




Linux 网络子系统分析4(基于Linux6.6)---INET连接之bind & listen分析
一、概述
在 Linux 网络子系统中,bind 和 listen 是建立网络连接的两个重要系统调用,它们通常用于服务器端应用程序的网络服务设置。它们在套接字(socket)的生命周期中扮演着关键角色,帮助服务器端的程序准备好接收客户端的连接请求。下面将分别介绍 bind 和 listen 的功能、作用及其使用。
1. bind 概述
bind 系统调用用于将一个特定的 IP 地址和端口号与一个套接字(socket)关联起来。对于服务器应用程序来说,它通常用来指定其监听的本地端口和 IP 地址。通过 bind,服务器可以选择监听特定的 IP 地址或所有可用的网络接口。
2. listen 概述
listen 系统调用用于将一个已绑定(bind)的套接字转换为监听状态,使得套接字准备接受客户端的连接请求。调用 listen 后,套接字进入 监听队列,等待客户端发起的连接请求。它的作用是将套接字从一个普通的套接字转换为一个监听套接字。
二、bind
bind函数声明如下:
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
bind就是将addr和创建的socket进行绑定,对inet(man 7 ip)来说,一个进程想要接收报文就要和本地接口地址(local interface address)进行绑定,就是一个pair (address, port),如果 address指定为INADDR_ANY,则绑定本地所有接口。当然如果没有调用bind函数,在connect或者listen的时候都会以(INADDR_ANY, random port)自动绑定。如果是其他address family,bind的方式有所不同,具体用法参见man,下面来看一下bind如何解决不同address family对应的addr的统一,其对sockaddr的定义如下:
/*
* 1003.1g requires sa_family_t and that sa_data is char.
*/
struct sockaddr {
sa_family_t sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};
struct sockaddr_in {
__kernel_sa_family_t sin_family; /* Address family */
__be16 sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
/* Pad to size of `struct sockaddr'. */
unsigned char __pad[__SOCK_SIZE__ - sizeof(short int) -
sizeof(unsigned short int) - sizeof(struct in_addr)];
};
从上面可以看到,对于inet, 使用sockaddr_in{}对应sockaddr{}, 并以inet需要的地址(address, port) pair替代了sockaddr{}的sa_date域,这样再使用时强转一下就可以了。
接下来开始分析bind的实现,socket建立后,bind系统调用到inet_bind(sock->ops->bind)
net/ipv4/af_inet.c
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sock *sk = sock->sk;
u32 flags = BIND_WITH_LOCK;
int err;
/* If the socket has its own bind function then use it. (RAW) */
if (sk->sk_prot->bind) {
return sk->sk_prot->bind(sk, uaddr, addr_len);
}
if (addr_len < sizeof(struct sockaddr_in))
return -EINVAL;
/* BPF prog is run before any checks are done so that if the prog
* changes context in a wrong way it will be caught.
*/
err = BPF_CGROUP_RUN_PROG_INET_BIND_LOCK(sk, uaddr,
CGROUP_INET4_BIND, &flags);
if (err)
return err;
return __inet_bind(sk, uaddr, addr_len, flags);
}
EXPORT_SYMBOL(inet_bind);
sk->sk_prot->bind在tcp, udp协议下都是空,直接看__inet_bind(关键部分):
net/ipv4/af_inet.c
int __inet_bind(struct sock *sk, struct sockaddr *uaddr, int addr_len,
u32 flags)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
int chk_addr_ret;
u32 tb_id = RT_TABLE_LOCAL;
int err;
if (addr->sin_family != AF_INET) {
/* Compatibility games : accept AF_UNSPEC (mapped to AF_INET)
* only if s_addr is INADDR_ANY.
*/
err = -EAFNOSUPPORT;
if (addr->sin_family != AF_UNSPEC ||
addr->sin_addr.s_addr != htonl(INADDR_ANY))
goto out;
}
tb_id = l3mdev_fib_table_by_index(net, sk->sk_bound_dev_if) ? : tb_id;
chk_addr_ret = inet_addr_type_table(net, addr->sin_addr.s_addr, tb_id);
/* Not specified by any standard per-se, however it breaks too
* many applications when removed. It is unfortunate since
* allowing applications to make a non-local bind solves
* several problems with systems using dynamic addressing.
* (ie. your servers still start up even if your ISDN link
* is temporarily down)
*/
err = -EADDRNOTAVAIL;
if (!inet_addr_valid_or_nonlocal(net, inet, addr->sin_addr.s_addr,
chk_addr_ret))
goto out;
snum = ntohs(addr->sin_port);
err = -EACCES;
if (!(flags & BIND_NO_CAP_NET_BIND_SERVICE) &&
snum && inet_port_requires_bind_service(net, snum) &&
!ns_capable(net->user_ns, CAP_NET_BIND_SERVICE))
goto out;
/* We keep a pair of addresses. rcv_saddr is the one
* used by hash lookups, and saddr is used for transmit.
*
* In the BSD API these are the same except where it
* would be illegal to use them (multicast/broadcast) in
* which case the sending device address is used.
*/
if (flags & BIND_WITH_LOCK)
lock_sock(sk);
/* Check these errors (active socket, double bind). */
err = -EINVAL;
if (sk->sk_state != TCP_CLOSE || inet->inet_num)
goto out_release_sock;
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;
if (chk_addr_ret == RTN_MULTICAST || chk_addr_ret == RTN_BROADCAST)
inet->inet_saddr = 0; /* Use device */
/* Make sure we are allowed to bind here. */
if (snum || !(inet->bind_address_no_port ||
(flags & BIND_FORCE_ADDRESS_NO_PORT))) {
err = sk->sk_prot->get_port(sk, snum);
if (err) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
goto out_release_sock;
}
if (!(flags & BIND_FROM_BPF)) {
err = BPF_CGROUP_RUN_PROG_INET4_POST_BIND(sk);
if (err) {
inet->inet_saddr = inet->inet_rcv_saddr = 0;
if (sk->sk_prot->put_port)
sk->sk_prot->put_port(sk);
goto out_release_sock;
}
}
}
if (inet->inet_rcv_saddr)
sk->sk_userlocks |= SOCK_BINDADDR_LOCK;
if (snum)
sk->sk_userlocks |= SOCK_BINDPORT_LOCK;
inet->inet_sport = htons(inet->inet_num);
inet->inet_daddr = 0;
inet->inet_dport = 0;
sk_dst_reset(sk);
err = 0;
out_release_sock:
if (flags & BIND_WITH_LOCK)
release_sock(sk);
out:
return err;
}
这段函数主要将源IP和源port与对应的sk进行绑定,根据注释:
- inet->inet_rcv_saddr rcv_saddr is the one used by hash lookups
- inet->inet_saddr saddr is used for transmit
绑定时要确定(address, port) pair是否可用,具体调用sk->sk_prot->get_port(sk, snum),检测是否冲突,该接口在tcp和udp中是不同的,下面会分析
最终,该函数确定了四元组中的两个:inet_saddr, inet_sport
2.1、TCP bind
在tcp中,get_port对应的具体实现是inet_csk_get_port.
inet_csk_get_port是为指定的sock指定一个本地port,如果bind时没有指定,需要系统分配——奇数端口,偶数留给connect,bind使用hash表记录不同的二元组,hash结构的位置在proto{}中,
union {
struct inet_hashinfo *hashinfo;
struct udp_table *udp_table;
struct raw_hashinfo *raw_hash;
} ;
TCP使用inet_hashinfo{}
include/net/inet_hashtables.h
struct inet_hashinfo {
/* This is for sockets with full identity only. Sockets here will
* always be without wildcards and will have the following invariant:
*
* TCP_ESTABLISHED <= sk->sk_state < TCP_CLOSE
*
*/
struct inet_ehash_bucket *ehash;
spinlock_t *ehash_locks;
unsigned int ehash_mask;
unsigned int ehash_locks_mask;
/* Ok, let's try this, I give up, we do need a local binding
* TCP hash as well as the others for fast bind/connect.
*/
struct kmem_cache *bind_bucket_cachep;
/* This bind table is hashed by local port */
struct inet_bind_hashbucket *bhash;
struct kmem_cache *bind2_bucket_cachep;
/* This bind table is hashed by local port and sk->sk_rcv_saddr (ipv4)
* or sk->sk_v6_rcv_saddr (ipv6). This 2nd bind table is used
* primarily for expediting bind conflict resolution.
*/
struct inet_bind_hashbucket *bhash2;
unsigned int bhash_size;
/* The 2nd listener table hashed by local port and address */
unsigned int lhash2_mask;
struct inet_listen_hashbucket *lhash2;
bool pernet;
};
可以看到TCP使用三个hash表,分别是ehash,bhash,listening_hash,bind时用到bhash,其他用到在说,如下图:
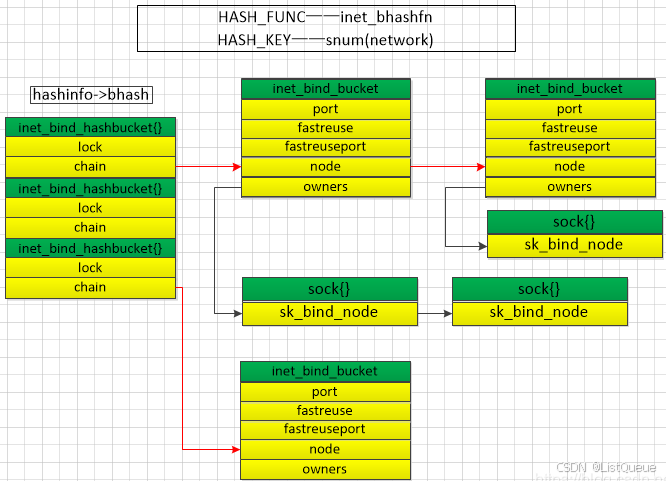 bind时根据snum进行hash,冲突时挂入inet_bind_bucket链表,这里考虑同一个port复用的情况——相同port放在同一个inet_bind_bucket中,如果可复用就加入到链表中(owners)。
bind时根据snum进行hash,冲突时挂入inet_bind_bucket链表,这里考虑同一个port复用的情况——相同port放在同一个inet_bind_bucket中,如果可复用就加入到链表中(owners)。
下面开始分析代码,先来看传入的sport是0的情况:
net/ipv4/inet_connection_sock.c
/* Obtain a reference to a local port for the given sock,
* if snum is zero it means select any available local port.
* We try to allocate an odd port (and leave even ports for connect())
*/
int inet_csk_get_port(struct sock *sk, unsigned short snum)
{
struct inet_hashinfo *hinfo = tcp_or_dccp_get_hashinfo(sk);
bool reuse = sk->sk_reuse && sk->sk_state != TCP_LISTEN;
bool found_port = false, check_bind_conflict = true;
bool bhash_created = false, bhash2_created = false;
int ret = -EADDRINUSE, port = snum, l3mdev;
struct inet_bind_hashbucket *head, *head2;
struct inet_bind2_bucket *tb2 = NULL;
struct inet_bind_bucket *tb = NULL;
bool head2_lock_acquired = false;
struct net *net = sock_net(sk);
l3mdev = inet_sk_bound_l3mdev(sk);
if (!port) {
head = inet_csk_find_open_port(sk, &tb, &tb2, &head2, &port);
if (!head)
return ret;
head2_lock_acquired = true;
if (tb && tb2)
goto success;
found_port = true;
} else {
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
spin_lock_bh(&head->lock);
inet_bind_bucket_for_each(tb, &head->chain)
if (inet_bind_bucket_match(tb, net, port, l3mdev))
break;
}
if (!tb) {
tb = inet_bind_bucket_create(hinfo->bind_bucket_cachep, net,
head, port, l3mdev);
if (!tb)
goto fail_unlock;
bhash_created = true;
}
if (!found_port) {
if (!hlist_empty(&tb->owners)) {
if (sk->sk_reuse == SK_FORCE_REUSE ||
(tb->fastreuse > 0 && reuse) ||
sk_reuseport_match(tb, sk))
check_bind_conflict = false;
}
if (check_bind_conflict && inet_use_bhash2_on_bind(sk)) {
if (inet_bhash2_addr_any_conflict(sk, port, l3mdev, true, true))
goto fail_unlock;
}
head2 = inet_bhashfn_portaddr(hinfo, sk, net, port);
spin_lock(&head2->lock);
head2_lock_acquired = true;
tb2 = inet_bind2_bucket_find(head2, net, port, l3mdev, sk);
}
if (!tb2) {
tb2 = inet_bind2_bucket_create(hinfo->bind2_bucket_cachep,
net, head2, port, l3mdev, sk);
if (!tb2)
goto fail_unlock;
bhash2_created = true;
}
if (!found_port && check_bind_conflict) {
if (inet_csk_bind_conflict(sk, tb, tb2, true, true))
goto fail_unlock;
}
success:
inet_csk_update_fastreuse(tb, sk);
if (!inet_csk(sk)->icsk_bind_hash)
inet_bind_hash(sk, tb, tb2, port);
WARN_ON(inet_csk(sk)->icsk_bind_hash != tb);
WARN_ON(inet_csk(sk)->icsk_bind2_hash != tb2);
ret = 0;
fail_unlock:
if (ret) {
if (bhash_created)
inet_bind_bucket_destroy(hinfo->bind_bucket_cachep, tb);
if (bhash2_created)
inet_bind2_bucket_destroy(hinfo->bind2_bucket_cachep,
tb2);
}
if (head2_lock_acquired)
spin_unlock(&head2->lock);
spin_unlock_bh(&head->lock);
return ret;
}
EXPORT_SYMBOL_GPL(inet_csk_get_port);
其核心函数inet_csk_find_open_port:
net/ipv4/inet_connection_sock.c
/*
* Find an open port number for the socket. Returns with the
* inet_bind_hashbucket locks held if successful.
*/
static struct inet_bind_hashbucket *
inet_csk_find_open_port(const struct sock *sk, struct inet_bind_bucket **tb_ret,
struct inet_bind2_bucket **tb2_ret,
struct inet_bind_hashbucket **head2_ret, int *port_ret)
{
struct inet_hashinfo *hinfo = tcp_or_dccp_get_hashinfo(sk);
int i, low, high, attempt_half, port, l3mdev;
struct inet_bind_hashbucket *head, *head2;
struct net *net = sock_net(sk);
struct inet_bind2_bucket *tb2;
struct inet_bind_bucket *tb;
u32 remaining, offset;
bool relax = false;
l3mdev = inet_sk_bound_l3mdev(sk);
ports_exhausted:
attempt_half = (sk->sk_reuse == SK_CAN_REUSE) ? 1 : 0;
other_half_scan:
inet_get_local_port_range(net, &low, &high);
high++; /* [32768, 60999] -> [32768, 61000[ */
if (high - low < 4)
attempt_half = 0;
if (attempt_half) {
int half = low + (((high - low) >> 2) << 1);
if (attempt_half == 1)
high = half;
else
low = half;
}
remaining = high - low;
if (likely(remaining > 1))
remaining &= ~1U;
offset = prandom_u32_max(remaining);
/* __inet_hash_connect() favors ports having @low parity
* We do the opposite to not pollute connect() users.
*/
offset |= 1U;
other_parity_scan:
port = low + offset;
for (i = 0; i < remaining; i += 2, port += 2) {
if (unlikely(port >= high))
port -= remaining;
if (inet_is_local_reserved_port(net, port))
continue;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
spin_lock_bh(&head->lock);
if (inet_use_bhash2_on_bind(sk)) {
if (inet_bhash2_addr_any_conflict(sk, port, l3mdev, relax, false))
goto next_port;
}
head2 = inet_bhashfn_portaddr(hinfo, sk, net, port);
spin_lock(&head2->lock);
tb2 = inet_bind2_bucket_find(head2, net, port, l3mdev, sk);
inet_bind_bucket_for_each(tb, &head->chain)
if (inet_bind_bucket_match(tb, net, port, l3mdev)) {
if (!inet_csk_bind_conflict(sk, tb, tb2,
relax, false))
goto success;
spin_unlock(&head2->lock);
goto next_port;
}
tb = NULL;
goto success;
next_port:
spin_unlock_bh(&head->lock);
cond_resched();
}
offset--;
if (!(offset & 1))
goto other_parity_scan;
if (attempt_half == 1) {
/* OK we now try the upper half of the range */
attempt_half = 2;
goto other_half_scan;
}
if (READ_ONCE(net->ipv4.sysctl_ip_autobind_reuse) && !relax) {
/* We still have a chance to connect to different destinations */
relax = true;
goto ports_exhausted;
}
return NULL;
success:
*port_ret = port;
*tb_ret = tb;
*tb2_ret = tb2;
*head2_ret = head2;
return head;
}
初始化阶段inet_get_local_port_range先获取系统配置的端口范围,[low, high + 1),这里先不考虑端口reuse的情况.接下来计算在端口范围内查找的起始offset,可以看到是在remain范围内随机产生的,最后要保证offset是奇数,因为偶数给connect用
net/ipv4/inet_connection_sock.c
other_parity_scan:
port = low + offset;
for (i = 0; i < remaining; i += 2, port += 2) {
if (unlikely(port >= high))
port -= remaining;
if (inet_is_local_reserved_port(net, port))
continue;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
spin_lock_bh(&head->lock);
if (inet_use_bhash2_on_bind(sk)) {
if (inet_bhash2_addr_any_conflict(sk, port, l3mdev, relax, false))
goto next_port;
}
head2 = inet_bhashfn_portaddr(hinfo, sk, net, port);
spin_lock(&head2->lock);
tb2 = inet_bind2_bucket_find(head2, net, port, l3mdev, sk);
inet_bind_bucket_for_each(tb, &head->chain)
if (inet_bind_bucket_match(tb, net, port, l3mdev)) {
if (!inet_csk_bind_conflict(sk, tb, tb2,
relax, false))
goto success;
spin_unlock(&head2->lock);
goto next_port;
}
tb = NULL;
goto success;
next_port:
spin_unlock_bh(&head->lock);
cond_resched();
}
offset--;
if (!(offset & 1))
goto other_parity_scan;
if (attempt_half == 1) {
/* OK we now try the upper half of the range */
attempt_half = 2;
goto other_half_scan;
}
if (READ_ONCE(net->ipv4.sysctl_ip_autobind_reuse) && !relax) {
/* We still have a chance to connect to different destinations */
relax = true;
goto ports_exhausted;
}
return NULL;
从随机选取的port = low + offset位置进行查找,保证遍历所有的奇数端口(),端口选择,根据随机的port hash选定一个slot,遍历slot上的链,这里的原则是,如果和port有冲突就重新选择port (next_port)那接下来看一下inet_csk_bind_conflict:
net/ipv4/inet_connection_sock.c
/* This should be called only when the tb and tb2 hashbuckets' locks are held */
static int inet_csk_bind_conflict(const struct sock *sk,
const struct inet_bind_bucket *tb,
const struct inet_bind2_bucket *tb2, /* may be null */
bool relax, bool reuseport_ok)
{
bool reuseport_cb_ok;
struct sock_reuseport *reuseport_cb;
kuid_t uid = sock_i_uid((struct sock *)sk);
rcu_read_lock();
reuseport_cb = rcu_dereference(sk->sk_reuseport_cb);
/* paired with WRITE_ONCE() in __reuseport_(add|detach)_closed_sock */
reuseport_cb_ok = !reuseport_cb || READ_ONCE(reuseport_cb->num_closed_socks);
rcu_read_unlock();
/*
* Unlike other sk lookup places we do not check
* for sk_net here, since _all_ the socks listed
* in tb->owners and tb2->owners list belong
* to the same net - the one this bucket belongs to.
*/
if (!inet_use_bhash2_on_bind(sk)) {
struct sock *sk2;
sk_for_each_bound(sk2, &tb->owners)
if (inet_bind_conflict(sk, sk2, uid, relax,
reuseport_cb_ok, reuseport_ok) &&
inet_rcv_saddr_equal(sk, sk2, true))
return true;
return false;
}
/* Conflicts with an existing IPV6_ADDR_ANY (if ipv6) or INADDR_ANY (if
* ipv4) should have been checked already. We need to do these two
* checks separately because their spinlocks have to be acquired/released
* independently of each other, to prevent possible deadlocks
*/
return tb2 && inet_bhash2_conflict(sk, tb2, uid, relax, reuseport_cb_ok,
reuseport_ok);
}
这里遍历tb->owners,检测冲突的条件。我们在bind时要限制(address, port)二元组的唯一性,bhash按照port进行hash,那么在port相同的条件下,检测冲突必然落在address的唯一性检查上,如下,如果sk和sk2相比较,只要满足下列任一条件,就会不产生冲突:
- sk是同一个 sk是同一个了就无所谓冲突了
- sk和sk2对应的sk_bound_dev_if 不是同一个 不同的端口自然对应不同的地址
- sk和sk2都指定sk_reuse,且此时sk2的状态不是TCP_LISTEN
- sk和sk2都指定sk_reuseport且此时sk2->sk_state状态是TCP_WAIT
- sk和sk2 IP地址不同 同一个端口上不同的地址
当然了,用户也可以指定reuse控制复用。
而下面的代码是说即使sk和sk2都指定sk_reuse,且此时sk2的状态不是TCP_LISTEN,在 !relax情况下,只要IP地址相等还是认为是冲突。
net/ipv4/inet_connection_sock.c
if (!inet_use_bhash2_on_bind(sk)) {
struct sock *sk2;
sk_for_each_bound(sk2, &tb->owners)
if (inet_bind_conflict(sk, sk2, uid, relax,
reuseport_cb_ok, reuseport_ok) &&
inet_rcv_saddr_equal(sk, sk2, true))
return true;
return false;
}
接下分析当成功分配了一个sport后的情形,有两种情况:
1. hash未冲突(head!=0, tb=NULL)这时候要为sport新建一个tb,走下面的流程
net/ipv4/inet_connection_sock.c
if (!tb) {
tb = inet_bind_bucket_create(hinfo->bind_bucket_cachep, net,
head, port, l3mdev);
if (!tb)
goto fail_unlock;
bhash_created = true;
}
if (!found_port) {
if (!hlist_empty(&tb->owners)) {
if (sk->sk_reuse == SK_FORCE_REUSE ||
(tb->fastreuse > 0 && reuse) ||
sk_reuseport_match(tb, sk))
check_bind_conflict = false;
}
if (check_bind_conflict && inet_use_bhash2_on_bind(sk)) {
if (inet_bhash2_addr_any_conflict(sk, port, l3mdev, true, true))
goto fail_unlock;
}
head2 = inet_bhashfn_portaddr(hinfo, sk, net, port);
spin_lock(&head2->lock);
head2_lock_acquired = true;
tb2 = inet_bind2_bucket_find(head2, net, port, l3mdev, sk);
}
if (!tb2) {
tb2 = inet_bind2_bucket_create(hinfo->bind2_bucket_cachep,
net, head2, port, l3mdev, sk);
if (!tb2)
goto fail_unlock;
bhash2_created = true;
}
if (!found_port && check_bind_conflict) {
if (inet_csk_bind_conflict(sk, tb, tb2, true, true))
goto fail_unlock;
}
可以看到首先新建了一个tb,此时tb一定是空的,不会执行tb_found流程,跳过去直接执行success流程。
net/ipv4/inet_connection_sock.c
success:
inet_csk_update_fastreuse(tb, sk);
if (!inet_csk(sk)->icsk_bind_hash)
inet_bind_hash(sk, tb, tb2, port);
WARN_ON(inet_csk(sk)->icsk_bind_hash != tb);
WARN_ON(inet_csk(sk)->icsk_bind2_hash != tb2);
ret = 0;
fail_unlock:
if (ret) {
if (bhash_created)
inet_bind_bucket_destroy(hinfo->bind_bucket_cachep, tb);
if (bhash2_created)
inet_bind2_bucket_destroy(hinfo->bind2_bucket_cachep,
tb2);
}
if (head2_lock_acquired)
spin_unlock(&head2->lock);
spin_unlock_bh(&head->lock);
return ret;
}
EXPORT_SYMBOL_GPL(inet_csk_get_port);
此时,tb下的链表tb->owner一定是空的,走else流程,这里关注tb上的两个字段:tb->fastreuse和tb->fastreuseport,前面说过满足下面任意一个条件一定不会产生冲突。
- sk和sk2都指定sk_reuse,且此时sk2的状态不是TCP_LISTEN。
- sk和sk2都指定sk_reuseport且此时sk2->sk_state状态是TCP_WAIT。
这两个标记的意思是如果标记置位,那么意味着tb的链中所有的sk都满足不产生冲突的条件,就不用再去调用很重的inet_csk_bind_conflict操作了,从而简化了判断过程。最后将sk挂入tb->owner进行管理,在这里源端口inet_num赋值,并记录tb。
net/ipv4/inet_hashtables.c
void inet_bind_hash(struct sock *sk, struct inet_bind_bucket *tb,
struct inet_bind2_bucket *tb2, unsigned short port)
{
inet_sk(sk)->inet_num = port;
sk_add_bind_node(sk, &tb->owners);
inet_csk(sk)->icsk_bind_hash = tb;
sk_add_bind2_node(sk, &tb2->owners);
inet_csk(sk)->icsk_bind2_hash = tb2;
}
2. hash冲突(head!=NULL,tb!=NULL)但是sport没有冲突,这时候省去了分配tb,执行tb_found流程,此时tb->owners一定不为空,为了方便看,再贴一下:
net/ipv4/inet_connection_sock.c
tb2 = inet_bind2_bucket_find(head2, net, port, l3mdev, sk);
inet_bind_bucket_for_each(tb, &head->chain)
if (inet_bind_bucket_match(tb, net, port, l3mdev)) {
if (!inet_csk_bind_conflict(sk, tb, tb2,
relax, false))
goto success;
spin_unlock(&head2->lock);
goto next_port;
}
tb = NULL;
goto success;
这里先进行的上面说的快速检索tb->fastreuse > 0 && reuse,sk_reuseport_match道理相同,但是其条件多一些,就封装成函数了。如果快速检索没有匹配,会再次调用inet_csk_bind_conflict检查冲突,注意这里和自动搜寻sport时参数是不一致的(false,false->true,true),上面是没有检查reuseport条件的,而且认为下面的代码是冲突行为:
net/ipv4/inet_connection_sock.c
if (!inet_use_bhash2_on_bind(sk)) {
struct sock *sk2;
sk_for_each_bound(sk2, &tb->owners)
if (inet_bind_conflict(sk, sk2, uid, relax,
reuseport_cb_ok, reuseport_ok) &&
inet_rcv_saddr_equal(sk, sk2, true))
return true;
return false;
}
接下来走success流程的tb非空还是在设置快速检索的方法,不再赘述。
继续分析bind指定了port的流程,流程上和前面差不多。
2.2、UDP bind
UDP获取端口的函数是udp_v4_get_port
net/ipv4/udp.c
int udp_v4_get_port(struct sock *sk, unsigned short snum)
{
unsigned int hash2_nulladdr =
ipv4_portaddr_hash(sock_net(sk), htonl(INADDR_ANY), snum);
unsigned int hash2_partial =
ipv4_portaddr_hash(sock_net(sk), inet_sk(sk)->inet_rcv_saddr, 0);
/* precompute partial secondary hash */
udp_sk(sk)->udp_portaddr_hash = hash2_partial;
return udp_lib_get_port(sk, snum, hash2_nulladdr);
}
接下来看udp_lib_get_port,还是先看bind未指定源端口的情况:
/**
* udp_lib_get_port - UDP/-Lite port lookup for IPv4 and IPv6
*
* @sk: socket struct in question
* @snum: port number to look up
* @hash2_nulladdr: AF-dependent hash value in secondary hash chains,
* with NULL address
*/
int udp_lib_get_port(struct sock *sk, unsigned short snum,
unsigned int hash2_nulladdr)
{
struct udp_table *udptable = sk->sk_prot->h.udp_table;
struct udp_hslot *hslot, *hslot2;
struct net *net = sock_net(sk);
int error = -EADDRINUSE;
if (!snum) {
DECLARE_BITMAP(bitmap, PORTS_PER_CHAIN);
unsigned short first, last;
int low, high, remaining;
unsigned int rand;
inet_get_local_port_range(net, &low, &high);
remaining = (high - low) + 1;
rand = get_random_u32();
first = reciprocal_scale(rand, remaining) + low;
/*
* force rand to be an odd multiple of UDP_HTABLE_SIZE
*/
rand = (rand | 1) * (udptable->mask + 1);
last = first + udptable->mask + 1;
do {
hslot = udp_hashslot(udptable, net, first);
bitmap_zero(bitmap, PORTS_PER_CHAIN);
spin_lock_bh(&hslot->lock);
udp_lib_lport_inuse(net, snum, hslot, bitmap, sk,
udptable->log);
snum = first;
/*
* Iterate on all possible values of snum for this hash.
* Using steps of an odd multiple of UDP_HTABLE_SIZE
* give us randomization and full range coverage.
*/
do {
if (low <= snum && snum <= high &&
!test_bit(snum >> udptable->log, bitmap) &&
!inet_is_local_reserved_port(net, snum))
goto found;
snum += rand;
} while (snum != first);
spin_unlock_bh(&hslot->lock);
cond_resched();
} while (++first != last);
goto fail;
} else {
hslot = udp_hashslot(udptable, net, snum);
spin_lock_bh(&hslot->lock);
if (hslot->count > 10) {
int exist;
unsigned int slot2 = udp_sk(sk)->udp_portaddr_hash ^ snum;
slot2 &= udptable->mask;
hash2_nulladdr &= udptable->mask;
hslot2 = udp_hashslot2(udptable, slot2);
if (hslot->count < hslot2->count)
goto scan_primary_hash;
exist = udp_lib_lport_inuse2(net, snum, hslot2, sk);
if (!exist && (hash2_nulladdr != slot2)) {
hslot2 = udp_hashslot2(udptable, hash2_nulladdr);
exist = udp_lib_lport_inuse2(net, snum, hslot2,
sk);
}
if (exist)
goto fail_unlock;
else
goto found;
}
scan_primary_hash:
if (udp_lib_lport_inuse(net, snum, hslot, NULL, sk, 0))
goto fail_unlock;
}
found:
inet_sk(sk)->inet_num = snum;
udp_sk(sk)->udp_port_hash = snum;
udp_sk(sk)->udp_portaddr_hash ^= snum;
if (sk_unhashed(sk)) {
if (sk->sk_reuseport &&
udp_reuseport_add_sock(sk, hslot)) {
inet_sk(sk)->inet_num = 0;
udp_sk(sk)->udp_port_hash = 0;
udp_sk(sk)->udp_portaddr_hash ^= snum;
goto fail_unlock;
}
sk_add_node_rcu(sk, &hslot->head);
hslot->count++;
sock_prot_inuse_add(sock_net(sk), sk->sk_prot, 1);
hslot2 = udp_hashslot2(udptable, udp_sk(sk)->udp_portaddr_hash);
spin_lock(&hslot2->lock);
if (IS_ENABLED(CONFIG_IPV6) && sk->sk_reuseport &&
sk->sk_family == AF_INET6)
hlist_add_tail_rcu(&udp_sk(sk)->udp_portaddr_node,
&hslot2->head);
else
hlist_add_head_rcu(&udp_sk(sk)->udp_portaddr_node,
&hslot2->head);
hslot2->count++;
spin_unlock(&hslot2->lock);
}
sock_set_flag(sk, SOCK_RCU_FREE);
error = 0;
fail_unlock:
spin_unlock_bh(&hslot->lock);
fail:
return error;
}
EXPORT_SYMBOL(udp_lib_get_port);
(address, port)之间的关系仍然是通过hash实现的,对应下面的udp部分:
union {
struct inet_hashinfo *hashinfo;
struct udp_table *udp_table;
struct raw_hashinfo *raw_hash;
struct smc_hashinfo *smc_hash;
} ;
struct udp_table {
struct udp_hslot *hash;
struct udp_hslot *hash2;
unsigned int mask;
unsigned int log;
};
2.3、bind tips
- 同一个socket多次绑定相同或者不同的端口
不允许重复bind或者绑定多个port,来自inet_bind,如果第一次绑定成功,对应的inet_sock的inet_num已经赋值,不允许继续执行了。
/* Check these errors (active socket, double bind). */
err = -EINVAL;
if (sk->sk_state != TCP_CLOSE || inet->inet_num)
goto out_release_sock;
- 不同的socket绑定相同的端口(同一个协议,udp)
三、Listen
只有tcp需要listen,其函数声明:
int listen(int sockfd, int backlog);
listen将socket标记为passive,表明已经准备好接受新的连接,其实就是将状态机的状态从TCP_CLOSE变成TCP_LISTEN,即执行一个被动打开操作。
net/ipv4/af_inet.c
/*
* Move a socket into listening state.
*/
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err, tcp_fastopen;
lock_sock(sk);
err = -EINVAL;
if (sock->state != SS_UNCONNECTED || sock->type != SOCK_STREAM)
goto out;
old_state = sk->sk_state;
if (!((1 << old_state) & (TCPF_CLOSE | TCPF_LISTEN)))
goto out;
WRITE_ONCE(sk->sk_max_ack_backlog, backlog);
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
/* Enable TFO w/o requiring TCP_FASTOPEN socket option.
* Note that only TCP sockets (SOCK_STREAM) will reach here.
* Also fastopen backlog may already been set via the option
* because the socket was in TCP_LISTEN state previously but
* was shutdown() rather than close().
*/
tcp_fastopen = READ_ONCE(sock_net(sk)->ipv4.sysctl_tcp_fastopen);
if ((tcp_fastopen & TFO_SERVER_WO_SOCKOPT1) &&
(tcp_fastopen & TFO_SERVER_ENABLE) &&
!inet_csk(sk)->icsk_accept_queue.fastopenq.max_qlen) {
fastopen_queue_tune(sk, backlog);
tcp_fastopen_init_key_once(sock_net(sk));
}
err = inet_csk_listen_start(sk);
if (err)
goto out;
tcp_call_bpf(sk, BPF_SOCK_OPS_TCP_LISTEN_CB, 0, NULL);
}
err = 0;
out:
release_sock(sk);
return err;
}
EXPORT_SYMBOL(inet_listen);
- 参数检查
- sk状态,处于TCP_CLOSE状态可以进入TCP_LISTEN状态,处于TCP_LISTEN状态根据后面的逻辑只允许设置sk_max_ack_backlog
接下来看核心部分,有一个TCP_FASTOPEN的概念,这是一个优化点,目前暂时不分析了。直接看inet_csk_listen_start
net/ipv4/inet_connection_sock.c
int inet_csk_listen_start(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err;
err = inet_ulp_can_listen(sk);
if (unlikely(err))
return err;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
/* There is race window here: we announce ourselves listening,
* but this transition is still not validated by get_port().
* It is OK, because this socket enters to hash table only
* after validation is complete.
*/
inet_sk_state_store(sk, TCP_LISTEN);
err = sk->sk_prot->get_port(sk, inet->inet_num);
if (!err) {
inet->inet_sport = htons(inet->inet_num);
sk_dst_reset(sk);
err = sk->sk_prot->hash(sk);
if (likely(!err))
return 0;
}
inet_sk_set_state(sk, TCP_CLOSE);
return err;
}
EXPORT_SYMBOL_GPL(inet_csk_listen_start);
首先,通过分配。
net/core/request_sock.c
/*
* Maximum number of SYN_RECV sockets in queue per LISTEN socket.
* One SYN_RECV socket costs about 80bytes on a 32bit machine.
* It would be better to replace it with a global counter for all sockets
* but then some measure against one socket starving all other sockets
* would be needed.
*
* The minimum value of it is 128. Experiments with real servers show that
* it is absolutely not enough even at 100conn/sec. 256 cures most
* of problems.
* This value is adjusted to 128 for low memory machines,
* and it will increase in proportion to the memory of machine.
* Note : Dont forget somaxconn that may limit backlog too.
*/
void reqsk_queue_alloc(struct request_sock_queue *queue)
{
spin_lock_init(&queue->rskq_lock);
spin_lock_init(&queue->fastopenq.lock);
queue->fastopenq.rskq_rst_head = NULL;
queue->fastopenq.rskq_rst_tail = NULL;
queue->fastopenq.qlen = 0;
queue->rskq_accept_head = NULL;
}
我们知道bind可以通过某种方式复用(address, port),这主要是针对客户端,由于客户端可以自行指定远端主机地址,因此绑定多个本地地址是没有问题的。但是对于服务端来说,只能确定一个(address, port),因为服务端是被动连接,它不能区分client的连接由那个app处理。实现该唯一绑定的途径就是listen
注意到,listen时再次调用了分配端口号函数,这是因为bind和listen调用之间有一个race window。从上面我们知道对于bind,即使是同一个(address, port)也能绑定成功(如指定了sk->reuse), 但是这两者不能同时listen成功,即不能有多个app同时监听同一个连接。那么当一个进程listen时,需要检测当前sk是不是还是可用的(因为可能在这个race windows中其他的sk已经将状态变成TCP_LISTEN, 或者清除了sk->reuse),总之,再次调用get_port就是要保证TCP_LISTEN状态的sk对端口的独占。
在调用get_port函数时,先将TCP状态设置为TCP_LISTEN,这是没有问题的,虽然有race window的存在,但是结果对我们并没有影响——get_port要么有一个成功,要么都不成功。
最终将sk加入到listening_hash中
net/ipv4/inet_hashtables.c
int inet_hash(struct sock *sk)
{
int err = 0;
if (sk->sk_state != TCP_CLOSE)
err = __inet_hash(sk, NULL);
return err;
}
EXPORT_SYMBOL_GPL(inet_hash);
int __inet_hash(struct sock *sk, struct sock *osk)
{
struct inet_hashinfo *hashinfo = tcp_or_dccp_get_hashinfo(sk);
struct inet_listen_hashbucket *ilb2;
int err = 0;
if (sk->sk_state != TCP_LISTEN) {
local_bh_disable();
inet_ehash_nolisten(sk, osk, NULL);
local_bh_enable();
return 0;
}
WARN_ON(!sk_unhashed(sk));
ilb2 = inet_lhash2_bucket_sk(hashinfo, sk);
spin_lock(&ilb2->lock);
if (sk->sk_reuseport) {
err = inet_reuseport_add_sock(sk, ilb2);
if (err)
goto unlock;
}
if (IS_ENABLED(CONFIG_IPV6) && sk->sk_reuseport &&
sk->sk_family == AF_INET6)
__sk_nulls_add_node_tail_rcu(sk, &ilb2->nulls_head);
else
__sk_nulls_add_node_rcu(sk, &ilb2->nulls_head);
sock_set_flag(sk, SOCK_RCU_FREE);
sock_prot_inuse_add(sock_net(sk), sk->sk_prot, 1);
unlock:
spin_unlock(&ilb2->lock);
return err;
}
EXPORT_SYMBOL(__inet_hash);
这里先不分析reuseport的情况了,只给出一张bind的示意图:
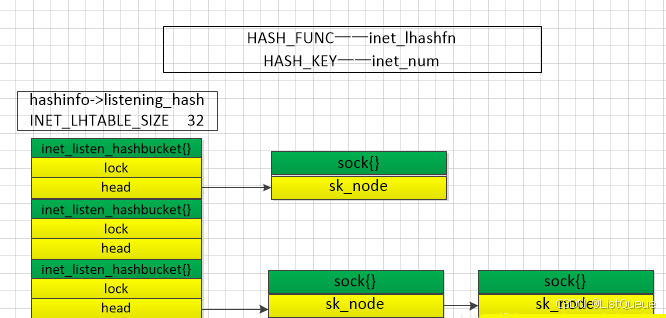
注意到inet_hash2(hashinfo, sk),对应hashinfo->lhash2,结构和上面一样,当lhash被初始化的时候,使用(address, port)作为key。
四、总结
bind的作用是将(address, port)二元组和socket绑定,Linux实现中使用bhash这个以sport为key的hash函数来保证唯一性。所以当涉及到二元组的冲突检测时,一个条件是如果bhash冲突,那么优先考虑address是否是不同的:这体现在同一个网口的不同address或者不同网口不同address。当二元组完全相同的时候,还可以根据是否指定reuse,reuseport来进一步决定是否能复用。
虽然允许bind多个地址,但想要套接字进入监听状态,就一定要保证进程对socket是独占的,即不再允许复用,如果允许多个socket进入监听状态,那么用户连接来了不能确定那个进程。使用listen来完成这一功能。而listen的也对全连接队列的设置有影响,即指定完成三次握手sock最多的个数。
bind 的作用:
- 将套接字与特定地址关联:服务器通过
bind系统调用将自己的 IP 地址和端口号绑定到套接字上。通常,服务器会选择一个端口来监听客户端的连接请求。 - 确定可用的 IP 和端口:如果服务器希望在某个特定的网络接口(例如局域网接口)上监听,而不是所有接口(默认情况下是所有网络接口),就可以通过
bind指定目标 IP 地址。
示例代码(IPv4):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int sockfd;
struct sockaddr_in server_addr;
// 创建套接字
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
exit(1);
}
// 配置服务器地址
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY; // 监听所有网络接口
server_addr.sin_port = htons(8080); // 监听 8080 端口
// 绑定套接字
if (bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
exit(1);
}
printf("Server bound to port 8080\n");
close(sockfd);
return 0;
}
listen 的作用:
- 进入监听状态:
listen将套接字从普通的 "主动套接字" 转变为 "被动套接字",表示该套接字已经准备好接收连接。 - 指定连接排队的数量:
backlog参数控制等待队列的大小,即在调用accept之前,最多有多少客户端连接可以处于等待状态。一般来说,backlog的大小在系统中有一定的限制,操作系统通常会对其进行处理。
示例代码(listen):
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main() {
int sockfd;
struct sockaddr_in server_addr;
// 创建套接字
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
exit(1);
}
// 配置服务器地址
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = INADDR_ANY;
server_addr.sin_port = htons(8080);
// 绑定套接字
if (bind(sockfd, (struct sockaddr *)&server_addr, sizeof(server_addr)) < 0) {
perror("bind");
exit(1);
}
// 启动监听
if (listen(sockfd, 5) < 0) {
perror("listen");
exit(1);
}
printf("Server is listening on port 8080\n");
// 继续执行接收连接等操作...
close(sockfd);
return 0;
}
bind 和 listen 的关系
bind:用来将一个地址(IP 地址和端口号)绑定到一个套接字上。这是服务器应用程序必须执行的第一步。listen:在bind完成后,调用listen将该套接字置于监听状态。这样,套接字开始接收来自客户端的连接请求。

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









