB算法的核心特点
-
基于缓存池的设计
- SLUB算法为每种类型的内核对象(如进程、文件、网络缓冲区等)创建一个缓存池(
kmem_cache)。 - 每个缓存池中包含多个内存页面(page),每个页面包含多个大小相同的对象(例如,
struct task_struct)。 - 通过缓存池管理内存对象,避免了频繁的内存分配和回收操作,从而提高了性能。
- SLUB算法为每种类型的内核对象(如进程、文件、网络缓冲区等)创建一个缓存池(
-
简化的内存分配过程
- 当需要分配内存时,SLUB首先检查该类型的缓存池中是否有空闲的对象。
- 如果有空闲对象,直接从缓存池中分配一个对象。
- 如果没有空闲对象,SLUB会尝试分配一个新的内存页面,并从该页面中获取对象。
-
延迟回收
- SLUB采用延迟回收的策略,不会在每次对象释放时立即合并内存页。
- 空闲的对象会被标记为可重用,但缓存池中的内存页面不会马上回收,只有在系统需要时,才会将空闲内存页面合并和释放。
-
减少锁竞争
- SLUB算法设计中,特别注重减少锁的竞争。每个CPU核心有自己独立的缓存池,减少了多个核心之间的锁竞争,提高了多核处理器上的性能。
- SLUB使用了局部空闲链表和偏移量技术,使得在多核系统中,分配器的性能得到显著提升。
-
合并缓存和分配对象的策略
- SLUB通过合并空闲对象和内存页面来减少内存碎片。缓存池内的内存对象会尽量填满内存页面,减少空闲空间。
- SLUB的缓存池会根据对象的大小来选择不同的分配策略,确保对象的分配和回收既高效又合理。
-
支持对象批量分配
- SLUB支持批量分配多个对象,适用于需要大量小对象分配的场景。这种批量分配策略使得SLUB在高负载下的性能更加稳定。
-
内存分配的高效性
- 相比于其他内存分配器(如SLAB),SLUB通过减少复杂的锁机制、优化内存对象的分配和回收过程,提供了更加高效的内存管理,尤其在多核处理器中表现优秀。
5.2、SLUB的内存管理流程
-
初始化和缓存池的创建
- 内核启动时,会根据每种内核对象的类型(如进程、文件、信号量等)创建相应的缓存池(
kmem_cache)。 - 每个缓存池会根据对象的大小来分配内存页面(通常是4KB或者更大)来存储该类型的对象。
- 内核启动时,会根据每种内核对象的类型(如进程、文件、信号量等)创建相应的缓存池(
-
内存对象的分配
- 当内核需要分配一个对象时,它首先检查该对象类型的缓存池,查找空闲对象。
- 如果缓存池内有空闲对象,则直接分配一个。
- 如果缓存池没有空闲对象,SLUB会分配一个新的内存页面,并从页面中分配多个对象。
-
对象的回收
- 当内核对象不再使用时,它们会被释放,并标记为“空闲”状态。
- 空闲对象会被放回缓存池中,等待下一次分配。
- SLUB采用延迟回收策略,这意味着不会立刻合并页面和回收内存,而是根据需要进行回收和合并。
-
内存页面的合并和回收
- 空闲的内存页面会被延迟回收,以减少频繁的内存合并操作。
- 当内核资源紧张时,SLUB会将空闲的内存页面合并,回收内存,减少内存的碎片。
5.3、SLUB算法的优缺点
优点:
-
高效性:
- SLUB在多核系统上表现优异,因为它减少了核心之间的锁竞争,提升了内存分配的并发性。
- 通过局部空闲链表和对象的批量分配,SLUB提供了更高效的内存管理机制。
-
简单性:
- SLUB的设计比SLAB简单,减少了复杂的内存管理逻辑,因此具有更低的内存开销和更快的分配速度。
-
减少内存碎片:
- 由于采用了合并空闲对象和内存页面的策略,SLUB在减少内存碎片方面做得较好。
-
延迟回收:
- 延迟回收策略减少了频繁的内存回收操作,使得内存管理过程更加平滑。
缺点:
-
内存浪费:
- 与SLAB算法相比,SLUB可能会因为过于简单的内存管理机制而导致少量内存浪费,特别是在小对象分配时。
-
无法做到完全零碎化:
- SLUB虽然有较好的内存合并和回收机制,但在某些特定场景下,可能仍会出现一些内存碎片,尤其是在对象的大小和数量差异较大的情况下。
5.4、SLUB与SLAB的比较
- 设计复杂度:SLUB比SLAB简单,维护的代码量少,降低了实现的复杂性。
- 性能:SLUB在多核系统上表现更优,锁竞争少,适合高并发的内存分配场景。
- 延迟回收:SLUB的延迟回收策略比SLAB更有优势,减少了不必要的合并和回收操作。
- 内存效率:SLAB通常会在性能和内存效率之间进行权衡,而SLUB在实现简洁性和性能方面更加均衡。
5.5、适用场景
- 高频内核对象分配:SLUB特别适用于内核中需要频繁分配和回收的对象,如进程、文件描述符、网络缓冲区等。
- 多核处理器系统:SLUB设计优化了多核系统中的内存分配,减少了锁竞争,适合高并发环境。
- 需要延迟回收的场景:SLUB的延迟回收机制非常适合大规模系统中不需要即时回收内存的情况。

















 2218
2218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









