




Linux 网络子系统分析3(基于Linux6.6)---设备无关层分析
一、概述
本篇文章主要分析设备无关接口,通用设备抽象和Qos层
1. 设备无关接口(Device-Independent Interface)
设备无关接口是指网络子系统中,处理网络通信的代码与具体的硬件设备驱动解耦的部分。这种抽象接口使得不同类型的网络接口卡(NIC)可以通过相同的接口进行管理和配置,而不需要每个硬件设备都实现特定的协议栈逻辑。Linux 网络子系统通过 网络设备接口(Net Device Interface) 来提供这种设备无关的接口。
网络设备接口
在 Linux 中,所有网络设备(如网卡、虚拟网卡、桥接设备等)都遵循统一的接口规范,这些接口由 net_device 结构体表示。net_device 结构体包含了与硬件设备相关的各种信息和操作函数,如:
netdev_ops: 指向网络设备的操作函数指针结构,提供设备的初始化、启动、停止等方法。dev_addr: 设备的 MAC 地址。flags: 网络设备的标志位,表示设备的状态(如启用、禁用)。tx_queue_len: 传输队列长度。
这些接口允许网络协议栈层与底层硬件解耦,从而使得 Linux 能够灵活支持各种不同的硬件设备,如以太网卡、无线网卡、虚拟网络设备(如 VETH、TUN/TAP)等。
设备驱动与设备接口
设备驱动程序在操作系统内核中负责与硬件交互,通过设备接口与上层协议栈进行通信。例如,Ethernet 驱动程序(如 e1000 驱动)会实现 net_device 结构中的方法,如 ndo_open、ndo_stop、ndo_start_xmit 等,从而实现数据的接收、发送、设备控制等功能。
设备无关接口允许网络协议栈(如 IP 层、TCP 层等)与底层硬件设备的实现细节隔离,使得同一层的网络协议代码可以在不同的硬件上运行,而不需要修改上层协议。
2. 通用设备抽象(Generic Device Abstraction)
Linux 网络子系统中的通用设备抽象层是为了统一管理不同种类的网络设备,并简化网络设备驱动程序的实现。这个抽象层主要体现在以下几个方面:
net_device 结构
每个网络设备都对应一个 net_device 结构体,它为每个网络接口提供统一的操作接口。Linux 网络子系统通过 net_device 来实现对不同设备的统一访问。net_device 结构体不仅包含设备的基本信息(如 MAC 地址、设备名称、设备状态),还包含了与该设备相关的操作函数指针(如启动、停止、数据传输等)。
设备状态与事件
设备抽象层提供了对设备状态的统一管理,如设备的启用、禁用、挂起等状态操作。通过统一的设备接口,Linux 内核能够在不同硬件设备间切换,动态管理设备的生命周期。net_device 结构体中的状态标志(如 IFF_UP、IFF_RUNNING)和事件处理机制(如设备插拔事件)使得设备管理更加灵活。
网络设备队列与调度
网络设备抽象不仅管理网络设备的状态,还涉及到网络流量的调度和管理。Linux 使用队列(如发送队列和接收队列)来缓存网络数据包,这些队列通常由硬件和驱动程序共同管理。通过抽象层,Linux 可以灵活地配置这些队列的参数,如队列长度、优先级等。
3. QoS 层(Quality of Service)
QoS(服务质量)是指对网络通信的管理,通过对流量进行优先级划分、带宽控制、延迟控制等,来确保关键应用和服务能够获得优先处理。Linux 网络子系统提供了一个功能强大的 QoS 层,用于管理网络流量,并为不同的数据流提供不同的服务质量。
Traffic Control (tc) 工具
在 Linux 中,tc 命令(Traffic Control)是用来配置和管理网络流量控制的工具,它允许用户配置网络接口的 QoS 策略。通过 tc 命令,可以为网络接口设置带宽限制、优先级队列、流量整形等。
tc 是基于 队列调度器(qdisc) 和 类(class) 来实现流量控制的。常见的队列调度器有:
pfifo:先入先出(FIFO)队列调度器。htb(Hierarchical Token Bucket):分层令牌桶调度器,用于带宽分配和流量整形。cbq(Class-Based Queueing):基于类的队列调度,允许将流量按照不同的优先级进行分类。
tc 和 QoS 配置
在 Linux 中,QoS 配置是通过网络接口的调度器来实现的。tc 工具可以设置不同的队列调度器(qdisc),然后在每个调度器下定义类(class)和过滤器(filter)来控制流量。常见的 QoS 策略包括:
- 带宽限制:为不同的流量设置最大带宽,避免某些应用占用过多带宽。
- 流量整形(Shaping):控制流量的速率,平滑发送数据流,避免突发流量造成网络拥堵。
- 优先级排队:根据不同的流量类型设置优先级,例如,实时视频流量可以设置为高优先级,而文件下载流量设置为低优先级。
通过 tc 工具,用户可以将网络流量分配到不同的队列中,并根据实际需求调整带宽、延迟等参数。
Traffic Control 核心组件
Linux 网络协议栈中的 QoS 功能主要由以下几个核心组件实现:
- qdisc:队列调度器,用于管理数据包的排队与调度。
- class:每个队列调度器下的类,表示流量的不同类别。
- filter:过滤器,用于分类流量,将数据包分配到不同的类或队列中。
这些组件提供了灵活的 QoS 管理能力,可以根据网络流量的特征、应用的需求以及网络状况来调整流量的优先级、带宽等。
二、数据抽象和接口
2.1、net_device
设备无关层一个重要的数据抽象是net_device{},net_device是一个承上启下的结构,对上层,对应网络层特定的数据结构,对下,对应驱动程序的私有数据,而作为一个抽象数据结构,其提供的抽象接口有效的隔离了不同网络硬件的变化。net_device是一个庞大的数据结构,它的数据成员我挑选重要的按类说明:
设备的属性
include/linux/netdevice.h
struct net_device {
char name[IFNAMSIZ];
struct netdev_name_node *name_node;
struct dev_ifalias __rcu *ifalias;
/*
* I/O specific fields
* FIXME: Merge these and struct ifmap into one
*/
unsigned long mem_end;
unsigned long mem_start;
unsigned long base_addr;
/*
* Some hardware also needs these fields (state,dev_list,
* napi_list,unreg_list,close_list) but they are not
* part of the usual set specified in Space.c.
*/
unsigned long state;
struct list_head dev_list;
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
struct list_head ptype_all;
struct list_head ptype_specific;
struct {
struct list_head upper;
struct list_head lower;
} adj_list;
/* Read-mostly cache-line for fast-path access */
unsigned int flags;
unsigned long long priv_flags;
const struct net_device_ops *netdev_ops;
int ifindex;
unsigned short gflags;
unsigned short hard_header_len;
/* Note : dev->mtu is often read without holding a lock.
* Writers usually hold RTNL.
* It is recommended to use READ_ONCE() to annotate the reads,
* and to use WRITE_ONCE() to annotate the writes.
*/
unsigned int mtu;
unsigned short needed_headroom;
unsigned short needed_tailroom;
netdev_features_t features;
netdev_features_t hw_features;
netdev_features_t wanted_features;
netdev_features_t vlan_features;
netdev_features_t hw_enc_features;
netdev_features_t mpls_features;
netdev_features_t gso_partial_features;
unsigned int min_mtu;
unsigned int max_mtu;
unsigned short type;
unsigned char min_header_len;
unsigned char name_assign_type;
int group;
..
}
结构管理:
struct net_device {
struct hlist_node name_hlist;
struct list_head dev_list;
struct list_head napi_list;
struct list_head unreg_list;
struct list_head close_list;
struct list_head ptype_all;
struct list_head ptype_specific;
struct list_head napi_list
};
接口及其上下文
struct net_device {
const struct header_ops *header_ops;
const struct rtnl_link_ops *rtnl_link_ops;
const struct net_device_ops *netdev_ops;
const struct ethtool_ops *ethtool_ops;
struct in_device __rcu *ip_ptr;
rx_handler_func_t __rcu *rx_handler;
void __rcu *rx_handler_data;
}
2.2、API及说明
alloc_netdev_mqs
alloc_etherdev
alloc_etherdev_mq
free_netdev
net/core/dev.c
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name,
unsigned char name_assign_type,
void (*setup)(struct net_device *),
unsigned int txqs, unsigned int rxqs);
- net_device的分配
- 初始化:dev_addr_init/dev_mc_init/dev_uc_init/dev_net_set
- 发送队列和接收队列初始化
register_netdev
unregister_netdev
net/core/dev.c
int register_netdev(struct net_device *dev)
- 检测name合法性,分配ifindex
- dev_init_scheduler 初始化qdisc
- list_netdevice 将ifindex,name,dev加入hash表
- call_netdevice_notifiers(NETDEV_REGISTER, dev) /* Notify protocols, that a new device appeared. */
netif_carrier_on
netif_carrier_off
netif_carrier_ok
端口状态:
一般的,称端口状态是UP包括如下两个方面:
- 管理状态
- 链路状态
当执行ifconfig eth_X up,端口的管理状态up,此时dev->flags 需要置 IFF_UP位,链路状态一般由驱动程序和内核共同完成,链路状态一般由网卡芯片中的某个寄存器指定,驱动程序通过处理链路发生变化时产生中断,也可以通过timer,tasklet等机制去轮询端口的状态,之后通过以下接口通知内核端口的链路状态:
net/sched/sch_generic.c
/**
* netif_carrier_on - set carrier
* @dev: network device
*
* Device has detected acquisition of carrier.
*/
void netif_carrier_on(struct net_device *dev)
{
if (test_and_clear_bit(__LINK_STATE_NOCARRIER, &dev->state)) {
if (dev->reg_state == NETREG_UNINITIALIZED)
return;
atomic_inc(&dev->carrier_up_count);
linkwatch_fire_event(dev);
if (netif_running(dev))
__netdev_watchdog_up(dev);
}
}
EXPORT_SYMBOL(netif_carrier_on);
看linkwatch_fire_event,该函数将自身加入lweventlist的工作队列并调度,等待执行。
工作队列对应的执行函数是linkwatch_event,这个函数就是遍历linkwatch事件的列表lweventlist,通过linkwatch_do_dev处理取出的dev,在这个阶段,端口是link的,但需要检测管理状态是不是IFF_UP的,这样就分别对应两种操作:
- dev_activate
- dev_deactivate
dev_activate函数功能如下:
- 为tx队列分配qdisc,如果不需要队列:noqueue_qdisc_ops;只有一个队列:default_qdisc_ops;有多个队列:mq_qdisc_ops,并和发送队列绑定。
- 激活watchdog,dev_watchdog_up
IFF_UP这个状态是在__dev_open阶段设置的,同时也会dev_activate激活设备,__dev_open和netif_carrier_on区别是同步和异步的区别:netif_carrier_on通过工作队列调度异步的执行分配qdisc和激活设备(若此时IFF_UP),__dev_open则是同步的执行设置IFF_UP和激活设备
2.3、总结
1.设备状态变迁
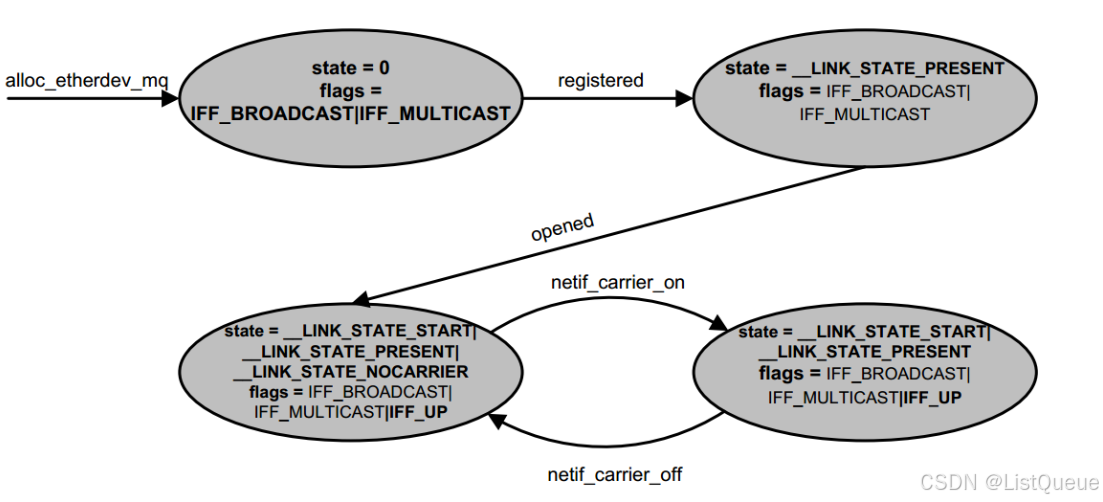 可以看出open将设备状态置为__LINK_STATE_START,flags标记为IFF_UP
可以看出open将设备状态置为__LINK_STATE_START,flags标记为IFF_UP
而linkwatch的设备状态是__LINK_STATE_NOCARRIER
而设备状态__LINK_STATE_PRESENT是设备注册的时候产生的
2.发送和接收队列的建立
1. 分配net_device结构体时,根据队列数目分配对应的rx/tx队列对应的结构,参考下图
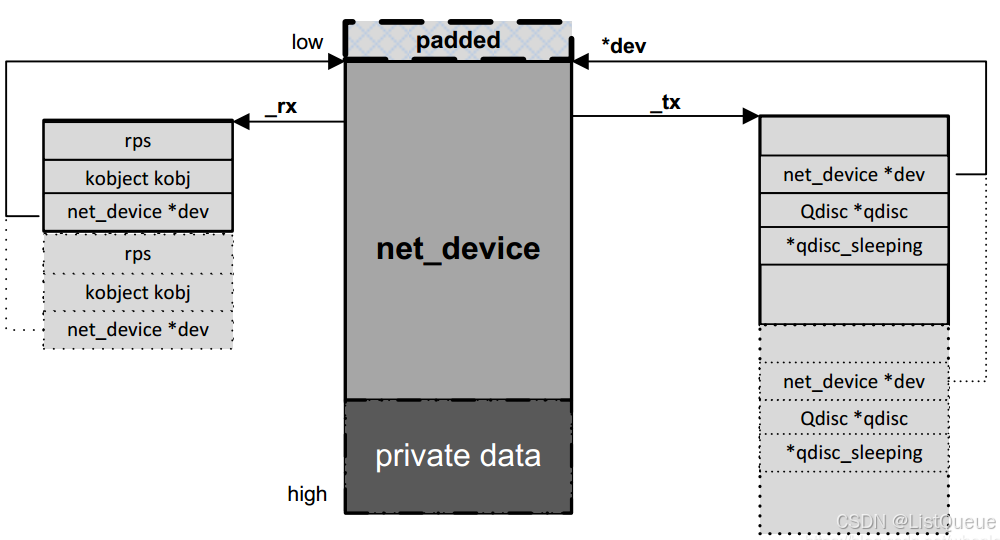
2. 注册net_device结构时,利用dev_init_scheduler函数,为发送队列指定默认的qdisc:noop_qdisc
3. 在open操作或linkwatch event(IFF_UP)时,激活设备(dev_activate),按照发送队列不同情况分配具体qdisc
3.通知链
- register call_netdevice_notifiers(NETDEV_POST_INIT, dev)
- register call_netdevice_notifiers(NETDEV_REGISTER, dev),此时网络层创建ip_ptr(in_device)
- __dev_open call_netdevice_notifiers(NETDEV_PRE_UP, dev)
- dev_open call_netdevice_notifiers(NETDEV_UP, dev);
三、从qdisc到设备发送
qdisc实际上实现了网络层到硬件设备的缓冲和控制机制,网络层调用的接口dev_queue_xmit开始
函数流程如下:
1. 通过 netdev_pick_tx选择发送队列。
2. 处理。
spin_lock(root_lock);
if (unlikely(test_bit(__QDISC_STATE_DEACTIVATED, &q->state))) {
__qdisc_drop(skb, &to_free);
rc = NET_XMIT_DROP;
} else if ((q->flags & TCQ_F_CAN_BYPASS) && !qdisc_qlen(q) &&
qdisc_run_begin(q)) {
} else {
rc = q->enqueue(skb, q, &to_free) & NET_XMIT_MASK;
if (qdisc_run_begin(q)) {
if (unlikely(contended)) {
spin_unlock(&q->busylock);
contended = false;
}
__qdisc_run(q);
qdisc_run_end(q);
}
}
spin_unlock(root_lock);
分析上述情况:
- 如果qdisc状态是__QDISC_STATE_DEACTIVATED,丢包即可
- 如果qdisc 队列长度是0,且qdisc flag 是TCQ_F_CAN_BYPASS,因为没有队列,可以选择直接发送处理
- 最后一种是有队列存在的情况
对于有队列存在的情况,我们看到一开始就持有了qidsc 的lock,然后执行入队操作,接下来有三个操作:
qdisc_run_begin
__qdisc_run
qdisc_run_end
include/net/sch_generic.h
/* For !TCQ_F_NOLOCK qdisc, qdisc_run_begin/end() must be invoked with
* the qdisc root lock acquired.
*/
static inline bool qdisc_run_begin(struct Qdisc *qdisc)
{
if (qdisc->flags & TCQ_F_NOLOCK) {
if (spin_trylock(&qdisc->seqlock))
return true;
/* No need to insist if the MISSED flag was already set.
* Note that test_and_set_bit() also gives us memory ordering
* guarantees wrt potential earlier enqueue() and below
* spin_trylock(), both of which are necessary to prevent races
*/
if (test_and_set_bit(__QDISC_STATE_MISSED, &qdisc->state))
return false;
/* Try to take the lock again to make sure that we will either
* grab it or the CPU that still has it will see MISSED set
* when testing it in qdisc_run_end()
*/
return spin_trylock(&qdisc->seqlock);
}
return !__test_and_set_bit(__QDISC_STATE2_RUNNING, &qdisc->state2);
}
static inline void qdisc_run_end(struct Qdisc *qdisc)
{
if (qdisc->flags & TCQ_F_NOLOCK) {
spin_unlock(&qdisc->seqlock);
/* spin_unlock() only has store-release semantic. The unlock
* and test_bit() ordering is a store-load ordering, so a full
* memory barrier is needed here.
*/
smp_mb();
if (unlikely(test_bit(__QDISC_STATE_MISSED,
&qdisc->state)))
__netif_schedule(qdisc);
} else {
__clear_bit(__QDISC_STATE2_RUNNING, &qdisc->state2);
}
}
可以看到qdisc_run_begin/qdisc_run_end就是对seqlock的一个封装,是一个不带锁的write_seqlock和write_sequnlock,由于两个的操作都是对seqcount++,所以这中间如果被打断,那么seqcount一定是奇数,在两个操作中间的操作称为run
/* For !TCQ_F_NOLOCK qdisc: callers must either call this within a qdisc
* root_lock section, or provide their own memory barriers -- ordering
* against qdisc_run_begin/end() atomic bit operations.
*/
static inline bool qdisc_is_running(struct Qdisc *qdisc)
{
if (qdisc->flags & TCQ_F_NOLOCK)
return spin_is_locked(&qdisc->seqlock);
return test_bit(__QDISC_STATE2_RUNNING, &qdisc->state2);
}
接下来分析__qdisc_run
include/net/sch_generic.h
void __qdisc_run(struct Qdisc *q)
{
int quota = READ_ONCE(dev_tx_weight);
int packets;
while (qdisc_restart(q, &packets)) {
quota -= packets;
if (quota <= 0) {
if (q->flags & TCQ_F_NOLOCK)
set_bit(__QDISC_STATE_MISSED, &q->state);
else
__netif_schedule(q);
break;
}
}
}
函数的逻辑很简单,每次处理一定数量的包,如果到达处理上限或者需要进程调度就将报文推迟到发包软中断处理
net/sched/sch_generic.c
static void __netif_reschedule(struct Qdisc *q)
{
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = this_cpu_ptr(&softnet_data);
q->next_sched = NULL;
*sd->output_queue_tailp = q;
sd->output_queue_tailp = &q->next_sched;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}
void __netif_schedule(struct Qdisc *q)
{
if (!test_and_set_bit(__QDISC_STATE_SCHED, &q->state))
__netif_reschedule(q);
}
EXPORT_SYMBOL(__netif_schedule);
这里把软中断的发包流程也展开:
在net_dev_init
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
if (sd->output_queue) {
struct Qdisc *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
sd->output_queue_tailp = &sd->output_queue;
local_irq_enable();
while (head) {
struct Qdisc *q = head;
spinlock_t *root_lock = NULL;
head = head->next_sched;
qdisc_run(q);
if (root_lock)
spin_unlock(root_lock);
}
}
在软中断中调用qdisc_run继续
static inline void qdisc_run(struct Qdisc *q)
{
if (qdisc_run_begin(q)) {
__qdisc_run(q);
qdisc_run_end(q);
}
}
其中qdisc_restart如下:
static inline bool qdisc_restart(struct Qdisc *q, int *packets)
{
spinlock_t *root_lock = NULL;
struct netdev_queue *txq;
struct net_device *dev;
struct sk_buff *skb;
bool validate;
/* Dequeue packet */
skb = dequeue_skb(q, &validate, packets);
if (unlikely(!skb))
return false;
if (!(q->flags & TCQ_F_NOLOCK))
root_lock = qdisc_lock(q);
dev = qdisc_dev(q);
txq = skb_get_tx_queue(dev, skb);
return sch_direct_xmit(skb, q, dev, txq, root_lock, validate);
}
只捡重要的贴了
/*
* Transmit possibly several skbs, and handle the return status as
* required. Owning qdisc running bit guarantees that only one CPU
* can execute this function.
*
* Returns to the caller:
* false - hardware queue frozen backoff
* true - feel free to send more pkts
*/
bool sch_direct_xmit(struct sk_buff *skb, struct Qdisc *q,
struct net_device *dev, struct netdev_queue *txq,
spinlock_t *root_lock, bool validate)
{
int ret = NETDEV_TX_BUSY;
bool again = false;
/* And release qdisc */
if (root_lock)
spin_unlock(root_lock);
/* Note that we validate skb (GSO, checksum, ...) outside of locks */
if (validate)
skb = validate_xmit_skb_list(skb, dev, &again);
#ifdef CONFIG_XFRM_OFFLOAD
if (unlikely(again)) {
if (root_lock)
spin_lock(root_lock);
dev_requeue_skb(skb, q);
return false;
}
#endif
if (likely(skb)) {
HARD_TX_LOCK(dev, txq, smp_processor_id());
if (!netif_xmit_frozen_or_stopped(txq))
skb = dev_hard_start_xmit(skb, dev, txq, &ret);
else
qdisc_maybe_clear_missed(q, txq);
HARD_TX_UNLOCK(dev, txq);
} else {
if (root_lock)
spin_lock(root_lock);
return true;
}
if (root_lock)
spin_lock(root_lock);
if (!dev_xmit_complete(ret)) {
/* Driver returned NETDEV_TX_BUSY - requeue skb */
if (unlikely(ret != NETDEV_TX_BUSY))
net_warn_ratelimited("BUG %s code %d qlen %d\n",
dev->name, ret, q->q.qlen);
dev_requeue_skb(skb, q);
return false;
}
return true;
}
这里先unlock qdisc的lock,这样在处理的同时可以通过dev_queue_xmit继续执行enqueue操作,在这种情况下进来的发送
contended = qdisc_is_running(q);
if (unlikely(contended))
spin_lock(&q->busylock);
注意虽然解锁了,但是seqcount目前仍是奇数,所以qdisc_is_running是真,此时在enqueue之后进行qdisc_run_begin检测到running后就直接返回了,不继续进行出队发包处理,事实上进行了串行化的操作。
而在dev_hard_start_xmit之后,就调用到驱动的发包接口了。
四、报文的接收流程
一般的hardirq中完成报文的copy(当然性能高的基本都是轮询的了,数据面转发也没有什么hardirq和softirq什么事)。
4.1、NAPI
napi是在中断中触发软中断,由在softirq上下文对收包进行轮询
1. 初始化时利用netif_napi_add,添加自己的napi poll处理,其实就是通过一个napi_struct结构将poll和一些信息管理起来。
2. nic的中断处理流程调用napi_schedule_irqoff(注意这时候nic的hardirq是关闭的),将napi 的poll_list加入到soft_data的poll上,并触发一个软中断。
3. 直接看下softirq的处理过程:
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
软中断中调用从soft_net的poll list取出napi,通过napi_poll调用1中add的驱动实现的poll函数
4.驱动实现的poll函数执行硬件相关的收报函数,收报的数量控制在budget个,调用上层的结构是netif_receive_skb
5. 收包完成后调用napi_complete_done,将设备从poll list移除,打开nic中断
4.2、netif_rx
netif_rx也使用的napi机制,称为backlog,根据上节的的说明步骤来分析:
1. 在net_dev_init中,注册backlog napi,它的poll函数称为、
2. 在netif_rx中,主要调用netif_rx的一个重要操作就是enqueue_to_backlog,将skb入sd->input_pkt_queue队列,触发一个软中断
*
* enqueue_to_backlog is called to queue an skb to a per CPU backlog
* queue (may be a remote CPU queue).
*/
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
enum skb_drop_reason reason;
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
reason = SKB_DROP_REASON_NOT_SPECIFIED;
sd = &per_cpu(softnet_data, cpu);
rps_lock_irqsave(sd, &flags);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= READ_ONCE(netdev_max_backlog) && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock_irq_restore(sd, &flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state))
napi_schedule_rps(sd);
goto enqueue;
}
reason = SKB_DROP_REASON_CPU_BACKLOG;
drop:
sd->dropped++;
rps_unlock_irq_restore(sd, &flags);
dev_core_stats_rx_dropped_inc(skb->dev);
kfree_skb_reason(skb, reason);
return NET_RX_DROP;
}
3. 在软中断流程中调用poll函数,对backlog napi来说就是著名的process_backlog
4. 没有什么特别的就是出队加上netif_receive_skb
4.3、报文接收流程图
+------------------------+
| 1. 数据链路层接收报文 |
+------------------------+
|
v
+------------------------+
| 2. 网络设备驱动程序 | <- 网络设备驱动接收硬件中断,执行接收操作
+------------------------+
|
v
+------------------------+
| 3. 数据包入队(软中断) |
| (进入软中断队列) |
+------------------------+
|
v
+------------------------+
| 4. 上层协议栈处理(NAPI)|
| (Poll模式从队列中获取) |
+------------------------+
|
v
+------------------------+
| 5. 校验和检验 |
| (如IP校验和、UDP/TCP) |
+------------------------+
|
v
+------------------------+
| 6. 网络层(IP)处理 |
| (如路由、目标检查) |
+------------------------+
|
v
+------------------------+
| 7. 传输层处理(如TCP) |
| (如分段重组、序列号等)|
+------------------------+
|
v
+------------------------+
| 8. 上层协议处理 |
| (如上层应用协议处理) |
+------------------------+
|
v
+------------------------+
| 9. 应用程序接收数据 |
| (如socket接收数据) |
+------------------------+
详细描述:
-
数据链路层接收报文
网络接口卡(NIC)接收到物理层的报文。此时,数据包已经从物理媒介(如以太网、Wi-Fi)通过数据链路层传送到操作系统的网络子系统。 -
网络设备驱动程序
接收到的数据包会被传递给相应的设备驱动程序。设备驱动程序处理硬件中断,读取网络接口卡中的数据缓冲区,并将数据传递给内核中的网络协议栈。 -
数据包入队(软中断)
数据包通过网络接口驱动程序入队,并通过软中断机制传递到内核的网络栈。这个过程使用 NAPI(New API) 模式来避免高频中断,提升性能。数据包会被排入软中断队列,等待被内核处理。 -
NAPI Poll模式处理
在 NAPI(New API) 中,内核通过定期轮询软中断队列,从队列中获取数据包并进行处理。这避免了因过多的中断而导致的性能瓶颈,提升了数据包接收的效率。 -
校验和检验
数据包到达内核后,首先会进行校验和验证。如果数据包有错误(例如 IP 或传输层协议的校验和不正确),会被丢弃。如果校验和有效,数据包会继续向上传递。 -
网络层(IP)处理
IP 层会对数据包进行进一步处理,包括检查数据包的目标地址、路由选择等。此时,内核会决定该数据包是否需要继续传递到本机,或将数据包转发到其他主机。 -
传输层处理(如TCP)
如果是传输层协议(如 TCP、UDP),内核会对数据进行进一步的处理。对于 TCP,内核会处理分段重组、序列号、ACK确认等操作。如果是 UDP,则会进行端口匹配,找到对应的应用层。 -
上层协议处理
在传输层完成处理后,数据包会被传递到上层协议(如 HTTP、FTP 等)。如果是通过套接字(socket)接口接收到数据,内核会将数据传递给用户空间的应用程序。 -
应用程序接收数据
应用程序通过系统调用(如recv()或read())从套接字中读取数据。此时,网络层和传输层已经处理完成,数据已经准备好供应用层使用。

















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









