




Linux深入理解内存管理5(基于Linux6.6)---缺页异常
一、概述
1. 缺页异常的概念
缺页异常(Page Fault)是指进程在执行过程中尝试访问一个尚未加载到物理内存中的页面时,由操作系统触发的异常。操作系统必须处理这个异常,通常通过将缺失的页面从磁盘或其他存储设备加载到内存来恢复正常运行。简单来说,缺页异常发生在进程试图访问一个它认为已经存在于内存中的虚拟地址,但该地址尚未被加载到内存时。
2. 虚拟内存和物理内存
现代操作系统通常使用虚拟内存机制来隔离各个进程,并为每个进程提供一个独立的地址空间。虚拟地址空间被划分为多个“页”(通常为4KB一页)。操作系统通过页表管理虚拟地址与物理内存之间的映射。物理内存中的每个页面可能不完全对应虚拟地址空间中的页面,这就是所谓的“分页”。
3. 缺页异常的触发条件
缺页异常通常在以下几种情况发生:
-
访问尚未加载到内存中的页面:当程序访问某个有效的虚拟地址,而该地址对应的页面不在物理内存中(例如,页面被换出到磁盘或从未加载过),操作系统会触发缺页异常。
-
访问非法地址:如果进程试图访问无效或不允许访问的虚拟地址(例如,访问未映射的地址或访问内核空间),也会触发缺页异常。
-
保护错误:如果进程以不允许的方式访问某些地址(例如,写入只读页面,或者访问属于其他进程的页面),这也会触发异常,但这类异常会根据错误类型区别处理。
4. 缺页异常的处理流程
当操作系统检测到缺页异常时,内核会根据异常的具体类型执行相应的处理。这个过程通常分为以下几个步骤:
(1) 异常检测:
- 进程执行指令时,处理器会发现某个虚拟地址没有映射到物理内存。此时,硬件会产生一个缺页异常中断。
(2) 异常的分类:
- 操作系统需要判断是有效页面缺失(需要从磁盘加载)还是非法访问(访问未映射或不允许访问的地址)。
(3) 查找页表:
- 操作系统查找当前进程的页表,确认虚拟地址的具体映射关系。如果页表中该虚拟地址有有效映射但页面不在内存中(例如,页面被交换到磁盘),操作系统会尝试将该页面加载到内存。
(4) 加载页面:
- 如果缺页是由于页面不在内存中,操作系统会从磁盘交换区、文件或其他存储设备中读取该页面,并将其加载到物理内存中。
- 操作系统需要修改页表,将页面的物理地址更新到相应的映射中。
(5) 恢复执行:
- 一旦页面被加载到内存,操作系统会恢复进程的执行,继续执行未完成的指令。
(6) 页面置换:
- 如果物理内存已经满了,操作系统可能需要通过页面置换(Page Replacement)算法(如LRU、FIFO等)来将某些不常用的页面换出到磁盘,以为新加载的页面腾出空间。
5. 缺页异常的类型
缺页异常可分为以下几种类型,具体的处理方式和产生的后果也有所不同:
-
有效页面缺失(Page Not Present):该页面在内存中没有,可能是由于页面被换出,或者是进程尝试访问尚未加载的页面。操作系统将从磁盘加载该页面。
-
写时复制(Copy-On-Write, COW):当多个进程共享某个页面时,如果一个进程尝试修改该页面,操作系统会触发缺页异常。此时,操作系统会复制该页面,使得修改的进程拥有一个独立的副本,而其他进程仍然共享原页面。
-
访问权限错误(Segmentation Fault / Protection Fault):如果进程尝试访问它没有权限访问的页面(如读取或写入只读页面,访问内核空间等),则操作系统会产生一个访问权限错误。进程通常会被终止。
-
堆栈溢出或栈空间错误:进程访问的虚拟地址超出了分配给它的栈空间,也会触发缺页异常,通常会导致程序崩溃。
二、缺页异常基本原理
进程A通过CPU访问虚拟地址VA,通过MMU找到对应的物理地址,当内存页在物理内存中没有对应的页帧或者存在但无对应的访问权限,在这种情况下,CPU就会报告一个缺页的错误。

Page Fault,指的是硬件错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等,当软件试图访问已映射在虚拟地址空间中,但目前并未加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。
缺页错误的分类:
- 硬件缺页(Hard Page Fault): 此时物理内存中没有对应的页帧,需要CPU打开磁盘设备读取到物理内存中,再让MMU建立VA和PA的映射
- 软缺页(Soft Page Fault): 此时物理内存中存在对应的页帧,只不过可能是其他进程调入,发生缺页异常的进程不知道,此时MMU只需要重新建立映射即可,无需从磁盘写入内存,一般出现在多进程共享内存区域
- 无效缺页(Invalid Page Falut): 比如进程访问的内存地址越界访问,空指针引用就会报段错误等
常见的场景:
- 地址空间映射关系未建立:
- 内核提供了很多申请内存的接口函数malloc/mmap,申请的虚拟地址空间,但是并未分配实际的物理页面,当首次访问的时候将会触发缺页异常
- 用户态的经常要进行地址访问,在进程刚创建运行时,页会伴随着大量的缺页异常,例如文件页(代码段/数据段)映射到进程地址空间,首次访问会产生缺页异常
- 地址空间映射已建立:
- 当访问的页面已经被swapping到磁盘,访问时触发缺页异常
- fork子进程时,子进程共享父进程的地址空间,写是触发缺页异常(COW技术)
- 要访问的页面被KSM合并,写时触发缺页异常(COW技术)
- 访问的地址空间不合法:
- 用户空间访问内核空间地址,触发缺页异常
- 内核空间访问用户空间地址,触发缺页异常
三、ARM缺页硬件支持
缺页处理的实现因处理器的不同而有所不同,本文以ARMV7的体系结构为例学习,大多数其他的CPU实现基本类似。

3.1、ARM 异常模式
首先ARM有好几种异常模式,其中一种是Data Abort。ARM v7 manual对这种异常的解释如下:
 发生在memory access阶段,在读/写数据、取指令或者访问页表时均有可能发生,对于红色的部分页就是对于虚拟内存管理的缺页支持。
发生在memory access阶段,在读/写数据、取指令或者访问页表时均有可能发生,对于红色的部分页就是对于虚拟内存管理的缺页支持。
3.2、ARM 页表结构

ARMV7的MMU支持两种类型的页表,短描述符和长描述符,长描述符是针对大物理地址的扩展,实际用的比较少,一般都是使用短描述符,它在转换中使用32Bit的描述符条目,并提供:
- 最多提供两级的地址查找
- 32Bit的输入地址
- 输出地址最多支持40Bits
- 主要是支持大物理地址扩展,可支持16MB
- 支持无访问权限等
- 32bit的页表条目
3.3、CP15寄存器
在看当MMU发生异常时候CP15寄存器的变化如下图:

- DFSR保存有关数据中止异常的信息
- DFAR保留一些同步数据中止异常的故障地址
- IFSR保留有关“预取中止”异常的信息
- IFAR保留“预取中止”异常的错误地址
这里提到保存信息的寄存有两个分别是DFSR和DFAR,DFAR中存放的是发生异常的VA,DFSR则存放的是发生异常的类型。

这里能看到有bit[10]、bit[3:0] 5个bit来表示FS(FAULT STATUS)。bit[11]来指明发生exception时是因为读指令还是写指令导致的。然后再看下FS支持哪些状态。


其对应到软件的fsr_info表。
arch/arm/mm/fsr-2level.c
// SPDX-License-Identifier: GPL-2.0
static struct fsr_info fsr_info[] = {
/*
* The following are the standard ARMv3 and ARMv4 aborts. ARMv5
* defines these to be "precise" aborts.
*/
{ do_bad, SIGSEGV, 0, "vector exception" },
{ do_bad, SIGBUS, BUS_ADRALN, "alignment exception" },
{ do_bad, SIGKILL, 0, "terminal exception" },
{ do_bad, SIGBUS, BUS_ADRALN, "alignment exception" },
{ do_bad, SIGBUS, 0, "external abort on linefetch" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "section translation fault" },
{ do_bad, SIGBUS, 0, "external abort on linefetch" },
{ do_page_fault, SIGSEGV, SEGV_MAPERR, "page translation fault" },
{ do_bad, SIGBUS, 0, "external abort on non-linefetch" },
{ do_bad, SIGSEGV, SEGV_ACCERR, "section domain fault" },
{ do_bad, SIGBUS, 0, "external abort on non-linefetch" },
{ do_bad, SIGSEGV, SEGV_ACCERR, "page domain fault" },
{ do_bad, SIGBUS, 0, "external abort on translation" },
{ do_sect_fault, SIGSEGV, SEGV_ACCERR, "section permission fault" },
{ do_bad, SIGBUS, 0, "external abort on translation" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "page permission fault" },
/*
* The following are "imprecise" aborts, which are signalled by bit
* 10 of the FSR, and may not be recoverable. These are only
* supported if the CPU abort handler supports bit 10.
*/
{ do_bad, SIGBUS, 0, "unknown 16" },
{ do_bad, SIGBUS, 0, "unknown 17" },
{ do_bad, SIGBUS, 0, "unknown 18" },
{ do_bad, SIGBUS, 0, "unknown 19" },
{ do_bad, SIGBUS, 0, "lock abort" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 21" },
{ do_bad, SIGBUS, BUS_OBJERR, "imprecise external abort" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 23" },
{ do_bad, SIGBUS, 0, "dcache parity error" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 25" },
{ do_bad, SIGBUS, 0, "unknown 26" },
{ do_bad, SIGBUS, 0, "unknown 27" },
{ do_bad, SIGBUS, 0, "unknown 28" },
{ do_bad, SIGBUS, 0, "unknown 29" },
{ do_bad, SIGBUS, 0, "unknown 30" },
{ do_bad, SIGBUS, 0, "unknown 31" },
};
四、缺页异常软件处理流程
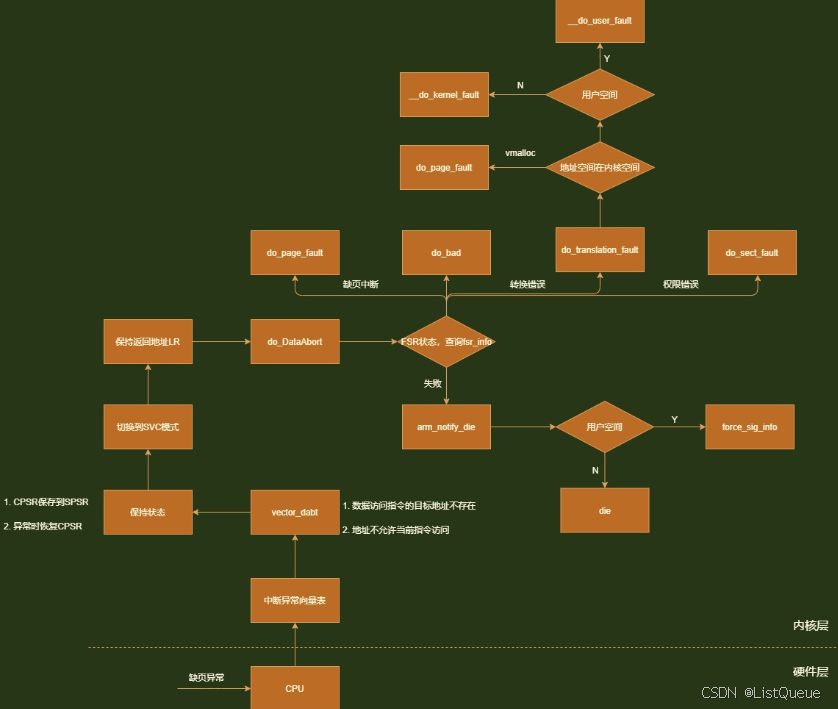
当进行存储访问时发生异常,基于ARMv7架构的处理器会跳转到异常向量表Data abort向量中,对于ARM处理器而言,当发生异常的时候,处理器会暂停当前指令的执行,保存现场,转而去执行对应的异常向量处的指令,当处理完该异常的时候,恢复现场,回到原来的那点去继续执行程序。系统所有的异常向量(共计8个)组成了异常向量表,该内容后面中断章节中在学习。异常发生时,ARM会自动跳转到异常向量表中,通过向量表中的跳转命令跳转到相应的异常处理中去。ARM的异常处理向量表在entry-armv.S文件中:
.L__vectors_start:
W(b) vector_rst
W(b) vector_und
W(ldr) pc, .L__vectors_start + 0x1000
W(b) vector_pabt
W(b) vector_dabt
W(b) vector_addrexcptn
W(b) vector_irq
W(b) vector_fiq
对于data abort,对应的跳转地址是vector_dabt + stubs_offset。这个地址的指令定义也在entry-armv.S
/*
* Data abort dispatcher
* Enter in ABT mode, spsr = USR CPSR, lr = USR PC
*/
vector_stub dabt, ABT_MODE, 8
.long __dabt_usr @ 0 (USR_26 / USR_32)
.long __dabt_invalid @ 1 (FIQ_26 / FIQ_32)
.long __dabt_invalid @ 2 (IRQ_26 / IRQ_32)
.long __dabt_svc @ 3 (SVC_26 / SVC_32)
.long __dabt_invalid @ 4
.long __dabt_invalid @ 5
.long __dabt_invalid @ 6
.long __dabt_invalid @ 7
.long __dabt_invalid @ 8
.long __dabt_invalid @ 9
.long __dabt_invalid @ a
.long __dabt_invalid @ b
.long __dabt_invalid @ c
.long __dabt_invalid @ d
.long __dabt_invalid @ e
.long __dabt_invalid @ f
- 如果进入data abort之前处于usr模式,那么跳转到dabt_usr
- 如果处于svc模式,那么跳转到dabt_svc;否则跳转到__dabt_invalid。
实际上,进入异常向量前Linux只能处于usr或者svc两种模式之一。这时因为irq等异常在跳转表中都要经过vector_stub宏,而不管之前是哪种状态,这个宏都会将CPU状态改为svc模式。

下面从v7_early_abort开始
ENTRY(v7_early_abort)
mrc p15, 0, r1, c5, c0, 0 @ get FSR
mrc p15, 0, r0, c6, c0, 0 @ get FAR
uaccess_disable ip @ disable userspace access
b do_DataAbort
ENDPROC(v7_early_abort)
ARM的MMU中有两个与存储访问失效有关的寄存器,前面已经学习过
- 失效状态寄存器(Data Fault Status Register,FSR)
- 失效地址寄存器(Data Fault Address Register, FAR)
当发生存储访问失效时,失效状态寄存器FSR会反映所发生存储失效的相关信息,包括存储访问所属域和存储访问类型等,同时失效地址寄存器会记录访问失效的虚拟地址。从v7_early_abort可知,addr是从CP15的c6获取,fsr是从CP15的c5获取;regs在__dabt_usr/__dabt_svc中从sp获取。
arch/arm/mm/fault.c
/*
* Dispatch a data abort to the relevant handler.
*/
asmlinkage void
do_DataAbort(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
const struct fsr_info *inf = fsr_info + fsr_fs(fsr);
if (!inf->fn(addr, fsr & ~FSR_LNX_PF, regs))
return;
pr_alert("8<--- cut here ---\n");
pr_alert("Unhandled fault: %s (0x%03x) at 0x%08lx\n",
inf->name, fsr, addr);
show_pte(KERN_ALERT, current->mm, addr);
arm_notify_die("", regs, inf->sig, inf->code, (void __user *)addr,
fsr, 0);
}
首先struct fsr_info数据结构用于描述一条失效状态对应的处理方案
struct fsr_info {
int (*fn)(unsigned long addr, unsigned int fsr, struct pt_regs *regs);
int sig;
int code;
const char *name;
};
其中,name成员表示这条失效状态的名称,sig表示处理失败时,Linux内核要发送的信号类型,fn表示要修复这条失效状态的函数指针。
arch/arm/mm/fsr-2level.c
// SPDX-License-Identifier: GPL-2.0
static struct fsr_info fsr_info[] = {
/*
* The following are the standard ARMv3 and ARMv4 aborts. ARMv5
* defines these to be "precise" aborts.
*/
{ do_bad, SIGSEGV, 0, "vector exception" },
{ do_bad, SIGBUS, BUS_ADRALN, "alignment exception" },
{ do_bad, SIGKILL, 0, "terminal exception" },
{ do_bad, SIGBUS, BUS_ADRALN, "alignment exception" },
{ do_bad, SIGBUS, 0, "external abort on linefetch" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "section translation fault" },
{ do_bad, SIGBUS, 0, "external abort on linefetch" },
{ do_page_fault, SIGSEGV, SEGV_MAPERR, "page translation fault" },
{ do_bad, SIGBUS, 0, "external abort on non-linefetch" },
{ do_bad, SIGSEGV, SEGV_ACCERR, "section domain fault" },
{ do_bad, SIGBUS, 0, "external abort on non-linefetch" },
{ do_bad, SIGSEGV, SEGV_ACCERR, "page domain fault" },
{ do_bad, SIGBUS, 0, "external abort on translation" },
{ do_sect_fault, SIGSEGV, SEGV_ACCERR, "section permission fault" },
{ do_bad, SIGBUS, 0, "external abort on translation" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "page permission fault" },
/*
* The following are "imprecise" aborts, which are signalled by bit
* 10 of the FSR, and may not be recoverable. These are only
* supported if the CPU abort handler supports bit 10.
*/
{ do_bad, SIGBUS, 0, "unknown 16" },
{ do_bad, SIGBUS, 0, "unknown 17" },
{ do_bad, SIGBUS, 0, "unknown 18" },
{ do_bad, SIGBUS, 0, "unknown 19" },
{ do_bad, SIGBUS, 0, "lock abort" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 21" },
{ do_bad, SIGBUS, BUS_OBJERR, "imprecise external abort" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 23" },
{ do_bad, SIGBUS, 0, "dcache parity error" }, /* xscale */
{ do_bad, SIGBUS, 0, "unknown 25" },
{ do_bad, SIGBUS, 0, "unknown 26" },
{ do_bad, SIGBUS, 0, "unknown 27" },
{ do_bad, SIGBUS, 0, "unknown 28" },
{ do_bad, SIGBUS, 0, "unknown 29" },
{ do_bad, SIGBUS, 0, "unknown 30" },
{ do_bad, SIGBUS, 0, "unknown 31" },
};
来看看fsr handler,其主要有以下有四种:
- 1.一级页表translation出错,段转换错误,即找不到二级页表,调用do_translation_fault
- 2.一级页表permisson出错,段权限错误,即二级页表权限错误,调用do_sect_fault
- 3.二级页表translation出错,页表错误,即线性地址无效,没有对应的物理地址,调用do_page_fault
- 4.二级页表permisson出错,页权限错误,调用do_page_fault
- 5.内核不支持的fault, 调用do_bad
4.1、内核不支持的fault
fsr_info数组列出了常见的地址失效处理方案,例如do_page_fault处理缺页中断,do_translation_fault处理转换错误,其他不能处理的默认为do_bad:
static int do_bad(unsigned long addr, unsigned int esr, struct pt_regs *regs)
{
return 1;
}
do_bad不做任何处理,返回1后再调用arm_notify_die后处理:
arch/arm/kernel/traps.c
void arm_notify_die(const char *str, struct pt_regs *regs,
int signo, int si_code, void __user *addr,
unsigned long err, unsigned long trap)
{
if (user_mode(regs)) {
current->thread.error_code = err;
current->thread.trap_no = trap;
force_sig_fault(signo, si_code, addr);
} else {
die(str, regs, err);
}
}
arm_notify_die函数判断当前处于Kernel模式还是User模式,
- 如果是Kernel模式直接die,打印内核死机信息,内核最终会挂死
- 如果是User模式,调用force_sig_info向进程强制发送fsr_info表中对应信号,强制发送信号可以忽略信号处理的SIG_IGN标记,和stask_struct的blocked域。进程收到信号后,接着进行coredump等流程。
4.2、内核支持的fault
对于这类都是由SIGSEGV导致的, SIGSEGV(Segment fault)意味着指针所对应的地址是无效地址,没有物理内存对应该地址,其中有分为以下两种
访问了具有错误权限的页面。例如,它是只读的,但是您的代码试图写入它。这将报告为SEGV_ACCERR
访问的页面甚至根本没有映射到应用程序的地址空间。这通常是由于取消引用空指针或使用小整数值损坏的指针引起的。报告为SEGV_MAPERR
1. 段权限错误do_sect_fault
do_sect_fault函数直接调用do_bad_area作处理,并返回0,所以不会再经过arm_notify_die。do_bad_area中,判断是否属于用户模式。如果是用户模式,调用__do_user_fault函数;否则调用__do_kernel_fault函数。
arch/arm/mm/fault.c
void do_bad_area(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk = current;
struct mm_struct *mm = tsk->active_mm;
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
if (user_mode(regs))
__do_user_fault(tsk, addr, fsr, SIGSEGV, SEGV_MAPERR, regs);
else
__do_kernel_fault(mm, addr, fsr, regs);
}
__do_user_fault中,会发送信号给当前线程,对于arm32位,可以通过CONFIG_DEBUG_USER将用户空间的栈打印出来,用于分析和debug
__do_kernel_fault则比较复杂,其流程最终会调用die函数处理oops
2. 段表错误
arch/arm/mm/fault.c
#ifdef CONFIG_MMU
static int __kprobes
do_translation_fault(unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
unsigned int index;
pgd_t *pgd, *pgd_k;
p4d_t *p4d, *p4d_k;
pud_t *pud, *pud_k;
pmd_t *pmd, *pmd_k;
if (addr < TASK_SIZE)
return do_page_fault(addr, fsr, regs);
if (user_mode(regs))
goto bad_area;
index = pgd_index(addr);
pgd = cpu_get_pgd() + index;
pgd_k = init_mm.pgd + index;
p4d = p4d_offset(pgd, addr);
p4d_k = p4d_offset(pgd_k, addr);
if (p4d_none(*p4d_k))
goto bad_area;
if (!p4d_present(*p4d))
set_p4d(p4d, *p4d_k);
pud = pud_offset(p4d, addr);
pud_k = pud_offset(p4d_k, addr);
if (pud_none(*pud_k))
goto bad_area;
if (!pud_present(*pud))
set_pud(pud, *pud_k);
pmd = pmd_offset(pud, addr);
pmd_k = pmd_offset(pud_k, addr);
#ifdef CONFIG_ARM_LPAE
/*
* Only one hardware entry per PMD with LPAE.
*/
index = 0;
#else
/*
* On ARM one Linux PGD entry contains two hardware entries (see page
* tables layout in pgtable.h). We normally guarantee that we always
* fill both L1 entries. But create_mapping() doesn't follow the rule.
* It can create inidividual L1 entries, so here we have to call
* pmd_none() check for the entry really corresponded to address, not
* for the first of pair.
*/
index = (addr >> SECTION_SHIFT) & 1;
#endif
if (pmd_none(pmd_k[index]))
goto bad_area;
copy_pmd(pmd, pmd_k);
return 0;
bad_area:
do_bad_area(addr, fsr, regs);
return 0;
}
#else /* CONFIG_MMU */
static int
do_translation_fault(unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
return 0;
}
#endif /* CONFIG_MMU */
do_translation_fault函数中,会首先判断引起abort的地址是否处于用户空间。
如果是用户空间地址,调用do_page_fault,转入和页表错误、页权限错误同样的处理流程。
如果是内核空间,继续向下作处理
3. 页表错误/页权限错误
对于页表错误(即线性地址无效,没有对应的物理地址)和页权限错误,都会调用到缺页异常的核心函数do_page_fault,熟悉几个概念:
对于处理器,总是处于以下的状态:
- 内核态:运行进程上下文,内核代表进程运行在内核空间
- 内核台:运行中断下上文,内核代表硬件运行在内核空间
- 用户态:运行在用户空间。
进程上下文、中断上下文、原子上下文对比:
| 上下文类型 | 概念 | 发生条件 | 做了什么(特点) |
|---|---|---|---|
| 进程上下文 | 是指进程在 CPU 上下文切换时,保存和恢复的寄存器、栈、程序计数器(PC)、内存映射等信息。 | 进程在运行时,操作系统进行进程调度时发生上下文切换。 | - 包括进程的寄存器状态、内存映射、打开的文件等。<br>- 切换时需要保存进程状态、加载新的进程状态。 |
| 中断上下文 | 是指在中断发生时,CPU 保存的上下文。它通常是在中断处理程序执行时保存的上下文信息。 | 设备中断、系统调用、软件中断等触发时。 | - CPU 会保存当前进程的上下文,并跳转到中断处理程序。<br>- 执行中断处理,处理完毕后恢复进程上下文继续执行。 |
| 原子上下文 | 是指操作系统在执行关键区段操作时,为避免中断干扰而保护的上下文。 | 在临界区、锁操作或某些操作系统内部的临界操作期间,确保操作不被中断。 | - 不允许中断打断的上下文。<br>- 原子操作通常是对资源的独占访问,不允许被打断,操作完成后才允许继续调度。 |
进一步解释:
-
进程上下文:
- 是指进程在执行时的所有信息。当操作系统进行进程调度时,当前进程的上下文会被保存(包括寄存器、程序计数器等),并且恢复到下一个被调度的进程中。
- 发生条件:进程调度时,操作系统必须保存当前进程的上下文,切换到另一个进程时恢复另一个进程的上下文。
-
中断上下文:
- 中断上下文是发生中断时的处理上下文,通常在设备中断、系统调用等情况发生时保存。它包含了被中断时的进程的所有必要信息,以便在处理中断后,能够恢复进程的状态继续执行。
- 发生条件:设备或软件中断发生时,CPU 会暂停当前进程并跳转到中断处理程序。
-
原子上下文:
- 原子上下文是指在执行一些关键操作时,防止中断发生的上下文。它用于保证在执行某些操作(如资源的修改、数据结构的更新等)时,操作不被中断打断,以避免不一致的状态。
- 发生条件:通常发生在临界区、临界区锁保护或某些内核代码需要独占资源时。
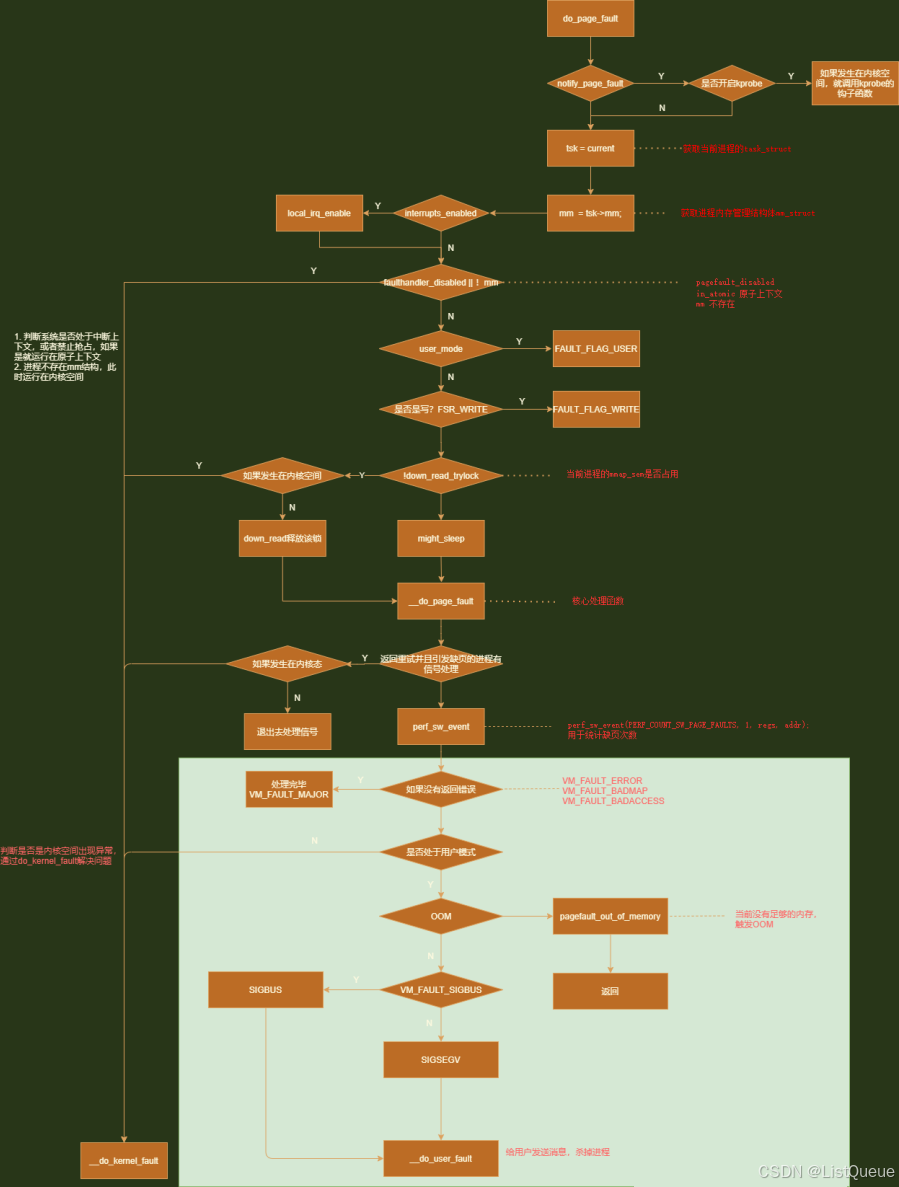 核心函数do_page_fault,其处理流程如上图所示,简述其处理过程:
核心函数do_page_fault,其处理流程如上图所示,简述其处理过程:
- in_atomic判断当前状态是否处于中断上下文或者禁止抢占状态,如果是,说明运行在原子上下文中,那么就跳转到内核处理异常接口__do_kernel_fault;同时如果当前进程没有struct mm_struct结构,说明这是一个内核线程,同样进入到__do_kernel_fault中
- 如果是用户模式,那么flags置位FAULT_FLAG_USER
- down_read_trylock判断当前的进程的mm->mmap_sem读写信号量释放可以获取,返回1是表示成功获取,返回0则表示被人占用,被人占用时分为两种情况
- 一种发生在内核空间,如果没有在exception_tables中查询到该地址,就跳转到do_kernel_fault
- 一种发生在用户空间,可以调用down_read来睡眠等待持有该锁的所有者释放该锁
- 通过__do_page_fault来完成查找合适的vma,并分配,并返回分配后的状态
- 如果没有返回错误类型,说明缺页中断处理完成,其他异常分为
- 如果返回错误,且当前处于内核模式,那么就跳转到__do_kernel_fault
- 如果错误类型是VM_FAULT_OOM,说明当前系统中没有足够的内存,那么就调用pagefault_out_of_memory函数来触发OOM机制
- 如果是VM_FAULT_SIGBUS,就调用__do_user_fault向用户空间发送SIGBUS信号,杀死进程,其他的错误则发送SIGSEGV的段错误,杀死进程
- 如果错误发生在内核模式,如果内核无法处理,那么只能调用__do_kernel_fault来处理
五、总结
本章主要是从发生缺页异常开始,软硬件的总体流程:
发生缺页异常时软硬件的总体流程总结:
1. 缺页异常的触发
当进程执行时,CPU会根据虚拟地址访问内存。每当CPU尝试访问一个虚拟地址,而该虚拟地址所对应的页面不在物理内存中时,就会发生缺页异常。硬件(CPU)会通过内存管理单元(MMU)检测到这一点,触发缺页异常中断,通知操作系统处理。
2. 硬件处理缺页异常
缺页异常发生后,硬件会产生一个异常(中断)信号,这个信号会被CPU识别并跳转到操作系统的异常处理代码。
- CPU产生中断:在内存访问过程中,CPU通过MMU检查虚拟地址是否已映射到物理内存。如果MMU发现没有对应的物理页面(即缺页),CPU会触发一个缺页异常中断(Page Fault Exception)。
- 中断向量:中断信号会被CPU转交给操作系统,CPU会根据中断向量跳转到操作系统内核的缺页异常处理程序。
3. 操作系统处理缺页异常
操作系统内核在接收到缺页异常中断后,进行一系列处理,以确保缺失的页面可以正确加载到内存中。这个处理过程通常包括以下步骤:
(1) 保存当前执行环境
- 操作系统首先保存当前进程的执行状态,包括程序计数器(PC)、寄存器和堆栈等,以便在恢复执行时能够从中断点继续。
(2) 检查页表
- 操作系统根据发生缺页异常的虚拟地址,检查进程的页表(Page Table),确定虚拟地址是否是有效的映射。
- 如果虚拟地址无效(例如非法访问未映射的地址),操作系统会产生一个访问权限错误,并可能终止进程。
- 如果虚拟地址是有效的,但页面不在物理内存中(例如被换出到磁盘),操作系统会继续处理页面调度。
(3) 选择页面调度策略
- 如果缺页异常是由于页面不在内存中,操作系统需要从磁盘或交换空间中将页面加载到内存。
- 页面置换(Page Replacement):如果物理内存已满,操作系统需要选择一个页框(Page Frame)来腾出空间给新页面。这通常通过页面置换算法(如LRU、FIFO等)来实现。
(4) 加载缺失页面
- 操作系统会通过磁盘I/O操作将缺失的页面从磁盘或交换空间(Swap Space)加载到物理内存中。
- 一旦页面加载完成,操作系统会更新页表,将虚拟地址与新的物理内存地址建立映射。
(5) 恢复执行
- 页表更新后,操作系统将恢复当前进程的执行,恢复到发生缺页异常的那条指令,并重新执行。此时,缺页异常已经被处理完毕,进程能够继续访问之前缺失的页面。
4. 硬件恢复执行
当操作系统处理完缺页异常后,会通知硬件恢复执行。此时,操作系统会执行以下步骤:
- 恢复上下文:操作系统恢复CPU的上下文(包括寄存器、程序计数器等),确保进程能够从异常发生的地方继续执行。
- 硬件恢复:CPU继续执行刚才被中断的指令。因为缺页异常已被处理完毕,页面已被加载到内存中,所以进程可以访问该页面,继续执行。
5. 补充:延迟加载与写时复制(COW)机制
-
写时复制(COW):在某些情况下,特别是多进程共享内存(如fork操作)时,操作系统可能会使用写时复制(Copy-On-Write)机制。即当多个进程共享同一页面时,只有在某个进程尝试修改页面时,才会触发缺页异常,操作系统会复制该页面,给该进程独立的副本,而其他进程继续共享原页面。
-
延迟加载(Lazy Load):某些操作系统可能会延迟加载页面,直到该页面被实际访问时才进行加载,这样可以节省内存空间,提高程序启动速度。
6. 性能优化与挑战
-
缺页率:频繁的缺页异常会导致系统性能下降,特别是在系统频繁进行页面交换时,可能出现**缺页抖动(Thrashing)**现象,严重时会导致系统响应迟缓。因此,操作系统会根据内存使用情况和应用的访问模式来优化页面置换策略,减少不必要的缺页异常。
-
页面预取(Prefetching):一些操作系统会根据进程的访问模式进行页面预取,即提前加载进程可能访问的页面,减少因缺页而造成的延迟。
-
页表管理和TLB优化:为加速虚拟地址到物理地址的转换,操作系统和硬件通常会配合使用**TLB(Translation Lookaside Buffer)**来缓存最近使用的页表条目。如果TLB命中,缺页异常不会发生,从而减少了缺页的开销。

















 2176
2176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









