




Linux 网络子系统分析2(基于Linux6.6)---协议栈分层框架
一、综述
1. Linux 网络协议栈的分层模型
Linux 网络协议栈的分层大致可以分为以下几个层次:
- 应用层(Application Layer)
- 传输层(Transport Layer)
- 网络层(Network Layer)
- 数据链路层(Data Link Layer)
- 物理层(Physical Layer)
每一层都有其特定的职责,并与上下层之间通过接口进行交互。
图示框架:
+-------------------+ <- 应用层
| Application | <- TCP, UDP, DNS, HTTP, etc.
+-------------------+
|
+-------------------+ <- 传输层
| Transport Layer | <- TCP, UDP, SCTP, etc.
+-------------------+
|
+-------------------+ <- 网络层
| Network Layer | <- IP, ICMP, ARP, etc.
+-------------------+
|
+-------------------+ <- 数据链路层
| Data Link Layer | <- Ethernet, Wi-Fi, PPP, etc.
+-------------------+
|
+-------------------+ <- 物理层
| Physical Layer | <- Network Interface (Ethernet, Wi-Fi, etc.)
+-------------------+
2. 每一层的详细功能与职责
应用层(Application Layer)
应用层是协议栈的最上层,负责与用户应用程序进行交互。它为用户提供服务,例如文件传输、远程登录、网页浏览等。Linux 中的一些常见的应用层协议包括:
- HTTP/HTTPS(超文本传输协议)
- FTP(文件传输协议)
- SMTP(简单邮件传输协议)
- DNS(域名系统)
这些协议通过 套接字接口(Socket API) 与下层的传输层协议进行通信。应用层数据通过套接字的读写操作与下层进行交互。
传输层(Transport Layer)
传输层的主要任务是为应用层提供端到端的通信服务,负责数据的可靠传输、流量控制和错误检测等。常见的传输层协议包括:
- TCP(Transmission Control Protocol):提供可靠的、面向连接的通信,确保数据按顺序到达且没有丢失。
- UDP(User Datagram Protocol):提供无连接的、不可靠的通信,适用于实时数据传输或广播。
- SCTP(Stream Control Transmission Protocol):一种较新的协议,结合了 TCP 的可靠性和 UDP 的高效性。
在 Linux 中,传输层通过 sock 结构体与应用层进行交互,并将数据交给下层的网络层处理。
网络层(Network Layer)
网络层的主要任务是负责数据包的路由选择与转发,确保数据能够从源节点传输到目的节点。最常见的网络层协议是:
- IP(Internet Protocol):定义了数据包的寻址和路由规则,包括 IPv4 和 IPv6。
- ICMP(Internet Control Message Protocol):用于网络控制和错误报告,最著名的例子是
ping命令。 - ARP(Address Resolution Protocol):用于将 IP 地址映射到 MAC 地址。
在 Linux 中,网络层使用 sk_buff(socket buffer)数据结构来管理传输的网络数据包。
数据链路层(Data Link Layer)
数据链路层负责在物理媒介上封装和传输数据帧。它处理数据的封装、物理寻址和错误检测等。常见的数据链路层协议包括:
- 以太网(Ethernet):用于局域网中,通过 MAC 地址进行通信。
- Wi-Fi:无线局域网协议。
- PPP(Point-to-Point Protocol):常用于串行连接和虚拟专用网络(VPN)。
Linux 网络协议栈中的数据链路层协议通常是由 网络驱动程序 提供支持的,数据帧的处理通过 net_device 结构体进行。
物理层(Physical Layer)
物理层负责实际的数据传输,包括电气信号的传递和物理介质的管理。它处理与硬件相关的任务,如电缆、光纤、无线信号等。物理层的实现与硬件直接相关,Linux 提供了与硬件交互的接口,通过 网卡驱动程序 来完成物理层的工作。
3. 数据流动过程(从上到下)
以下是一个典型的数据流动过程,从应用层到物理层的传输:
- 应用层:用户应用程序(如浏览器)通过套接字接口发送数据。数据被传递给传输层(TCP 或 UDP)。
- 传输层:传输层(例如 TCP)将应用层数据进行分段,封装成传输层数据包,并通过端口号进行标识,传递给网络层。
- 网络层:网络层(例如 IP)添加源和目标 IP 地址,并决定如何路由数据包。数据包被传递到数据链路层。
- 数据链路层:数据链路层将网络层数据包封装成数据帧,添加源和目标 MAC 地址,然后将数据帧传递给物理层。
- 物理层:物理层通过网卡驱动程序将数据转换为电信号,并通过物理媒介传输到目标设备。
4. 从下到上的接收过程
接收过程与发送过程相反,数据从物理层传入,逐层往上传递:
- 物理层:物理层接收到电信号并将其转换成数据帧,传递到数据链路层。
- 数据链路层:数据链路层从数据帧中提取出网络层数据包,传递给网络层。
- 网络层:网络层根据目标 IP 地址判断数据包是否应交给本地应用,传递给传输层。
- 传输层:传输层根据端口号将数据交给目标应用程序,完成数据传递。
- 应用层:应用层通过套接字接口接收数据,供用户程序使用。
5. Linux 网络协议栈的实现与模块化
Linux 网络协议栈的实现是高度模块化的,协议栈的每一层都是由不同的内核模块来实现。例如:
ip_tables:用于实现网络层的防火墙功能。netfilter:用于包过滤、网络地址转换(NAT)等。tcp:提供 TCP 协议的实现。ethernet:处理以太网数据帧的封装与解封装。
模块化的设计使得 Linux 网络协议栈非常灵活,可以很容易地为特定需求或硬件平台添加新的协议或特性。
二、INET的初始化
2.1、INET接口注册
net/ipv4/af_inet.c
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
raw_hashinfo_init(&raw_v4_hashinfo);
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
rc = proto_register(&raw_prot, 1);
if (rc)
goto out_unregister_udp_proto;
rc = proto_register(&ping_prot, 1);
if (rc)
goto out_unregister_raw_proto;
/*
* Tell SOCKET that we are alive...
*/
(void)sock_register(&inet_family_ops);
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/*
* Set the ARP module up
*/
arp_init();
/*
* Set the IP module up
*/
ip_init();
/* Initialise per-cpu ipv4 mibs */
if (init_ipv4_mibs())
panic("%s: Cannot init ipv4 mibs\n", __func__);
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */
udp_init();
/* Add UDP-Lite (RFC 3828) */
udplite4_register();
raw_init();
ping_init();
/*
* Set the ICMP layer up
*/
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/*
* Initialise the multicast router
*/
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);
#endif
if (init_inet_pernet_ops())
pr_crit("%s: Cannot init ipv4 inet pernet ops\n", __func__);
ipv4_proc_init();
ipfrag_init();
dev_add_pack(&ip_packet_type);
ip_tunnel_core_init();
rc = 0;
out:
return rc;
out_unregister_raw_proto:
proto_unregister(&raw_prot);
out_unregister_udp_proto:
proto_unregister(&udp_prot);
out_unregister_tcp_proto:
proto_unregister(&tcp_prot);
goto out;
}
fs_initcall(inet_init);
可以看到在发送层面调用了proto_register/inet_register_protosw,这里具体看一下inet_protosw{}的结构:
include/net/protocol.h
/* This is used to register socket interfaces for IP protocols. */
struct inet_protosw {
struct list_head list;
/* These two fields form the lookup key. */
unsigned short type; /* This is the 2nd argument to socket(2). */
unsigned short protocol; /* This is the L4 protocol number. */
struct proto *prot;
const struct proto_ops *ops;
unsigned char flags; /* See INET_PROTOSW_* below. */
};
可以看到type<->protocol<->proto_ops{}<->proto{}的对应关系由这个所谓“协议切换表”统一了起来:
net/ipv4/af_inet.c
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
接收层面,inet_add_protocol/dev_add_pack。基本上一个收发的分层框架接口就建立起来了。
2.2、抽象实体的建立
各层的接口注册完毕后,接下来看一看接口是如何与抽象结构绑定的,这个过程是进行socket系统调用产生的,socket系统调用的作用应该在socket layer分配一个抽象socket结构,为网络协议层分配一个sock结构,并将抽象层的接口与抽象的实体进行绑定。
一个典型的socket API原型:
int socket(int domain, int type, int protocol);
为了保证分析的完整性,还是将inet socket相关参数做一下简单说明,对于address family是INET的socket来说(man 7 ip),报文都是基于IP,所以有TCP, UDP, RAW三种:
tcp_socket = socket(AF_INET, SOCK_STREAM, 0);
udp_socket = socket(AF_INET, SOCK_DGRAM, 0);
raw_socket = socket(AF_INET, SOCK_RAW, protocol);
对于TCP(SOCK_STREAM)来说,第三个参数只能是0或者IPPROTO_TCP,对于UDP(SOCK_DGRAM)来说,第三个参数只能是0或者IPPROTO_UDP,对于inet raw报文来说,有以下特点:
- 其构造的报文不包括二层头,这点与AF_PACKET区别。
- 如果不指定IP_HDRINCL(socket),由内核构造ipv4头。
- 如果协议指定IPPROTO_RAW,默认使能IP_HDRINCL,但是这样的参数在收放向上无法用来接收所有的IP报文
对应系统调用:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
接下来分析socket系统调用执行流程
[net/socket.c]
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
sock = sock_alloc();
sock->type = type;
rcu_read_lock();
pf = rcu_dereference(net_families[family]);
rcu_read_unlock();
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
}
代码只摘录了部分,只说明重要的部分,我们来看socket具体流程
socket系统调用首先会分配一个socket结构体:
[include/linux/net.h]
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq __rcu *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
我们知道不同的family address对应的sock结构是不同的,因为sock是代表具体协议层的,这里利用接口pf->create(inet_create)对具体协议(inet)进行创建。
[inet/ipv4/af_inet.c]
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
sock->state = SS_UNCONNECTED;
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
rcu_read_unlock();
WARN_ON(!answer_prot->slab);
err = -ENOBUFS;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
err = 0;
if (INET_PROTOSW_REUSE & answer_flags)
sk->sk_reuse = SK_CAN_REUSE;
inet = inet_sk(sk);
inet->is_icsk = (INET_PROTOSW_ICSK & answer_flags) != 0;
inet->nodefrag = 0;
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
}
先看对socket绑定接口的操作:根据type<->proto_ops<->proto关系,找到协议切换的结构,此时socket可以与proto_ops进行绑定,随后sk_alloc分配sock,过程中将sock与proto绑定
到此为止,前篇建立的结构就完全建立了,这里为了方便,再贴一次:
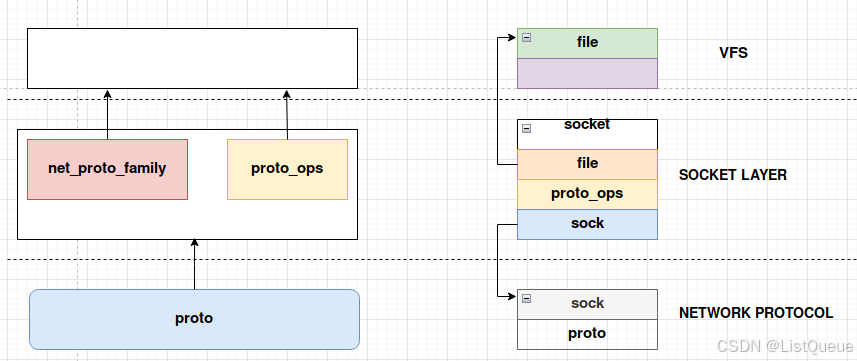
2.3、代码细节分析
sk_alloc完成sock{}分配和初始化,sock{}是网络层的表示,但由于协议多样,linux将sock{}抽象成一个基类,具体的协议要通过对sock{}的继承得到,对具体的协议(如inet,继承的结构是inet_sock{})是这样操作的,在协议注册指定继承者inet_sock{}的大小,这样在调用sk_alloc分配sock时实际上分配的大小是针对inet_sock{}的,这样在使用时可以像下面这样:
inet = inet_sk(sk);
sock这个结构本身还是比较复杂的,我们来看一些关键的部分,既然它是网络协议层的表示,那么基本的sip,dip,sport,dport是少不了的,这些位于sock{}的sock_common{}中:
struct sock_common __sk_common;
#define sk_num __sk_common.skc_num
#define sk_dport __sk_common.skc_dport
#define sk_addrpair __sk_common.skc_addrpair
#define sk_daddr __sk_common.skc_daddr
#define sk_rcv_saddr __sk_common.skc_rcv_saddr
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state
#define sk_reuse __sk_common.skc_reuse
#define sk_reuseport __sk_common.skc_reuseport
#define sk_prot __sk_common.skc_prot
inet
struct inet_sock {
struct sock sk;
#define inet_daddr sk.__sk_common.skc_daddr
#define inet_rcv_saddr sk.__sk_common.skc_rcv_saddr
#define inet_dport sk.__sk_common.skc_dport //dport
#define inet_num sk.__sk_common.skc_num //sport,主机序
__be32 inet_saddr;
这里再给出实际应用的几个例子,看看再socket建立的时候是怎么匹配的:
- ping socket(AF_INET, SOCK_RAW, IPPROTO_ICMP)
- TCP socket(AF_INET, SOCK_STREAM, IPPROTO_IP);
- UDP/ifconfig socket(AF_NET, SOCK_DGRAM, IPPROTO_IP );
net/ipv4/af_inet.c
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
if (protocol < 0 || protocol >= IPPROTO_MAX)
return -EINVAL;
sock->state = SS_UNCONNECTED;
/* Look for the requested type/protocol pair. */
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) { //如果指定TCP指定IPPROTO_TCP,UDP指定IPPROTO_UDP,对应的tcp/udp在这匹配,是全匹配,所以叫non-wild
if (protocol != IPPROTO_IP) //不能使用SOCK_RAW,IPPROTO_IP的组合
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) { //如果TCP,UDP protocol字段指定0,IPPROTO_IP,在这匹配,通过下一句将protocol改成实际的协议的值
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol) //原始套接字基本上都到这,如果原始套接字指定了IPPROTO_ICMP,走non-wild
break;
}
err = -EPROTONOSUPPORT;
}
...
}
RAW在socket中的特殊处理
net/ipv4/af_inet.c
if (SOCK_RAW == sock->type) { //如果是raw,主机序源端口为协议号
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol) //上面说过了IPPROTO_RAW默认指定IP_HDRINCL,表示app自行添加IP头
inet->hdrincl = 1;
}
if (inet->inet_num) {
inet->inet_sport = htons(inet->inet_num); //原始套接字在socket阶段就要指定端口,然后通过hash保存sk
/* Add to protocol hash chains. */
err = sk->sk_prot->hash(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
}
三、其他协议
- PF_UNIX
- PF_NETLINK
- PF_PACKET
3.1、PF_PACKET
net/packet/af_packet.c
static int __init packet_init(void)
{
int rc;
rc = register_pernet_subsys(&packet_net_ops);
if (rc)
goto out;
rc = register_netdevice_notifier(&packet_netdev_notifier);
if (rc)
goto out_pernet;
rc = proto_register(&packet_proto, 0);
if (rc)
goto out_notifier;
rc = sock_register(&packet_family_ops);
if (rc)
goto out_proto;
return 0;
out_proto:
proto_unregister(&packet_proto);
out_notifier:
unregister_netdevice_notifier(&packet_netdev_notifier);
out_pernet:
unregister_pernet_subsys(&packet_net_ops);
out:
return rc;
}
packet_create->packet_sock{}
po = pkt_sk(sk);
3.2、PF_NETLINK
net/netlink/af_netlink.c
static int __init netlink_proto_init(void)
{
int i;
int err = proto_register(&netlink_proto, 0);
if (err != 0)
goto out;
#if defined(CONFIG_BPF_SYSCALL) && defined(CONFIG_PROC_FS)
err = bpf_iter_register();
if (err)
goto out;
#endif
BUILD_BUG_ON(sizeof(struct netlink_skb_parms) > sizeof_field(struct sk_buff, cb));
nl_table = kcalloc(MAX_LINKS, sizeof(*nl_table), GFP_KERNEL);
if (!nl_table)
goto panic;
for (i = 0; i < MAX_LINKS; i++) {
if (rhashtable_init(&nl_table[i].hash,
&netlink_rhashtable_params) < 0) {
while (--i > 0)
rhashtable_destroy(&nl_table[i].hash);
kfree(nl_table);
goto panic;
}
}
netlink_add_usersock_entry();
sock_register(&netlink_family_ops);
register_pernet_subsys(&netlink_net_ops);
register_pernet_subsys(&netlink_tap_net_ops);
/* The netlink device handler may be needed early. */
rtnetlink_init();
out:
return err;
panic:
panic("netlink_init: Cannot allocate nl_table\n");
}
core_initcall(netlink_proto_init);
netlink_create->netlink_sock{}
nlk = nlk_sk(sock->sk);
3.3、PF_UNIX
net/unix/af_unix.c
static int __init af_unix_init(void)
{
int i, rc = -1;
BUILD_BUG_ON(sizeof(struct unix_skb_parms) > sizeof_field(struct sk_buff, cb));
for (i = 0; i < UNIX_HASH_SIZE / 2; i++) {
spin_lock_init(&bsd_socket_locks[i]);
INIT_HLIST_HEAD(&bsd_socket_buckets[i]);
}
rc = proto_register(&unix_dgram_proto, 1);
if (rc != 0) {
pr_crit("%s: Cannot create unix_sock SLAB cache!\n", __func__);
goto out;
}
rc = proto_register(&unix_stream_proto, 1);
if (rc != 0) {
pr_crit("%s: Cannot create unix_sock SLAB cache!\n", __func__);
proto_unregister(&unix_dgram_proto);
goto out;
}
sock_register(&unix_family_ops);
register_pernet_subsys(&unix_net_ops);
unix_bpf_build_proto();
#if IS_BUILTIN(CONFIG_UNIX) && defined(CONFIG_BPF_SYSCALL) && defined(CONFIG_PROC_FS)
bpf_iter_register();
#endif
out:
return rc;
}
unix_create->unix_sock{}
u = unix_sk(sk);

















 6493
6493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









