




Linux深入理解内存管理6(基于Linux6.6)---请求缺页
一、概述
在 Linux 操作系统中,“请求调页”(Page Fault)是指当程序访问其虚拟地址空间中的某个页面时,如果该页面不在物理内存中(即缺页),操作系统会发生一个中断或异常,触发缺页异常处理程序,这个过程被称为页面调度或请求调页。操作系统根据页面调度的策略决定如何将所需的页面从磁盘或其他地方加载到内存中。
1. 请求调页的基本概述
在虚拟内存系统中,每个程序运行时都有一个虚拟地址空间,这个空间是程序可访问的内存地址范围。然而,程序所需的全部内存数据并不需要都加载到物理内存中。虚拟内存的使用使得操作系统可以把物理内存的使用管理得更加高效,通过请求调页技术动态加载和卸载内存中的页面。
当程序访问的虚拟地址对应的物理页面尚未加载(或者已经被交换到磁盘),就会发生“缺页异常”(Page Fault)。此时,操作系统会通过一系列的处理,将所需的页面调入物理内存中,直到缺页异常被处理完毕。
2. 请求调页的发生条件
- 程序访问虚拟地址时,发现该地址不在物理内存中。
- 可能的原因:
- 该虚拟页未分配,可能还没有加载到物理内存。
- 页表项指示该页面已经被交换到磁盘。
- 访问的是受保护的页面(例如,只读页面被写入)。
3. 请求调页的过程
请求调页的过程通常包括以下几个步骤:
-
触发缺页异常:当程序访问一个虚拟地址时,MMU(内存管理单元)检查该地址是否映射到物理内存。如果没有映射,触发缺页异常。
-
保存上下文:CPU 触发中断,保存当前进程的上下文,并将控制权交给操作系统的缺页处理程序。
-
缺页异常处理:
- 操作系统检查是哪种类型的缺页异常。
- 如果是由于页面未加载(未映射),操作系统会选择将该页面从磁盘或者交换空间加载到内存。
- 如果是由于页面权限问题(例如,写访问只读页面),操作系统会进行相应的错误处理。
-
页面加载:如果需要加载页面,操作系统会通过页表获取页面所在的磁盘位置(或交换空间),然后将其加载到内存中。这个过程可能涉及到磁盘 I/O 操作,将所需页面从磁盘读取到物理内存。
-
更新页表:一旦页面被加载,操作系统更新页表,将该虚拟地址对应的虚拟页面映射到实际的物理页面上。
-
恢复执行:页面加载完成后,恢复程序的执行。此时,程序能够继续访问该虚拟地址。
4. 页表与请求调页
每个进程都有自己的页表,页表保存了虚拟页面到物理页面的映射。当发生请求调页时,操作系统会通过页表查找相应的页面。如果虚拟页面不在物理内存中,页表的条目通常会指示该页面需要从磁盘或交换空间加载,或者该页面的访问权限发生了异常。
5. 请求调页的类型
-
缺页但页面可用:程序访问的虚拟页不存在于内存中,但操作系统发现该页面在磁盘或交换空间中是可用的,操作系统将其加载到内存中。
-
缺页且页面不可用(例如访问权限错误):访问的虚拟页面不可用,操作系统可能会发现该页面不存在,或者程序试图进行非法访问(如写入只读页面),此时操作系统会发出错误信号,导致进程被终止或其他错误处理。
-
缺页但已经交换出去:如果物理内存不足,操作系统可能会将不常用的页面交换到磁盘。当程序访问这些页面时,就会发生请求调页,操作系统将需要的页面从磁盘加载回内存。
6. 请求调页与性能
-
性能影响:请求调页通常会影响程序性能,因为磁盘 I/O 比内存访问慢得多。大量的页面调度(特别是频繁的页面交换)会导致系统性能下降,出现所谓的“抖动”现象。为了减少这种影响,操作系统使用了页面替换算法来决定哪些页面应该被换出,哪些应该保持在内存中。
-
TLB(Translation Lookaside Buffer)缓存:为了加速虚拟到物理地址的映射,现代处理器通常使用 TLB。当发生缺页时,TLB 可能会被检查,以避免频繁地访问页表。TLB 是硬件缓存,如果缓存命中,则可以避免缺页异常。
7. 请求调页相关技术
-
页面替换算法:当物理内存不足时,操作系统需要决定哪些页面应被换出,以便为新页面腾出空间。常见的页面替换算法有:
- FIFO(先进先出)。
- LRU(最近最少使用)。
- Clock 算法等。
-
懒加载:操作系统可以延迟加载某些页面,直到程序实际访问它们。这种方法被称为懒加载,是虚拟内存管理的一部分。它可以有效减少启动时的内存消耗,并且只有在需要时才加载页面,从而提高程序的启动速度。
-
大页(Huge Page):在某些场景下,操作系统支持大页内存映射技术,可以减少页表项的数量,提高内存管理效率。大页通常适用于需要大量内存的应用(如数据库或大规模科学计算)。
-
交换空间与交换文件:操作系统通过交换空间或交换文件来存储不常用的内存页面。当内存不足时,操作系统可以将部分页面移到磁盘,以释放内存给其他进程使用。
二、请求调页
请求调页是一种动态分配内存的策略, 把页面的分配推迟到不能再迟的时候, 一直推迟到进
程要访问的页不在物理内存时为止, 由此产生了一个缺页异常。 请求调页增加了系统中的空
闲页框的平均数, 从而更好的利用了空闲内存, 是系统具有更大的吞吐量。 但是页付出了系
统额外的开销, 由于请求缺页机制所发出的每一个缺页异常都是由内核处理, 导致了 CPU
的浪费。 同时由于程序的局部性保证了进程在一组页开始运行后, 在相当的一段时间内它都
会一直访问该页而不去访问其他的页, 所以就完成了系统的均衡。
请求调页策略的优缺点:
优点:
-
节省物理内存:
- 请求调页允许操作系统仅将需要的页面加载到内存中,这样可以节省物理内存空间。程序并不需要一次性将所有可能访问的页面都加载到内存中,减少了内存的占用。
-
增加虚拟内存的利用率:
- 通过请求调页,系统能够为每个程序提供一个比物理内存更大的虚拟地址空间。这意味着程序可以“访问”更大规模的数据集,虽然这些数据不一定都存储在物理内存中。
-
延迟加载(懒加载):
- 请求调页允许程序按需加载页面,即只有在程序实际访问某个页面时才将其加载到内存中。这样,可以提高程序启动速度,并减少不必要的内存消耗。
-
支持多任务:
- 请求调页使得操作系统能够高效地管理多个进程和线程,它通过虚拟内存机制为每个进程提供独立的地址空间,而无需担心物理内存限制。多个进程可以共享有限的内存资源,提升多任务的执行效率。
-
提升程序的容错性:
- 如果某些页面不常用或很少被访问,操作系统可以将这些页面暂时从内存中移除并交换到磁盘,从而确保重要的页面能够保持在内存中。这提高了程序对内存压力的容错性。
缺点:
-
性能下降(I/O瓶颈):
- 当程序访问不在内存中的页面时,操作系统需要从磁盘或交换空间加载页面。这种磁盘I/O操作通常比内存访问慢得多,可能导致性能显著下降,尤其是在磁盘速度较慢或内存压力较大的情况下。
-
频繁的页面交换(抖动问题):
- 如果系统内存较少且运行了多个程序,可能会出现频繁的页面调度和页面交换(即页面被换出又换入),这种情况称为抖动(Thrashing)。在这种情况下,操作系统大量的时间和资源被消耗在磁盘I/O上,导致进程几乎无法执行有意义的计算。
-
页面访问延迟:
- 请求调页会导致程序在访问尚未加载的页面时发生延迟。虽然现代操作系统通过使用预读机制和局部性原则来优化调页策略,但高频繁的缺页异常仍然会影响程序的响应时间和整体性能。
-
管理复杂性:
- 操作系统需要维护页表、处理页面替换、协调内存和磁盘之间的交互等,这增加了内存管理的复杂度。如果操作系统的调页算法不够高效或处理不当,可能会导致系统资源浪费和性能下降。
-
大页面交换开销:
- 如果请求调页涉及的页面较大(例如,处理大数据集的应用),则每次调页时的内存和磁盘I/O开销会更加显著,影响性能。
-
TLB缓存失效:
- 虚拟地址到物理地址的转换通常会通过**TLB(Translation Lookaside Buffer)**来加速。如果缺页异常发生,TLB缓存可能会被清空或失效,导致进一步的性能损失,特别是频繁的页面调度会使得TLB的命中率降低。
回顾下缺页异常, 在发生访问一个虚拟地址的时候发生了错误进入 do_page_faule 函数, 在
判断出【发生在用户空间、 不在中断中】 后, 为要映射到进程虚拟地址空间的页分配三级页
表中相应的页表入口指针, 然后调用真正处理页面错误的函数 handle_pte_fault。
mm/memory.c
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_lock (to exclude vma changes, but allow
* concurrent faults).
*
* The mmap_lock may have been released depending on flags and our return value.
* See filemap_fault() and __folio_lock_or_retry().
*/
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {---解析1
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
vmf->flags &= ~FAULT_FLAG_ORIG_PTE_VALID;
} else {
/*
* If a huge pmd materialized under us just retry later. Use
* pmd_trans_unstable() via pmd_devmap_trans_unstable() instead
* of pmd_trans_huge() to ensure the pmd didn't become
* pmd_trans_huge under us and then back to pmd_none, as a
* result of MADV_DONTNEED running immediately after a huge pmd
* fault in a different thread of this mm, in turn leading to a
* misleading pmd_trans_huge() retval. All we have to ensure is
* that it is a regular pmd that we can walk with
* pte_offset_map() and we can do that through an atomic read
* in C, which is what pmd_trans_unstable() provides.
*/
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_lock read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
vmf->flags |= FAULT_FLAG_ORIG_PTE_VALID;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
if (!vmf->pte) {---解析2
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))---解析3
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))---解析4
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry))) {
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & (FAULT_FLAG_WRITE|FAULT_FLAG_UNSHARE)) {---解析5
if (!pte_write(entry))
return do_wp_page(vmf);
else if (likely(vmf->flags & FAULT_FLAG_WRITE))
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {---解析6
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
- 1.首先看 pmd 是否存在, 如果不存在, 那么 pte 肯定也不存在; 如果存在, 那么就从 pmd中取出 pte, 在来判断 pte 是否存在。
- 2.如果 pte 不存在, 那么进程没访问过这个页, 但是没有建立和文件的映射关系, 就调用匿名映射 do_anonymous_page 处理函数, 例如用户空间的 malloc/mma 接口函数分配, 当使用到时候, 会产生缺页最终会走到该进口; 如果创建了映射关系, 就调用 do_fault, 运行完成后, 该过程返回。
- 3.到了这里说明这个 pte 上面还是有写东西的, 那么在页表项中的存在位就起到重要作用,为 1 时, 页不在主存中, 但是页表项保存了相关信息, 则表明该页被内核换出, 则要进行换入操作 do_swap_page, 运行完成过后, 该过程返回。
- 4.走到这说明物理页面存在的情况, 首先会通过 PRESENT 位并且用一个预留位来标示此页即将产生的 Page Fault 为 NUMA Page Fault 走到 do_numa_page。
- 5.linux 采用写时复制机制, 每一个页都需要有读写保护, 当有进程试图对具有写保护的页进行写操作的时候(因为共享不是你想写就能写的), 内核就会分配一个新的页框, 然后复制共享页框内容, 最终执行 do_wp_page, 这也是写时复制。
- 6.pte 内容发生变化, 需要把新的内容写入 pte 页表项中, 并且刷新 TLB 和 cache通过上边的分析, 我们发现 handle_pte_fault 函数的大部分功能是查看页的标志位识别出来。
什么原因引起了缺页异常, 然后转到各自的处理函数。
- 1.缺页错误且出错的页面还从未被映射到虚拟地址空间, 针对这种页面错误它会调用函数do_no_page 来进一步处理;
- 2.缺页错误但是出错的页面曾经被映射到虚拟地址空间, 也就是说这个页现在应该在 swapcache 中, 则调用 do_swap_page 函数;
- 3.页面写权限的错误, 主要是进程向一个共享页面进行写操作的处理, 当发生这种页面错误时, handle_pte_fault 会调用 do_wp_page 函数来处理。
至此已经对缺页中断主分支进行了分析, 下面介绍四种类型的缺页中断: 匿名页面、 文件页面、 交换页面和写时复制。
三、文件映射缺页
mm/memory.c
static vm_fault_t do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mm_struct *vm_mm = vma->vm_mm;
vm_fault_t ret;
/*
* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND
*/
if (!vma->vm_ops->fault) {---解析1
/*
* If we find a migration pmd entry or a none pmd entry, which
* should never happen, return SIGBUS
*/
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
/*
* Make sure this is not a temporary clearing of pte
* by holding ptl and checking again. A R/M/W update
* of pte involves: take ptl, clearing the pte so that
* we don't have concurrent modification by hardware
* followed by an update.
*/
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
} else if (!(vmf->flags & FAULT_FLAG_WRITE))---解析2
ret = do_read_fault(vmf);---解析3
else if (!(vma->vm_flags & VM_SHARED))
ret = do_cow_fault(vmf);
else
ret = do_shared_fault(vmf);---解析4
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}
文件映射缺页处理函数流程如下:
- 1.首先检查是否存在缺页处理函数, 如果不存在, 就发送信号, 所有的缺页最终都会走到对应的缺页处理函数中
- 2.flags 中不包含 FAULT_FLAG_WRITE, 说明是只读异常, 调用 do_read_fault()
- 3.VMA 的 vm_flags 没有定义 VM_SHARED,说明这是一个私有文件映射,发生了写时复制 COW,调用 do_cow_fault()
其余情况则说明是共享文件映射缺页异常, 调用 do_shared_fault()
以 handle_read_fault 为 流 程 梳 理 其 过 程 , handle_read_fault() 处 理 只 读 异 常FAULT_FLAG_WRITE 类型的缺页异常, 而对于共享和私有文件映射处理的方式流程基本类似。
如果需要写访问, 内核必须区分共享和私有映射。 对私有映射, 必须准备页的一份副本。 其
处理流程如下:
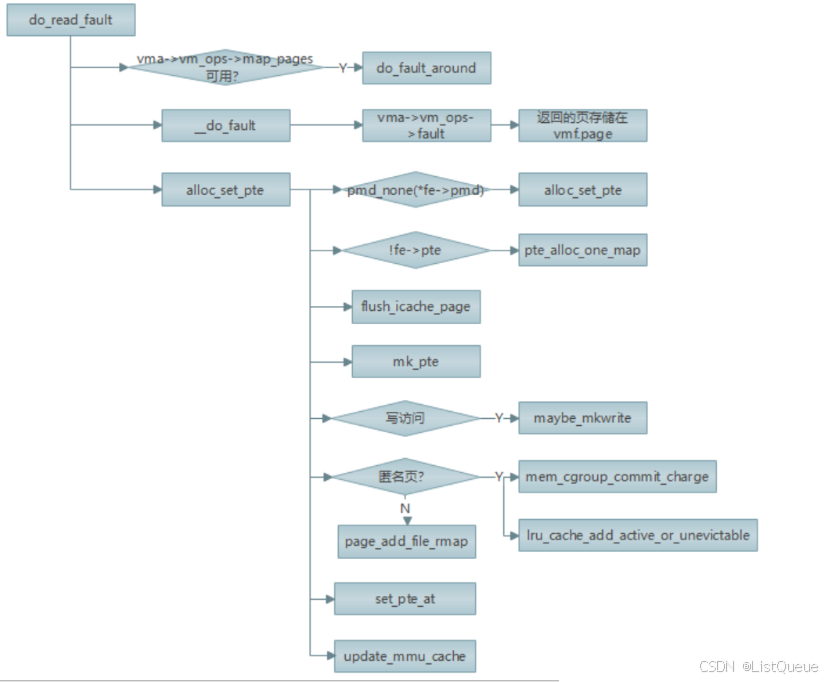
- 1.围绕在缺页异常地址周围提前映射尽可能多的页面, 提前建立进程地址空间和 page cache的映射关系有利于减少发生缺页终端的次数;
- 2.并调用 vma->vm_ops->fault 进行缺页处理(完成页面的调入工作),返回的页存储在 vmf.page中
- 3.拿到页存储地址后, 通过 pte_alloc 分配一个新页;
- 4.为了确保新页的内容在用户空间可见, 需要调用 flush_icache_page 更新缓存;
- 5.调用 mk_pte 获取指向只读页(刚刚获取的那一页)的页表项, 接着检查该页是否需要建立写权限(if (flags & FAULT_FLAG_WRITE)), 如果是,则调用 maybe_mkwrite 为该页显式设置写权限;
- 6.检查该页是否是匿名页, 如果是, 则调用 lru_cache_add_active 将该页加入到 LRU 缓存的活动区域, 接着调用 page_add_new_anon_rmap 将该页集成到逆向映射中。 如果是基于文件映射的页, 则调用 page_add_file_rmap 建立文件与页表项之间的逆向映射;
- 7.set_pte_at 生成新的 PTE Entry 设置到硬件页表项中;
- 8.调用 update_mmu_cache 更新处理器 MMU 缓存, 因为页表已经修改。
四、匿名页
对于没有关联到文件作为后备存储器的页, 需要调用 do_anonymous_page 进行映射。 除了
无需向页读入数据之外, 该过程几乎与映射基于文件的数据没什么不同。 在 highmem 内存
域建立一个新页,并清空其内容。接下来将页加入到进程的页表,并更新高速缓存或者 MMU。
五、写时复制
在尝试写一个 shared 的页的时候就会导致页面错误从而进入写时复制调用。 为什么要写时
复制呢? 比如 fork 这类的函数, 在创建新进程的时候会复制父进程的内容, 如果这时候就
完成真正的复制就太不划算了。 不仅是因为会浪费大量的 CPU 资源, 此时而是共享父进程
的内存页面, 父进程的页表被设为只读的, 当子进程进行写操作时, 会触发缺页异常, 为访
问只读页面的进程分配一个新的页面,并将原来页面的内容复制过来,页面的属性为可读写
mm/memory.c
static vm_fault_t do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
const bool unshare = vmf->flags & FAULT_FLAG_UNSHARE;
struct vm_area_struct *vma = vmf->vma;
struct folio *folio;
VM_BUG_ON(unshare && (vmf->flags & FAULT_FLAG_WRITE));
VM_BUG_ON(!unshare && !(vmf->flags & FAULT_FLAG_WRITE));
if (likely(!unshare)) {
if (userfaultfd_pte_wp(vma, *vmf->pte)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
return handle_userfault(vmf, VM_UFFD_WP);
}
/*
* Userfaultfd write-protect can defer flushes. Ensure the TLB
* is flushed in this case before copying.
*/
if (unlikely(userfaultfd_wp(vmf->vma) &&
mm_tlb_flush_pending(vmf->vma->vm_mm)))
flush_tlb_page(vmf->vma, vmf->address);
}
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);---解析1
if (!vmf->page) {
if (unlikely(unshare)) {
/* No anonymous page -> nothing to do. */
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
/*
* VM_MIXEDMAP !pfn_valid() case, or VM_SOFTDIRTY clear on a
* VM_PFNMAP VMA.
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable and/or call ops->pfn_mkwrite.
*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
return wp_pfn_shared(vmf);
pte_unmap_unlock(vmf->pte, vmf->ptl);
return wp_page_copy(vmf);
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
folio = page_folio(vmf->page);
if (folio_test_anon(folio)) {
/*
* If the page is exclusive to this process we must reuse the
* page without further checks.
*/
if (PageAnonExclusive(vmf->page))
goto reuse;
/*
* We have to verify under folio lock: these early checks are
* just an optimization to avoid locking the folio and freeing
* the swapcache if there is little hope that we can reuse.
*
* KSM doesn't necessarily raise the folio refcount.
*/
if (folio_test_ksm(folio) || folio_ref_count(folio) > 3)
goto copy;
if (!folio_test_lru(folio))
/*
* Note: We cannot easily detect+handle references from
* remote LRU pagevecs or references to LRU folios.
*/
lru_add_drain();
if (folio_ref_count(folio) > 1 + folio_test_swapcache(folio))
goto copy;
if (!folio_trylock(folio))
goto copy;
if (folio_test_swapcache(folio))
folio_free_swap(folio);
if (folio_test_ksm(folio) || folio_ref_count(folio) != 1) {
folio_unlock(folio);
goto copy;
}
/*
* Ok, we've got the only folio reference from our mapping
* and the folio is locked, it's dark out, and we're wearing
* sunglasses. Hit it.
*/
page_move_anon_rmap(vmf->page, vma);
folio_unlock(folio);
reuse:
if (unlikely(unshare)) {
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
wp_page_reuse(vmf);
return VM_FAULT_WRITE;
} else if (unshare) {
/* No anonymous page -> nothing to do. */
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
} else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {---解析2
return wp_page_shared(vmf);
}
copy:
/*
* Ok, we need to copy. Oh, well..
*/
get_page(vmf->page);
pte_unmap_unlock(vmf->pte, vmf->ptl);
#ifdef CONFIG_KSM
if (PageKsm(vmf->page))
count_vm_event(COW_KSM);
#endif
return wp_page_copy(vmf);---解析3
}
- 内核首先调用 vm_normal_page, 返回不可写的页的页描述符, 第一种情况是 zero_pfn 可;如果 vma 是共享且可写, 就可以直接通过 wp_page_share 该页;此时需要写时复制, 调用 wp_page_copy()完成操作。
- 读页, 返回 NULL, 将进入流程 2, 第二种情况是父进程共享也正常返回页描述符, 如果这vma 是可写且共享的, 就跳转到 wp_pfn_shared, 继续使用这个页面, 不做写时复制操作;
- 否则就跳转到 wp_page_copy()重新分配一个页面进行写时复制
写时复制的应用场合是访问映射的页不可写, 包括两种情况, 一种是 fork 导致, 另外一种
是 malloc 后第一次对它进行读操作, 获得 zero_pfn 是 NULL, 当再次写时需要写时复制, 如
果该页只有一个进程在用, 那么就直接修改这个页可写就行了, 不要搞做写时复制, 总之,
不到不得以的情况下是尽量不使用。
六、SWAP 换入页面
当内核在物理内存紧张的时候,内核内存回收机制将用户进程的特定的部分物理页通过交换
分区的方式写入磁盘或者文件(这部分会在后面的页面置换算法讲解), 然后将该页在交换分
区的标记写入到原页表代替页号, 并将页表项的驻留内存属性清 0。 当再次访问该页对应的
虚拟地址时候, 通过前面的流程梳理, 我们知道系统软件会通过 pte_present()函数来检查当
前页面的描述 entry 的 present 标志位, 由于该位已经被清 0, 那么就会发生交换缺页, 内核
就会分配新页给进程并通过页表项的交换标记位从磁盘将数据读入新页,从而完成缺页异常,
那么还是会区分以下情况:
- 1.如果仅有当前进程使用该页, 则从交换分区删去该页。
- 2.如果是由几个进程共享导致的的缺页, 为了不频繁的读写磁盘影响性能, 在交换分区之上构建交换页高速缓存, 在交换的换入换出都先操作换出, 然后再周期将没有被任何人访问页写到磁盘。
其主要的流程为:
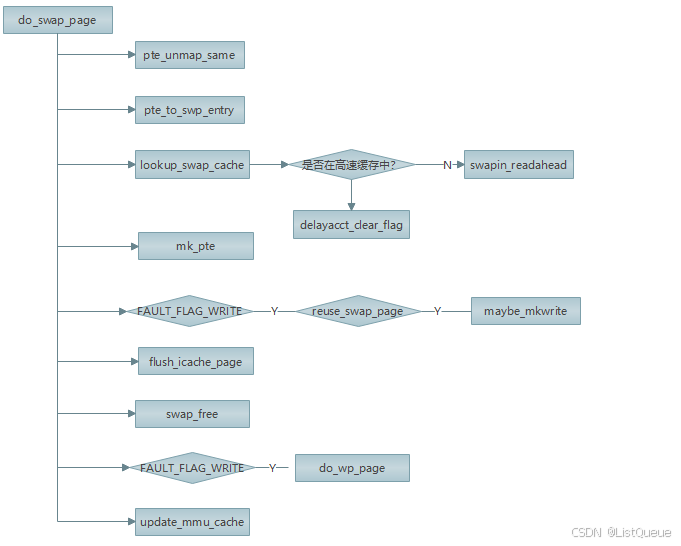
- 1.根据 pte 通过 pte_to_swp_entry 生成 swp_entry_t 类型, 然后通过 lookup_swap_cache 到交换 分 区 缓 存 找 到 已 分 配 且 尚 未 被 交 换 到 文 件 的 页 。 如 果 在 高 速 缓 冲 中 , 就 调 swapin_readahead 分配新的物理插入交换分区缓存, 然后从交换文件中读取数据存入新分配的页中。
- 2.如果不在高速缓冲中, 会分配新页给进程并通过页表项的交换标记位从磁盘将数据读入新页。
七、总结
缺页机制是操作系统在虚拟内存管理中的一种关键机制,其核心目标是动态地为进程的虚拟内存提供物理内存。具体来说,缺页机制通过请求分页(Page Fault)来管理内存,使得进程能够在访问尚未加载到内存的页面时,能够顺利地将这些页面加载到内存中。以下是该机制的主要总结:
1. 缺页异常(Page Fault):
- 缺页异常是指当进程访问某个虚拟地址时,操作系统发现该地址对应的页面不在内存中(即缺页)。操作系统通过触发缺页异常来处理这一问题。
2. 请求分页机制:
- 请求分页是虚拟内存管理的关键机制,操作系统根据进程的访问模式,只在进程真正需要某个页面时才将其从磁盘或交换空间加载到内存。这种按需加载的方式使得系统能够更加高效地使用物理内存。
3. 缺页处理流程:
- 当进程访问一个不在内存中的页面时,CPU会触发缺页异常,控制权交给操作系统。操作系统处理缺页异常的步骤一般如下:
- 检查缺页原因:操作系统首先检查是否该页面是有效的(例如,是否是进程的合法访问),以及是否有权限访问该页面。
- 找到页面所在位置:如果该页面位于磁盘、交换空间或其他存储设备上,操作系统需要定位该页面的位置。
- 页面调入内存:操作系统将所需页面从磁盘或交换空间加载到内存中的空闲页面框中。
- 更新页表:操作系统更新页表,标记该页面为已加载,并且更新进程的内存映射。
- 恢复进程执行:处理完缺页后,操作系统将控制权交还给进程,进程可以继续执行。
4. 请求分页的优点:
- 高效利用内存:请求分页可以按需加载页面,避免一次性将所有可能的页面加载到内存中,这样可以更有效地利用物理内存。
- 支持大规模虚拟内存:由于操作系统可以将不活跃的页面移出内存并存放在磁盘上,进程可以使用比物理内存更大的虚拟地址空间,提升了虚拟内存的扩展性。
- 提高启动速度:进程启动时,不需要一次性加载所有页面,只需加载执行所需的页面,可以加速启动过程。
5. 请求分页的缺点:
- 性能损耗:当页面不在内存中时,需要从磁盘加载页面,这会引起较大的延迟,尤其是在磁盘访问速度较慢时,可能显著降低程序的性能。
- 频繁的缺页导致的抖动(Thrashing):如果内存资源不足,频繁发生缺页异常,操作系统可能会花费大量时间在页面交换上,导致进程无法有效执行,表现为抖动现象。
- 硬件支持需求:有效的缺页处理通常需要硬件支持,如支持页表、**TLB(Translation Lookaside Buffer)**等机制,以提高页面查找和转换的效率。
6. 页面替换算法:
- 当内存空间不足,需要将不常用的页面交换出去时,操作系统需要决定哪些页面应该被替换。常见的页面替换算法包括:
- FIFO(先进先出):替换最早加载到内存的页面。
- LRU(最近最少使用):替换最长时间没有使用的页面。
- Optimal(最优):根据未来的页面访问模式来选择最合适的页面进行替换(理论上最佳,但通常不可实现)。
- Clock(时钟算法):模拟循环队列,用于近似LRU算法的替换方式。
7. 页面预读(Prefetching):
- 操作系统可以通过预读策略来优化缺页处理。在某些情况下,操作系统可以根据程序的访问模式提前加载某些页面,以减少因缺页导致的延迟。
8. 局部性原理:
- 请求分页机制的效果很大程度上依赖于程序的局部性原理。程序通常会具有时间局部性(近期访问的页面可能会再次访问)和空间局部性(相邻的页面可能会一起被访问)特征。操作系统可以根据这些特征来优化页面的调入和替换策略。
9. TLB(Translation Lookaside Buffer):
- TLB 是一种高速缓存,用于存储页表中最近使用的条目。通过在TLB中查找地址映射,操作系统可以加速虚拟地址到物理地址的转换,减少缺页异常的次数。如果发生缺页异常,操作系统需要更新TLB,以反映新的页面映射。
10. 缓存一致性和同步问题:
- 当页面在物理内存和磁盘之间进行交换时,可能会出现缓存一致性问题,特别是在多核处理器系统中。操作系统需要设计机制来确保多线程访问时,页面的缓存一致性和同步。

















 2955
2955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









