




Linux中断子系统11(基于Linux6.6)---中断之workqueue2
一、前情回顾
一种新的机制出现的原因往往是为了解决实际的问题,虽然linux kernel中已经提供了workqueue的机制,那么为何还要引入CMWQ(Concurrency Managed Workqueue)呢?
CMWQ(Concurrency Managed Workqueue) 是一种用于 Linux 内核中的工作队列机制,旨在优化并发工作负载的处理。它是对传统工作队列(Workqueue)的一种扩展,加入了更灵活的并发管理策略,以提高多核处理器上的任务执行效率和系统资源的利用率。
CMWQ 的基本概念
CMWQ 是 Concurrency Managed Workqueue 的缩写,字面意思是“并发管理工作队列”。它的核心目的是在多核系统中,动态地管理工作队列中的并发执行任务,能够根据系统的负载、任务类型和资源情况调整并发工作线程的数量。与传统的工作队列相比,CMWQ 提供了更高的灵活性和性能优化,尤其是在高并发和多核处理环境下。
CMWQ 与传统工作队列的对比
| 特性 | 传统工作队列(Workqueue) | CMWQ(Concurrency Managed Workqueue) |
|---|---|---|
| 并发度 | 固定的工作线程数量 | 动态管理并发度,根据负载调整工作线程数 |
| 灵活性 | 不支持动态调整并发度 | 支持动态调整,并根据系统负载和资源使用情况进行优化 |
| 系统适应性 | 无法根据负载变化自动调整并发度 | 根据系统负载、任务队列情况和优先级进行自适应调整 |
| 性能优化 | 固定线程数可能导致资源浪费或性能瓶颈 | 动态调整线程数,提高系统负载的处理效率,避免过度分配资源 |
CMWQ 的优势
- 提高并发处理效率:通过动态管理并发度,CMWQ 能够充分利用多核处理器的资源,减少线程切换开销,提高工作负载的处理速度。
- 节省资源:在负载较低时,CMWQ 会自动减少工作线程的数量,避免浪费系统资源。
- 优化系统响应性:CMWQ 能够根据负载的变化动态调整工作线程数,从而更好地应对负载波动,提高系统的响应速度和稳定性。
- 减少资源争用:在高并发场景下,CMWQ 可以有效避免资源争用,减少性能瓶颈。
二、为何需要CMWQ?
引入 CMWQ(Concurrency Managed Workqueue) 的原因主要是为了优化和更灵活地管理工作队列中的并发执行。CMWQ 机制(即并发管理工作队列)是 Linux 内核中一种新的工作队列类型,它是在传统工作队列(workqueue)的基础上引入的一种高级机制,旨在改进工作队列的调度和并发执行效率,尤其在多核系统上,提高性能并避免资源争用。
为什么要引入 CMWQ?
-
优化并发执行:
- 在传统的工作队列中,工作项通常会在固定数量的工作线程中排队执行,而这些线程可能会受到数量和负载的限制,导致工作队列处理效率不高。
- CMWQ 引入了动态管理并发数的概念,可以根据系统的负载动态调整并发工作线程的数量,从而更好地利用多核处理器的资源。
-
避免死锁和资源争用:
- 在传统的工作队列中,如果工作项之间存在资源竞争(例如,多个工作项同时访问共享资源),可能会导致死锁或者低效的执行。
- CMWQ 通过更精细的并发控制和队列管理,能够在一定程度上减少这种风险,避免低效的线程调度。
-
增强系统的响应性:
- CMWQ 可以根据当前系统负载来调节工作线程的数量,这使得系统能够在高负载下依然保持较好的响应性,并且能够在轻负载时减少资源的浪费。
-
自适应的工作队列管理:
- CMWQ 机制通过引入更多的自适应性(例如,可以根据队列的繁忙程度动态调整并发线程的数量),使得工作队列能根据负载情况灵活调整,提高了整个系统的运行效率。
传统工作队列 vs CMWQ
传统工作队列(Workqueue)
- 工作队列中的工作项是由固定数量的工作线程来执行的。
- 这些工作线程的数量在创建工作队列时就已经确定,通常是固定的,或者通过指定特定的工作队列属性来控制线程数量。
- 工作队列的并发度是静态的,无法根据系统负载进行调整。
CMWQ(Concurrency Managed Workqueue)
- CMWQ 允许动态调整并发度,根据系统的负载来增加或减少工作队列中的工作线程数。
- CMWQ 主要用于在工作队列需要大量并发执行的场景中提高性能,尤其是在多核处理器的环境下,能够充分利用多核资源。
- CMWQ 内部机制会根据队列负载动态选择合适的工作线程数,从而更好地适应不同的运行时环境。
CMWQ 的工作原理
CMWQ 的基本工作方式是在传统工作队列的基础上加入了更智能的调度机制,能够自动调整并发度。具体来说,CMWQ 会考虑以下因素来动态调整工作线程的数量:
-
负载感知:CMWQ 机制可以通过监控工作队列的负载情况,自动增加或减少工作线程的数量。例如,当队列中的工作项积压较多时,CMWQ 会启动更多的工作线程来加速任务的处理;而当队列空闲时,减少不必要的工作线程来节省资源。
-
工作项的类型和优先级:不同的工作项可能有不同的优先级,CMWQ 机制可以根据任务的优先级来选择合适的工作线程和调度策略。
-
线程池管理:CMWQ 采用线程池机制来动态调整工作线程的数量,确保系统的负载均衡,同时避免过度分配资源导致不必要的开销。
CMWQ 的应用场景
- 高并发场景:当系统需要执行大量的并发任务时,CMWQ 可以通过动态管理并发度来提高任务执行的效率。例如,在网络驱动程序中,需要同时处理大量网络数据包,CMWQ 通过动态管理工作线程数,可以更高效地处理这些任务。
- 多核处理器:CMWQ 特别适合多核系统,它能通过灵活的并发管理充分利用多核 CPU 的资源,提高系统性能。
- 负载波动的场景:在一些负载变化较大的系统中,CMWQ 通过自动调整工作线程数,能够根据负载波动自适应地调整系统资源使用,避免过度分配资源或者资源浪费。
CMWQ 示例
CMWQ 通常是在需要动态并发度控制的高负载或多核系统中使用。下面是一个简单的例子,演示如何使用 CMWQ。
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/workqueue.h>
#include <linux/delay.h>
static struct workqueue_struct *my_cmwq;
static struct work_struct my_work;
static void my_work_function(struct work_struct *work)
{
pr_info("CMWQ 任务正在执行...\n");
msleep(1000);
pr_info("CMWQ 任务执行完成\n");
}
static int __init cmwq_example_init(void)
{
pr_info("模块初始化,创建 CMWQ...\n");
my_cmwq = create_singlethread_workqueue("my_cmwq");
if (!my_cmwq) {
pr_err("创建 CMWQ 失败\n");
return -ENOMEM;
}
INIT_WORK(&my_work, my_work_function);
queue_work(my_cmwq, &my_work);
return 0;
}
static void __exit cmwq_example_exit(void)
{
pr_info("模块退出,销毁 CMWQ...\n");
flush_workqueue(my_cmwq);
destroy_workqueue(my_cmwq);
}
module_init(cmwq_example_init);
module_exit(cmwq_example_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("CMWQ 示例");
在这个例子中,我们创建了一个 CMWQ 并提交了一个工作项,工作项的执行将被分配到 CMWQ 中的工作线程来完成。CMWQ 会根据实际负载管理工作线程的并发数。
三、CMWQ如何解决问题的呢?
3.1、设计原则
在进行CMWQ的时候遵循下面两个原则:
(1)和旧的workqueue接口兼容。
(2)明确的划分了workqueue的前端接口和后端实现机制。
CMWQ的整体架构如下:
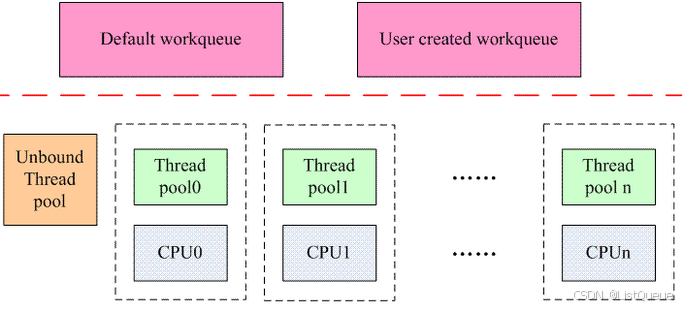
对于workqueue的用户而言,前端的操作包括二种:
一个是创建workqueue。可以选择创建自己的workqueue,当然也可以不创建而是使用系统缺省的workqueue。
另外一个操作就是将指定的work添加到workqueue。
在旧的workqueue机制中,workqueue和worker thread是密切联系的概念,对于single workqueue,创建一个系统范围的worker thread,对于multi workqueue,创建per-CPU的worker thread,一切都是固定死的。针对这样的设计,可以进一步思考其合理性。workqueue用户的需求就是一个异步执行的环境,把创建workqueue和创建worker thread绑定起来大大限定了资源的使用,其实具体后台是如何处理work,是否否启动了多个thread,如何管理多个线程之间的协调,workqueue的用户并不关心。
关于 CMWQ 中几个概念都是 work 相关的数据结构非常容易混淆,在内核文档中有一些通俗的介绍,大概可以这样来理解:
Documentation/core-api/workqueue.rst
- work :一份工作。
- workqueue :工作的集合(多个工作)。workqueue 和 work 是一对多的关系。
- worker :一个工作人员。在代码中 worker 对应一个
work_thread()内核线程(这里要注意,通常一个工作人员是可以干多个工作的[串行])。 - worker_pool:工作人员的集合。多个
work_thread()。worker_pool 和 worker 是一对多的关系。 - pwq(pool_workqueue):中间人 / 中介,负责建立起 workqueue 和 worker_pool 之间的关系。workqueue 和 pwq 是一对多的关系,pwq 和 worker_pool 是一对一的关系。
为了更好的说清楚CMWQ,举例理解:
示例场景:磁盘 I/O 和网络包处理
假设我们在内核中有两类任务:磁盘 I/O 任务和网络包处理任务。我们希望这两个任务能并发执行,但又不希望在系统负载较高时浪费过多的资源。
-
创建并初始化工作队列:
假设我们在内核中使用工作队列来处理磁盘 I/O 和网络包任务。我们首先定义一个工作队列,并初始化任务。
-
struct workqueue_struct *wq; INIT_WORK(&disk_io_work, disk_io_handler); INIT_WORK(&network_packet_work, network_packet_handler); wq = create_workqueue("my_workqueue"); -
提交任务到工作队列:
假设磁盘 I/O 和网络包处理是异步操作。当这两个任务发生时,系统会将它们提交到工作队列中。
-
queue_work(wq, &disk_io_work); queue_work(wq, &network_packet_work); -
调度任务并处理:
内核中的工作线程将从工作队列中取出任务并执行。对于 CMWQ,系统会根据负载情况自动调整并发度。假设在正常情况下,我们只需要 2 个工作线程来处理这两个任务。如果系统负载增大,内核可能会自动增加更多的线程。
-
负载动态调整:
假设磁盘 I/O 和网络包任务的负载发生变化。当系统的 CPU 使用率很高时,工作队列可能会调整并发度,减少工作线程数,以避免过度消耗资源。
如果磁盘 I/O 任务和网络任务都在同一时间到达并且队列中有很多任务,CMWQ 会根据实际的 CPU 负载和任务优先级来决定:
- 增加工作线程数,以便加速任务处理。
- 减少工作线程数,当任务处理完毕,系统空闲时,不浪费多余的资源。
-
优先级处理:
CMWQ 还会根据任务的优先级来处理队列中的任务。如果磁盘 I/O 任务是紧急的(例如高优先级任务),系统会优先处理磁盘 I/O 任务,而其他低优先级的任务(例如网络包处理)会稍微延后。
2.2、如何解决线程数目过多的问题?
每个执行 work 的线程叫做 worker,一组 worker 的集合叫做 worker_pool。CMWQ 的精髓就在 worker_pool 里面 worker 的动态增减管理上 manage_workers()。
在CMWQ中,用户可以根据自己的需求创建workqueue,但是已经和后端的线程池是否创建worker线程无关了,是否创建新的work线程是由worker线程池来管理。系统中的线程池包括两种:
(1)和特定CPU绑定的线程池。这种线程池有两种,一种叫做normal thread pool(nice = 0),另外一种叫做high priority thread pool(nice = HIGHPRI_NICE_LEVEL),分别用来管理普通的worker thread和高优先级的worker thread,而这两种thread分别用来处理普通的和高优先级的work。这种类型的线程池数目是固定的,和系统中cpu的数目相关,如果系统有n个cpu,如果都是online的,那么会创建2n个线程池,即一个cpu会创建一个normal thread pool和一个。high priority thread pool。
例如:
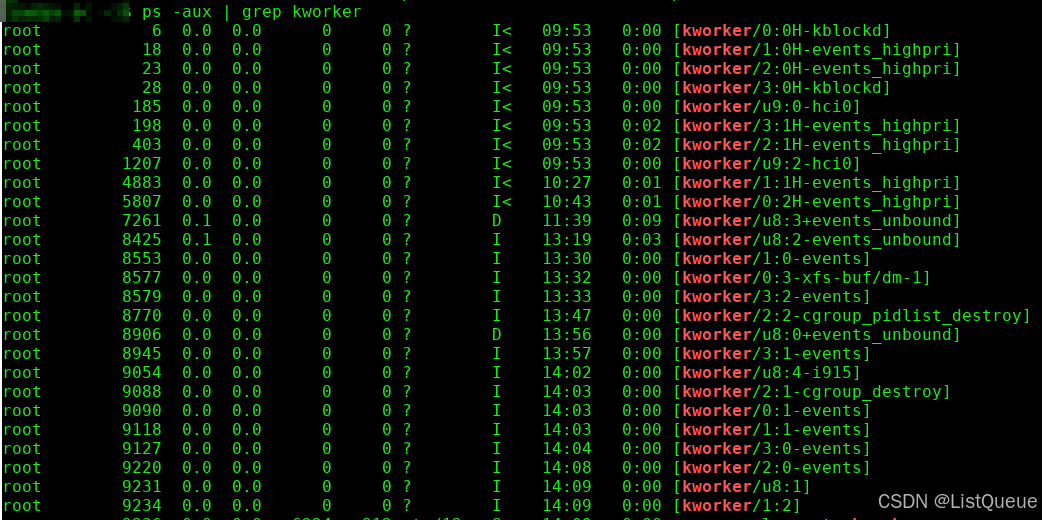
(2)unbound 线程池,可以运行在任意的cpu上。这种thread pool是动态创建的,是和thread pool的属性相关,包括该thread pool创建worker thread的优先级(nice value),可以运行的cpu链表等。如果系统中已经有了相同属性的thread pool,那么不需要创建新的线程池,否则需要创建。
CMWQ使用了一个非常简单的策略:
- 当thread pool中处于运行状态的worker thread等于0,并且有需要处理的work的时候,thread pool就会创建新的worker线程;
- running worker 在处理 work 的过程中进入了阻塞 suspend 状态,为了保持其他 work 的执行,需要唤醒新的 idle worker 来处理 work;
- 如果有 work 需要执行且 running worker 大于 1 个,会让多余的 running worker 进入 idle 状态;
- 如果没有 work 需要执行,会让所有 worker 进入 idle 状态;
- 当worker线程处于idle的时候,不会立刻销毁它,而是保持一段时间,如果这时候有创建新的worker的需求的时候,那么直接wakeup idle的worker即可。一段时间过去仍然没有事情处理,那么该worker thread会被销毁。
2.3、如何解决并发问题?
用某个cpu上的bound workqueue来描述该问题。假设有A B C D四个work在该cpu上运行,缺省的情况下,thread pool会创建一个worker来处理这四个work。在旧的workqueue中,A B C D四个work毫无疑问是串行在cpu上执行,假设B work阻塞了,那么C D都是无法执行下去,一直要等到B解除阻塞并执行完毕。
对于CMWQ,当B work阻塞了,thread pool可以感知到这一事件,这时候它会创建一个新的worker thread来处理C D这两个work,从而解决了并发的问题。由于解决了并发问题,实际上也解决了由于竞争一个execution context而引入的各种问题(例如dead lock)。
四、接口API
1、初始化work的接口保持不变,可以静态或者动态创建work。
include/linux/workqueue.h
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
#define DECLARE_DELAYED_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, 0)
include/linux/workqueue.h
#define __INIT_WORK(_work, _func, _onstack) \
do { \
static __maybe_unused struct lock_class_key __key; \
\
__INIT_WORK_KEY(_work, _func, _onstack, &__key); \
} while (0)
#define INIT_WORK(_work, _func) \
__INIT_WORK((_work), (_func), 0)
#define INIT_WORK_ONSTACK(_work, _func) \
__INIT_WORK((_work), (_func), 1)
2、调度work执行也保持和旧的workqueue一致。
加入自己设置的工作集合workqueue_struct 上。
include/linux/workqueue.h
extern bool queue_work_on(int cpu, struct workqueue_struct *wq,
struct work_struct *work);
extern bool queue_work_node(int node, struct workqueue_struct *wq,
struct work_struct *work);
extern bool queue_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct delayed_work *work, unsigned long delay);
extern bool mod_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay);
extern bool queue_rcu_work(struct workqueue_struct *wq, struct rcu_work *rwork);
/**
* queue_work - queue work on a workqueue
* @wq: workqueue to use
* @work: work to queue
*
* Returns %false if @work was already on a queue, %true otherwise.
*
* We queue the work to the CPU on which it was submitted, but if the CPU dies
* it can be processed by another CPU.
*/
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
{
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
}
加入work到系统默认的system_wq。on方式还是和之前一样,用来指定cpu.
include/linux/workqueue.h
/**
* schedule_work_on - put work task on a specific cpu
* @cpu: cpu to put the work task on
* @work: job to be done
*
* This puts a job on a specific cpu
*/
static inline bool schedule_work_on(int cpu, struct work_struct *work)
{
return queue_work_on(cpu, system_wq, work);
}
/**
* schedule_work - put work task in global workqueue
* @work: job to be done
*
* Returns %false if @work was already on the kernel-global workqueue and
* %true otherwise.
*
* This puts a job in the kernel-global workqueue if it was not already
* queued and leaves it in the same position on the kernel-global
* workqueue otherwise.
*/
static inline bool schedule_work(struct work_struct *work)
{
return queue_work(system_wq, work);
}
3、创建workqueue。和旧的create_workqueue接口不同,CMWQ采用了alloc_workqueue这样的接口符号,相关的接口定义如下:
/**
* alloc_ordered_workqueue - allocate an ordered workqueue
* @fmt: printf format for the name of the workqueue
* @flags: WQ_* flags (only WQ_FREEZABLE and WQ_MEM_RECLAIM are meaningful)
* @args...: args for @fmt
*
* Allocate an ordered workqueue. An ordered workqueue executes at
* most one work item at any given time in the queued order. They are
* implemented as unbound workqueues with @max_active of one.
*
* RETURNS:
* Pointer to the allocated workqueue on success, %NULL on failure.
*/
#define alloc_ordered_workqueue(fmt, flags, args...) \
alloc_workqueue(fmt, WQ_UNBOUND | __WQ_ORDERED | \
__WQ_ORDERED_EXPLICIT | (flags), 1, ##args)
#define create_workqueue(name) \
alloc_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, 1, (name))
#define create_freezable_workqueue(name) \
alloc_workqueue("%s", __WQ_LEGACY | WQ_FREEZABLE | WQ_UNBOUND | \
WQ_MEM_RECLAIM, 1, (name))
#define create_singlethread_workqueue(name) \
alloc_ordered_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, name)
在描述这些workqueue的接口之前,需要准备一些workqueue flag的知识。
include/linux/workqueue.h
/*
* Workqueue flags and constants. For details, please refer to
* Documentation/core-api/workqueue.rst.
*/
enum {
WQ_UNBOUND = 1 << 1, /* not bound to any cpu */
WQ_FREEZABLE = 1 << 2, /* freeze during suspend */
WQ_MEM_RECLAIM = 1 << 3, /* may be used for memory reclaim */
WQ_HIGHPRI = 1 << 4, /* high priority */
WQ_CPU_INTENSIVE = 1 << 5, /* cpu intensive workqueue */
WQ_SYSFS = 1 << 6, /* visible in sysfs, see wq_sysfs_register() */
/*
* Per-cpu workqueues are generally preferred because they tend to
* show better performance thanks to cache locality. Per-cpu
* workqueues exclude the scheduler from choosing the CPU to
* execute the worker threads, which has an unfortunate side effect
* of increasing power consumption.
*
* The scheduler considers a CPU idle if it doesn't have any task
* to execute and tries to keep idle cores idle to conserve power;
* however, for example, a per-cpu work item scheduled from an
* interrupt handler on an idle CPU will force the scheduler to
* excute the work item on that CPU breaking the idleness, which in
* turn may lead to more scheduling choices which are sub-optimal
* in terms of power consumption.
*
* Workqueues marked with WQ_POWER_EFFICIENT are per-cpu by default
* but become unbound if workqueue.power_efficient kernel param is
* specified. Per-cpu workqueues which are identified to
* contribute significantly to power-consumption are identified and
* marked with this flag and enabling the power_efficient mode
* leads to noticeable power saving at the cost of small
* performance disadvantage.
*
* http://thread.gmane.org/gmane.linux.kernel/1480396
*/
WQ_POWER_EFFICIENT = 1 << 7,
__WQ_DRAINING = 1 << 16, /* internal: workqueue is draining */
__WQ_ORDERED = 1 << 17, /* internal: workqueue is ordered */
__WQ_LEGACY = 1 << 18, /* internal: create*_workqueue() */
__WQ_ORDERED_EXPLICIT = 1 << 19, /* internal: alloc_ordered_workqueue() */
WQ_MAX_ACTIVE = 512, /* I like 512, better ideas? */
WQ_MAX_UNBOUND_PER_CPU = 4, /* 4 * #cpus for unbound wq */
WQ_DFL_ACTIVE = WQ_MAX_ACTIVE / 2,
};
- 标有WQ_UNBOUND这个flag的workqueue说明其work的处理不需要绑定在特定的CPU上执行,workqueue需要关联一个系统中的unbound worker thread pool。如果系统中能找到匹配的线程池(根据workqueue的属性(attribute)),那么就选择一个,如果找不到适合的线程池,workqueue就会创建一个worker thread pool来处理work。
- WQ_FREEZABLE是一个和电源管理相关的内容。在系统Hibernation或者suspend的时候,有一个步骤就是冻结用户空间的进程以及部分(标注freezable的)内核线程(包括workqueue的worker thread)。标记WQ_FREEZABLE的workqueue需要参与到进程冻结的过程中,worker thread被冻结的时候,会处理完当前所有的work,一旦冻结完成,那么就不会启动新的work的执行,直到进程被解冻。
- WQ_MEM_RECLAIM这个flag相关的概念是rescuer thread。所有可能在内存回收路径中使用的wq **必须**设置此标志。 无论内存压力如何,wq都保证至少具有执行上下文。。
- WQ_HIGHPRI说明挂入该workqueue的work是属于高优先级的work,需要高优先级的worker thread来处理。
- WQ_CPU_INTENSIVE这个flag说明挂入该workqueue的work是属于特别消耗cpu的那一类。为何要提供这样的flag呢?我们还是用老例子来说明。对于A B C D四个work,B是cpu intersive的,当thread正在处理B work的时候,该worker thread一直执行B work,因为它是cpu intensive的,特别吃cpu,这时候,thread pool是不会创建新的worker的,因为当前还有一个worker是running状态,正在处理B work。这时候C Dwork实际上是得不到执行,影响了并发。
了解了上面的内容,那么基本上alloc_workqueue中flag参数就明白了,下面转向max_active这个参数。系统不能允许创建太多的thread来处理挂入某个workqueue的work,最多能创建的线程数目是定义在max_active参数中。
除了alloc_workqueue接口API之外,还可以通过alloc_ordered_workqueue这个接口API来创建一个严格串行执行work的一个workqueue,并且该workqueue是unbound类型的。c
max_active确定每个CPU的最大执行上下文数,它可以分配给wq的工作项。例如,当max_active为16时,每个CPU最多可以同时执行16个wq的工作项。目前,对于绑定的wq, max_active的最大限制是512,指定0时使用的默认值是256.对于未绑定的wq,限制高于512和4 num_possible_cpus()。选择这些值足够高,使得它们不是限制因素,同时在失控情况下提供保护。
wq的活动工作项的数量通常由wq的用户调节,更具体地,由用户可以同时排队的工作项数量来调节。除非特别需要限制活动工作项的数量,否则建议指定0。
一些用户依赖于ST wq的严格执行顺序。 max_active1和WQ_UNBOUND的组合用于实现此行为。此类wq上的工作项始终排队到未绑定的工作池,并且在任何给定时间只能有一个工作项处于活动状态,从而实现与ST wq相同的排序属性。
在当前实现中,上述配置仅保证给定NUMA节点内的ST行为。相反,alloc_ordered_queue()`应该用于实现系统范围的ST行为。
五、举例
以下是一些实际应用场景,展示了 CMWQ 的具体应用:
1. 网络包处理(Networking)
在 Linux 网络栈中,处理网络包通常是一个耗时的异步任务。网络驱动将收到的包交给内核中的网络协议栈进行处理。为了避免阻塞和提高吞吐量,网络包的处理通常会通过工作队列来实现。
应用举例:
- 问题:当系统负载较低时,处理网络包的工作队列可以使用较少的线程来执行任务,以节省资源;而当网络流量激增时,工作队列的并发度需要增加,以便处理更多的数据包。
- 解决方案:使用 CMWQ,可以根据当前的 CPU 使用率和网络负载动态调整并发线程数。这样,在流量较高时,可以启动更多的工作线程来处理接收到的网络包;而在负载较低时,系统会减少工作线程数量,避免浪费资源。
示例代码:
struct workqueue_struct *wq;
INIT_WORK(&network_work, network_packet_handler);
wq = create_singlethread_workqueue("network_wq"); // 单线程工作队列
queue_work(wq, &network_work);
// 在负载较高时,动态调整工作队列的并发度
if (cpu_load_high()) {
wq = create_workqueue("network_wq_high"); // 创建更多线程的工作队列
}
2. 磁盘 I/O 处理
在 Linux 内核中,磁盘 I/O 操作通常是阻塞的。为了提高 I/O 操作的效率,内核会使用工作队列来异步处理磁盘操作。
应用举例:
- 问题:磁盘 I/O 操作可能会在系统负载较低时被快速处理,但在系统负载较高时,处理速度可能会变慢。CMWQ 可以根据负载情况调整处理磁盘 I/O 的工作线程数量。
- 解决方案:CMWQ 会根据当前负载动态分配线程数,从而保证在高负载情况下不会耗尽系统资源。对于低负载的情况下,可以减少线程,节省 CPU 资源。
示例代码:
struct workqueue_struct *disk_wq;
INIT_WORK(&disk_io_work, disk_io_handler);
disk_wq = create_singlethread_workqueue("disk_io_wq");
queue_work(disk_wq, &disk_io_work);
// 当系统负载较高时,增加更多的工作线程处理 I/O 操作
if (system_load_high()) {
disk_wq = create_workqueue("disk_io_wq_high"); // 动态增加工作线程
}
3. 异步任务调度:定时器任务
Linux 内核中的定时器任务(例如延时任务或周期性任务)通常会通过工作队列来实现异步处理。任务的执行并不立即发生,而是被放到工作队列中,等待一定时间后执行。
应用举例:
- 问题:对于一些定时器任务,任务的执行需要根据系统当前的负载来决定执行线程的数量。比如,高负载时不希望启动太多线程来执行定时器任务,而是保持较低的并发度。
- 解决方案:通过 CMWQ,可以在定时器任务到期后动态调整任务队列的并发数,确保系统负载不被过度增加。
示例代码:
struct workqueue_struct *timer_wq;
INIT_WORK(&timer_task_work, timer_task_handler);
timer_wq = create_singlethread_workqueue("timer_task_wq");
queue_work(timer_wq, &timer_task_work);
// 根据负载情况调整工作队列的并发度
if (high_load()) {
timer_wq = create_workqueue("timer_task_high_wq"); // 高负载时增加工作线程
}
4. USB 设备管理
在内核中,USB 设备的事件(如插入、拔出)通常通过工作队列异步处理。USB 驱动程序会将处理工作提交到工作队列中,以便在后台异步处理设备的状态变化。
应用举例:
- 问题:USB 设备的插入和拔出是非常频繁的操作,但对于低功耗设备而言,当系统负载较高时,USB 事件的处理不应该占用过多资源。
- 解决方案:CMWQ 可以根据当前系统负载动态调整 USB 事件的处理线程数。这样,在负载较高时,系统会减少处理线程数量,而在负载较低时,则可以增加线程并加速事件的处理。
示例代码:
struct workqueue_struct *usb_wq;
INIT_WORK(&usb_event_work, usb_event_handler);
usb_wq = create_singlethread_workqueue("usb_event_wq");
queue_work(usb_wq, &usb_event_work);
// 在负载较高时减少工作线程数量
if (system_high_load()) {
usb_wq = create_workqueue("usb_event_wq_low_threads");
} else {
usb_wq = create_workqueue("usb_event_wq_high_threads");
}
5. 异步日志记录
内核中,日志记录(如打印调试信息、错误信息等)通常是通过工作队列异步处理的。日志任务会被推送到工作队列中,工作线程会异步地将日志写入磁盘或输出设备。
应用举例:
- 问题:在高负载时,日志记录不应占用过多的 CPU 资源,而在低负载时,可以快速记录日志并处理。
- 解决方案:使用 CMWQ 可以根据系统负载动态调整日志处理的并发度。例如,在系统空闲时,更多的线程可以用来处理日志记录,而在负载较高时,减少线程以避免对系统性能的影响。
示例代码:
struct workqueue_struct *log_wq;
INIT_WORK(&log_task_work, log_task_handler);
log_wq = create_singlethread_workqueue("log_task_wq");
queue_work(log_wq, &log_task_work);
// 根据负载情况动态调整并发度
if (low_system_load()) {
log_wq = create_workqueue("log_task_wq_high"); // 低负载时增加更多线程
}

















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









