




Linux中断子系统10(基于Linux6.6)---中断之workqueue1
一、前情回顾
在许多情况下,需要异步流程执行上下文,而workqueue(wq)API是此类情况最常用的机制。
当需要这样的异步执行上下文时,描述要执行哪个函数的工作项放在队列中。 独立线程用作异步执行上下文。 该队列称为workqueue,该线程称为worker。 虽然工作队列中有工作项(work),但工作人员(worker)依次执行与工作项关联的功能。 当工作队列中没有剩余工作项时,工作人员变得空闲。 当新工作项排队时,工作再次开始执行。
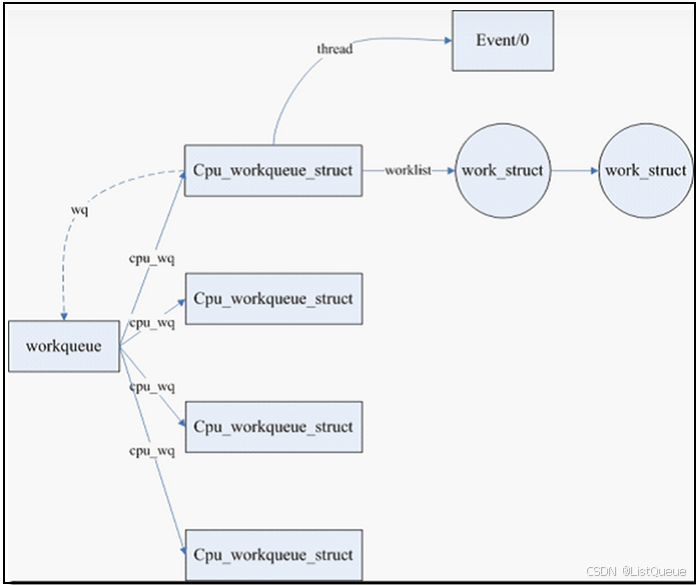
二、为何需要workqueue?
Workqueue 是内核里面很重要的一个机制,特别是内核驱动,一般的小型任务 (work) 都不会自己起一个线程来处理,而是扔到 Workqueue 中处理。Workqueue 的主要工作就是用进程上下文来处理内核中大量的小任务。
所以 Workqueue 的主要设计思想:一个是并行,多个 work 不要相互阻塞;另外一个是节省资源,多个 work 尽量共享资源 ( 进程、调度、内存 ),不要造成系统过多的资源浪费。
2.1、什么是中断上下文和进程上下文?
在 Linux 内核中,中断上下文(Interrupt Context)和进程上下文(Process Context)是两种不同的执行环境,它们在内核中有不同的特性和限制。了解这两者之间的差异,对于理解内核的执行模型非常重要。
1. 中断上下文(Interrupt Context)
中断上下文是指当硬件中断发生时,内核在处理中断时所处的执行环境。在这种上下文中,内核执行的代码是在硬件中断的处理函数中运行的,通常是由中断服务例程(ISR)触发的。
特点:
- 不可阻塞:中断上下文中,内核代码不能执行任何会阻塞的操作,比如
sleep、等待资源等。因为如果当前中断处理函数阻塞了,系统就无法处理其他中断,导致系统响应迟缓或死锁。 - 不能调用进程上下文的函数:中断上下文中不能调用那些涉及进程调度、信号处理等的进程上下文函数,比如
schedule()、msleep()等。 - 不属于任何进程:中断上下文不关联任何进程,因此在中断上下文中无法访问进程的资源(如用户空间内存、进程局部数据等)。
- 执行时间短:中断上下文应该尽可能地简短,避免阻塞其他中断的处理。长时间占用中断上下文会影响系统的实时性和性能。
- 共享资源:中断上下文可以访问共享的内核资源,但需要小心同步(如使用锁)以避免数据竞争。
示例:
中断处理函数通常在中断上下文中执行。例如,当网卡接收到数据包时,它会生成一个中断,内核的中断服务例程(ISR)会在中断上下文中处理这个事件。
static irqreturn_t my_irq_handler(int irq, void *dev_id)
{
// 中断上下文中的代码
// 处理硬件中断,不允许进行阻塞操作
pr_info("Interrupt handled\n");
return IRQ_HANDLED;
}
2. 进程上下文(Process Context)
进程上下文是指内核执行代码时,处于一个进程的上下文中,这种情况下代码是由内核线程或者用户空间的进程触发的。换句话说,进程上下文是在处理用户进程或者内核线程请求时,内核为该进程执行的代码。
特点:
- 可阻塞:与中断上下文不同,进程上下文中的代码可以执行阻塞操作。比如,可以调用
schedule()来让当前进程主动放弃 CPU,或者调用sleep()来让进程进入休眠。 - 属于进程:进程上下文中执行的代码属于某个进程(或者内核线程),可以访问该进程的资源(如用户空间的内存、进程局部数据等)。
- 可以进行进程调度:在进程上下文中,内核可以调用进程调度函数(如
schedule()),允许系统根据需要切换到其他进程。 - 执行时间较长:进程上下文通常用于处理较为复杂的任务,因为它允许阻塞和较长时间的执行。
示例:
当系统调用(如文件读写)或者内核线程执行时,内核会进入进程上下文。例如,在 read() 系统调用中,内核会进入进程上下文来处理文件读取操作。
ssize_t my_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
// 这是进程上下文中的代码
// 这里可以进行阻塞操作,处理文件读取
pr_info("Reading data from file\n");
return 0;
}
中断上下文和进程上下文的区别
| 特性 | 中断上下文 | 进程上下文 |
|---|---|---|
| 执行上下文 | 中断服务例程(ISR) | 系统调用或内核线程等 |
| 阻塞 | 不允许阻塞(不能调用 sleep 等函数) | 可以阻塞(调用 schedule、sleep 等) |
| 进程关联性 | 不关联任何进程 | 关联当前进程或内核线程 |
| 可以进行调度 | 不允许调度(不调用 schedule() 等) | 可以调用 schedule() 来进行进程调度 |
| 执行时间 | 应尽量短,避免影响中断处理 | 可以较长时间执行,适合复杂任务 |
| 锁机制 | 不允许持有进程锁,必须小心同步 | 可以持有进程锁,并进行进程间同步 |
3. 中断上下文和进程上下文的切换
在 Linux 内核中,中断和进程之间的切换是由硬件中断和内核调度器控制的。每当发生硬件中断时,内核会从当前进程上下文切换到中断上下文,并执行中断处理函数。当中断处理完成后,内核会返回到中断之前的上下文,通常是进程上下文。
- 中断上下文到进程上下文:中断处理完毕后,内核会调度相应的进程或者内核线程继续执行。如果在中断处理过程中调用了
tasklet或者workqueue等,内核会将这些任务推迟到进程上下文中执行。 - 进程上下文到中断上下文:在进程上下文执行时,如果发生硬件中断,内核会暂停当前进程的执行,进入中断上下文处理相应的中断,然后返回进程上下文继续执行。
2.2、如何判定当前的context?
代码如何知道自己的上下文呢?结合代码来进一步分析。in_irq()是用来判断是否在hard interrupt context的,in_irq()是如何定义的:include/linux/preempt.h
#define in_irq() (hardirq_count())
#define hardirq_count() (preempt_count() & HARDIRQ_MASK)
top half的处理是被irq_enter()和irq_exit()所包围,在irq_enter函数中会调用preempt_count_add(HARDIRQ_OFFSET),为hardirq count的bit field增加1。在irq_exit函数中,会调用preempt_count_sub(HARDIRQ_OFFSET),为hardirq count的bit field减去1。因此,只要in_irq非零,则说明在中断上下文并且处于top half部分。
解决了hard interrupt context,来看software interrupt context。如何判定代码当前正在执行bottom half(softirq、tasklet、timer)呢?in_serving_softirq给出了答案:
include/linux/preempt.h
#define in_serving_softirq() (softirq_count() & SOFTIRQ_OFFSET)
in_softirq定义了更大的一个区域,不仅仅包括了in_serving_softirq上下文,还包括了disable bottom half的场景。下图描述:
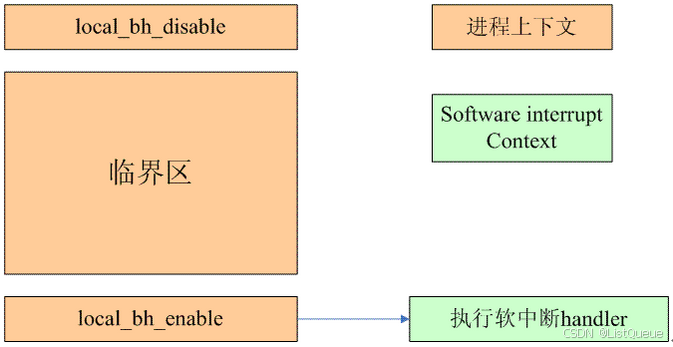
在进程上下文中,由于内核同步的要求可能会禁止softirq。这时候,kernel提供了local_bf_enable和local_bf_disable这样的接口函数,这种场景下,在local_bf_enable函数中会执行软中断handler(在临界区中,虽然raise了softirq,但是由于disable了bottom half,因此无法执行,只有等到enable的时候第一时间执行该softirq handler)。in_softirq包括了进程上下文中disable bottom half的临界区部分,而in_serving_softirq精准的命中了software interrupt context。
内核中还有一个in_interrupt的宏定义,从它的名字上看似乎是定义了hard interrupt context和software interrupt context,到底是怎样的呢?
include/linux/preempt.h
#define in_interrupt() (irq_count())
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK \
| NMI_MASK))
include/linux/preempt.h
#define in_nmi() (preempt_count() & NMI_MASK)
#define in_task() (!(preempt_count() & \
(NMI_MASK | HARDIRQ_MASK | SOFTIRQ_OFFSET)))
HARDIRQ_MASK定义了hard interrupt contxt,NMI_MASK定义了NMI(对于ARM是FIQ)类型的hard interrupt context,SOFTIRQ_MASK包括software interrupt context加上禁止softirq情况下的进程上下文。因此,in_interrupt()除了包括了中断上下文的场景,还包括了进程上下文禁止softirq的场景。
还有一个in_atomic的宏定义,如下。include/linux/preempt.h
/*
* Are we running in atomic context? WARNING: this macro cannot
* always detect atomic context; in particular, it cannot know about
* held spinlocks in non-preemptible kernels. Thus it should not be
* used in the general case to determine whether sleeping is possible.
* Do not use in_atomic() in driver code.
*/
#define in_atomic() (preempt_count() != 0)
2.3、为何中断上下文不能sleep?
中断上下文中不能调用 sleep() 等阻塞操作,主要是因为中断上下文和进程上下文的执行环境和目的不同。以下是具体原因:
1. 中断上下文不能被打断
- 中断上下文的特性:当一个硬件中断发生时,内核会暂停当前的进程或线程,并转到中断服务例程(ISR)处理当前的硬件中断。在中断上下文中,内核代码通常需要迅速完成,以便尽快返回处理其他中断或继续执行当前进程。如果中断上下文中发生了阻塞操作(如调用
sleep()),就会导致当前中断无法及时返回,也无法继续处理其他中断。这样,系统的响应性和实时性会受到严重影响。 - 不可打断的执行:中断上下文中不允许调用阻塞操作的原因之一是,执行这些操作会导致中断无法“迅速”返回,而是被长时间占用。这种情况在系统要求高实时性和快速响应时(如嵌入式系统、网络数据包处理等)特别不可接受。
2. 中断上下文中的调度不可能进行
- 调度行为的限制:
sleep()和类似的函数通常会将当前进程或线程置于等待状态,并将 CPU 资源让给其他任务。这个过程通常会调用进程调度机制(例如schedule())。然而,在中断上下文中,不允许进行调度操作,因为调度本身涉及到进程的切换,而这通常会依赖于进程的上下文。如果在中断处理函数中调用sleep(),会引起对调度的依赖,这会导致系统不能及时响应新的中断请求,或者在处理其他中断时出现延迟。
中断上下文的目标是快速响应硬件事件,并尽量避免影响其他中断的处理。如果允许 sleep() 等阻塞操作,可能会导致调度过程挂起,而这一过程是不可容忍的。
3. 中断上下文与进程上下文的独立性
-
不属于进程:中断上下文中的代码不属于任何进程,因此无法使用进程上下文的调度机制。
sleep()等函数通常依赖于进程调度,如果中断上下文中调用这些函数,内核无法将其挂起在一个调度队列中。这样会导致内核无法继续有效地调度其他任务,甚至可能发生死锁。 -
中断与进程调度的分离:内核区分中断上下文和进程上下文,就是为了保证中断处理的效率和及时性。进程上下文中允许进行阻塞操作和调度(例如
sleep()),因为此时内核处于与用户空间进程的上下文中,可以让出 CPU 资源,等待资源的到来或其他条件满足。而中断上下文中的执行时间是非常有限的,不能让出 CPU 资源。
4. 死锁风险
- 死锁的可能性:如果在中断上下文中允许调用
sleep(),就可能导致死锁的情况。例如,假设一个中断上下文需要获取某个资源(如锁)来完成其工作,但在中断上下文中无法持有锁(锁通常只在进程上下文中使用),如果它被sleep()挂起,然后另一个进程请求相同的资源,这时可能会导致死锁,系统无法继续正常运行。
5. 快速响应的要求
- 中断处理的时间要求:中断上下文的设计要求中断服务函数尽量简短高效,避免进行任何会导致中断延迟的操作。
sleep()等函数会导致处理的时间不确定,因此不允许在中断上下文中调用。
2.4、为何需要workqueue
workqueue和其他的bottom half最大的不同是它是运行在进程上下文中的,它可以睡眠,这和其他bottom half机制有本质的不同,大大方便了中断处理代码。当然,驱动模块也可以自己创建一个kernel thread来解决defering work,但是,如果每个driver都创建自己的kernel thread,那么内核线程数量过多,这会影响整体的性能。因此,最好的方法就是把这些需求汇集起来,提供一个统一的机制,也就是传说中的work queue了。
三、workqueue数据抽象
3.1、workqueue
定义如下:kernel/workqueue.c
/*
* The externally visible workqueue. It relays the issued work items to
* the appropriate worker_pool through its pool_workqueues.
*/
struct workqueue_struct {
struct list_head pwqs; /* WR: all pwqs of this wq */
struct list_head list; /* PR: list of all workqueues */
struct mutex mutex; /* protects this wq */
int work_color; /* WQ: current work color */
int flush_color; /* WQ: current flush color */
atomic_t nr_pwqs_to_flush; /* flush in progress */
struct wq_flusher *first_flusher; /* WQ: first flusher */
struct list_head flusher_queue; /* WQ: flush waiters */
struct list_head flusher_overflow; /* WQ: flush overflow list */
struct list_head maydays; /* MD: pwqs requesting rescue */
struct worker *rescuer; /* MD: rescue worker */
int nr_drainers; /* WQ: drain in progress */
int saved_max_active; /* WQ: saved pwq max_active */
struct workqueue_attrs *unbound_attrs; /* PW: only for unbound wqs */
struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */
#ifdef CONFIG_SYSFS
struct wq_device *wq_dev; /* I: for sysfs interface */
#endif
#ifdef CONFIG_LOCKDEP
char *lock_name;
struct lock_class_key key;
struct lockdep_map lockdep_map;
#endif
char name[WQ_NAME_LEN]; /* I: workqueue name */
/*
* Destruction of workqueue_struct is RCU protected to allow walking
* the workqueues list without grabbing wq_pool_mutex.
* This is used to dump all workqueues from sysrq.
*/
struct rcu_head rcu;
/* hot fields used during command issue, aligned to cacheline */
unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */
struct pool_workqueue __percpu __rcu **cpu_pwq; /* I: per-cpu pwqs */
};
static struct kmem_cache *pwq_cache;
workqueue就是一种把某些任务(work)推迟到一个或者一组内核线程中去执行,那个内核线程被称作worker thread(每个processor上有一个work thread)。系统中所有的workqueue会挂入一个全局链表,链表头定义如下:
static LIST_HEAD(workqueues);
list成员就是用来挂入workqueue链表的。
singlethread是workqueue的一个特殊模式,一般而言,当创建一个workqueue的时候会为每一个系统内的processor创建一个内核线程,该线程处理本cpu调度的work。但是有些场景中,创建per-cpu的worker thread有些浪费(或者有一些其他特殊的考量),这时候创建single-threaded workqueue是一个更合适的选择。
freezeable成员是一个和电源管理相关的一个flag,当系统suspend的时候,有一个阶段会将所有的用户空间的进程冻结,那么是否也冻结内核线程(包括workqueue)呢?缺省情况下,所有的内核线程都是nofrezable的,当然也可以调用set_freezable让一个内核线程是可以被冻结的。具体是否需要设定该flag是和程序逻辑相关的,具体情况具体分析。
rt用来调整worker_therad线程所在进程的调度策略。
3.2、work
定义如下:include/linux/workqueue.h
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
#define WORK_DATA_INIT() ATOMIC_LONG_INIT((unsigned long)WORK_STRUCT_NO_POOL)
#define WORK_DATA_STATIC_INIT() \
ATOMIC_LONG_INIT((unsigned long)(WORK_STRUCT_NO_POOL | WORK_STRUCT_STATIC))
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
所谓work就是异步执行的函数?
如果该函数的代码中有些需要sleep的场景的时候,那么在中断上下文中直接调用将产生严重的问题。这时候,就需要到进程上下文中异步执行。
仔细看看各个成员:func就是这个异步执行的函数,当work被调度执行的时候其实就是调用func这个callback函数,该函数的定义如下:include/linux/workqueue.h
typedef void (*work_func_t)(struct work_struct *work);
work对应的callback函数需要传递该work的struct作为callback函数的参数。work是被组织成队列的,entry成员就是挂入队列的那个节点,data包含了该work的状态flag和挂入workqueue的信息。
四、总结
上文中描述的各个数据结构集合在一起,具体请参考下图:
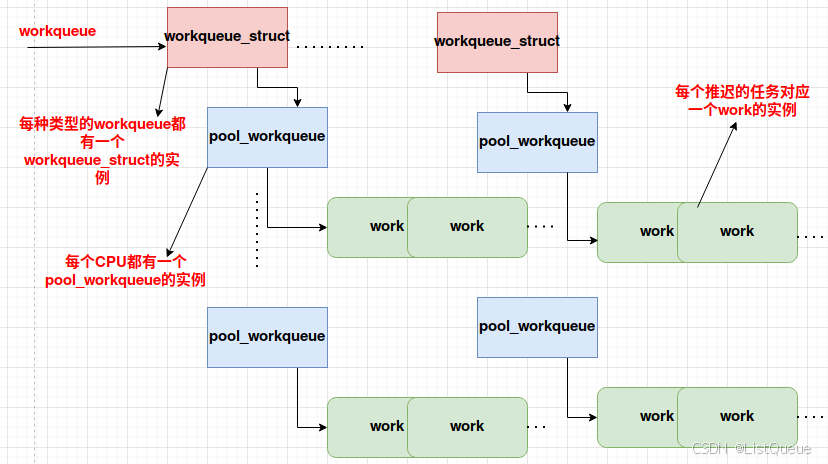
自上而下来描述各个数据结构。首先,系统中包括若干的workqueue,最著名的workqueue就是系统缺省的的workqueue了,定义如下:
static struct workqueue_struct *keventd_wq __read_mostly;
如果没有特别的性能需求,那么一般驱动使用keventd_wq就可以了,毕竟系统创建太多内核线程也不是什么好事情(消耗太多资源)。当然,如果有需要,驱动模块可以创建自己的workqueue。因此,系统中存在一个workqueues的链表,管理了所有的workqueue实例。一个workqueue对应一组work thread(先不考虑single thread的场景),每个cpu一个,由cpu_workqueue_struct来抽象,这些cpu_workqueue_struct们共享一个workqueue,毕竟这些worker thread是同一种type。
从底层驱动的角度来看,只关心如何处理deferable task(由work_struct抽象)。驱动程序定义了work_struct,其func成员就是deferred work,然后挂入work list就OK了(当然要唤醒worker thread了),系统的调度器调度到worker thread的时候,该work自然会被处理了。当然,挂入哪一个workqueue的那一个worker thread呢?如何选择workqueue是driver自己的事情,可以使用系统缺省的workqueue,简单,实用。当然也可以自己创建一个workqueue,并把work挂入其中。选择哪一个worker thread比较简单:work在哪一个cpu上被调度,那么就挂入哪一个worker thread。
五、接口以及内部实现
5.1、初始化一个work
静态定义一个work,接口如下:include/linux/workqueue.h
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
#define DECLARE_DELAYED_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, 0)
#define DECLARE_DEFERRABLE_WORK(n, f) \
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, TIMER_DEFERRABLE)
一般而言,work都是推迟到worker thread被调度的时刻,但是有时候,希望在指定的时间过去之后再调度worker thread来处理该work,这种类型的work被称作delayed work,DECLARE_DELAYED_WORK用来初始化delayed work,它的概念和普通work类似,是由内核定时器实现的。include/linux/workqueue.h
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
动态创建也是OK的,不过初始化的时候需要把work的指针传递给INIT_WORK,定义如下:
include/linux/workqueue.h
#define INIT_WORK(_work, _func) \
__INIT_WORK((_work), (_func), 0)
#define INIT_WORK_ONSTACK(_work, _func) \
__INIT_WORK((_work), (_func), 1)
#define INIT_WORK_ONSTACK_KEY(_work, _func, _key) \
__INIT_WORK_KEY((_work), (_func), 1, _key)
5.2、调度一个work执行
调度work执行有两个接口,一个是schedule_work,将work挂入缺省的系统workqueue(keventd_wq),另外一个是queue_work,可以将work挂入指定的workqueue。具体代码如下:include/linux/workqueue.h
/**
* schedule_work - put work task in global workqueue
* @work: job to be done
*
* Returns zero if @work was already on the kernel-global workqueue and
* non-zero otherwise.
*
* This puts a job in the kernel-global workqueue if it was not already
* queued and leaves it in the same position on the kernel-global
* workqueue otherwise.
*/
int schedule_work(struct work_struct *work)
{
return queue_work(keventd_wq, work);
}
include/linux/workqueue.h
static inline bool queue_work(struct workqueue_struct *wq,
struct work_struct *work)
{
return queue_work_on(WORK_CPU_UNBOUND, wq, work);
}
kernel/workqueue.c
/**
* queue_work_on - queue work on specific cpu
* @cpu: CPU number to execute work on
* @wq: workqueue to use
* @work: work to queue
*
* Returns 0 if @work was already on a queue, non-zero otherwise.
*
* We queue the work to a specific CPU, the caller must ensure it
* can't go away.
*/
int
queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work)
{
int ret = 0;
if (!test_and_set_bit(WORK_STRUCT_PENDING, work_data_bits(work))) {
BUG_ON(!list_empty(&work->entry));
__queue_work(wq_per_cpu(wq, cpu), work); //挂入work list并唤醒worker thread
ret = 1;
}
return ret;
}
处于pending状态的work不会重复挂入workqueue。假设A驱动模块静态定义了一个work,当中断到来并分发给cpu0的时候,中断handler会在cpu0上执行,在handler中会调用schedule_work将该work挂入cpu0的worker thread,也就是keventd 0的work list。
在worker thread处理A驱动的work之前,中断很可能再次触发并分发给cpu1执行,这时候,在cpu1上执行的handler在调用schedule_work的时候实际上是没有任何具体的动作的,也就是说该work不会挂入keventd 1的work list,因为该work还pending在keventd 0的work list中。
5.3、创建workqueue
接口如下:include/linux/workqueue.h
#define create_workqueue(name) \
alloc_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, 1, (name))
#define create_freezable_workqueue(name) \
alloc_workqueue("%s", __WQ_LEGACY | WQ_FREEZABLE | WQ_UNBOUND | \
WQ_MEM_RECLAIM, 1, (name))
#define create_singlethread_workqueue(name) \
alloc_ordered_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, name)
create_workqueue是创建普通workqueue,也就是每个cpu创建一个worker thread的那种。当然,作为“普通”的workqueue,在freezeable属性上也是跟随缺省的行为,即在suspend的时候不冻结该内核线程的worker thread。create_freezeable_workqueue和create_singlethread_workqueue都是创建single thread workqueue,只不过一个是freezeable的,另外一个是non-freezeable的。的代码如下:kernel/workqueue.c
__printf(1, 4)
struct workqueue_struct *alloc_workqueue(const char *fmt,
unsigned int flags,
int max_active, ...)
{
va_list args;
struct workqueue_struct *wq;
struct pool_workqueue *pwq;
/*
* Unbound && max_active == 1 used to imply ordered, which is no longer
* the case on many machines due to per-pod pools. While
* alloc_ordered_workqueue() is the right way to create an ordered
* workqueue, keep the previous behavior to avoid subtle breakages.
*/
if ((flags & WQ_UNBOUND) && max_active == 1)
flags |= __WQ_ORDERED;
/* see the comment above the definition of WQ_POWER_EFFICIENT */
if ((flags & WQ_POWER_EFFICIENT) && wq_power_efficient)
flags |= WQ_UNBOUND;
/* allocate wq and format name */
wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
return NULL;
if (flags & WQ_UNBOUND) {
wq->unbound_attrs = alloc_workqueue_attrs();
if (!wq->unbound_attrs)
goto err_free_wq;
}
va_start(args, max_active);
vsnprintf(wq->name, sizeof(wq->name), fmt, args);
va_end(args);
max_active = max_active ?: WQ_DFL_ACTIVE;
max_active = wq_clamp_max_active(max_active, flags, wq->name);
/* init wq */
wq->flags = flags;
wq->saved_max_active = max_active;
mutex_init(&wq->mutex);
atomic_set(&wq->nr_pwqs_to_flush, 0);
INIT_LIST_HEAD(&wq->pwqs);
INIT_LIST_HEAD(&wq->flusher_queue);
INIT_LIST_HEAD(&wq->flusher_overflow);
INIT_LIST_HEAD(&wq->maydays);
wq_init_lockdep(wq);
INIT_LIST_HEAD(&wq->list);
if (alloc_and_link_pwqs(wq) < 0)
goto err_unreg_lockdep;
if (wq_online && init_rescuer(wq) < 0)
goto err_destroy;
if ((wq->flags & WQ_SYSFS) && workqueue_sysfs_register(wq))
goto err_destroy;
/*
* wq_pool_mutex protects global freeze state and workqueues list.
* Grab it, adjust max_active and add the new @wq to workqueues
* list.
*/
mutex_lock(&wq_pool_mutex);
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq)
pwq_adjust_max_active(pwq);
mutex_unlock(&wq->mutex);
list_add_tail_rcu(&wq->list, &workqueues);
mutex_unlock(&wq_pool_mutex);
return wq;
err_unreg_lockdep:
wq_unregister_lockdep(wq);
wq_free_lockdep(wq);
err_free_wq:
free_workqueue_attrs(wq->unbound_attrs);
kfree(wq);
return NULL;
err_destroy:
destroy_workqueue(wq);
return NULL;
}
EXPORT_SYMBOL_GPL(alloc_workqueue);
解析:
-
flags的检查和处理: -
if ((flags & WQ_UNBOUND) && max_active == 1) flags |= __WQ_ORDERED;- 这里的判断表示:如果工作队列是无绑定(unbound)并且
max_active为 1,那么将flags加上__WQ_ORDERED,即将其设置为有序工作队列。过去的行为是unbound且max_active == 1会自动成为有序的,但现在有些机器由于 per-pod pools(每个 CPU 核心上的工作队列池)导致不再是这样,所以需要显式地设置。
- 这里的判断表示:如果工作队列是无绑定(unbound)并且
-
内存分配和初始化:
-
wq = kzalloc(sizeof(*wq), GFP_KERNEL); if (!wq) return NULL;- 使用
kzalloc分配workqueue_struct结构体的内存,内存清零。如果分配失败,返回NULL。
- 使用
-
处理
unbound属性: -
if (flags & WQ_UNBOUND) { wq->unbound_attrs = alloc_workqueue_attrs(); if (!wq->unbound_attrs) goto err_free_wq; }- 如果工作队列是
unbound类型,那么就为其分配额外的属性unbound_attrs。如果分配失败,跳转到错误处理部分,释放已经分配的内存。
- 如果工作队列是
-
格式化工作队列名称:
-
va_start(args, max_active); vsnprintf(wq->name, sizeof(wq->name), fmt, args); va_end(args);- 使用
vsnprintf格式化工作队列的名称,并将可变参数写入wq->name。
- 使用
-
最大并发工作数调整:
-
max_active = max_active ?: WQ_DFL_ACTIVE; max_active = wq_clamp_max_active(max_active, flags, wq->name);- 这里使用了 C 语言中的条件运算符:
max_active为 0 时,使用默认值WQ_DFL_ACTIVE。然后通过wq_clamp_max_active函数调整max_active,确保它符合工作队列的属性限制。
- 这里使用了 C 语言中的条件运算符:
-
初始化工作队列结构:
-
wq->flags = flags; wq->saved_max_active = max_active; mutex_init(&wq->mutex); atomic_set(&wq->nr_pwqs_to_flush, 0); INIT_LIST_HEAD(&wq->pwqs); INIT_LIST_HEAD(&wq->flusher_queue); INIT_LIST_HEAD(&wq->flusher_overflow); INIT_LIST_HEAD(&wq->maydays);- 设置工作队列的标志和最大并发数。
- 初始化互斥锁
wq->mutex和原子变量wq->nr_pwqs_to_flush,用于同步和控制工作队列的状态。 - 初始化多个双向链表,管理不同的队列和任务,例如:
pwqs、flusher_queue等。
-
初始化锁依赖:
-
wq_init_lockdep(wq); INIT_LIST_HEAD(&wq->list);- 初始化锁依赖关系,用于跟踪锁的使用,以避免死锁。
-
为工作队列分配并链接池(
pwqs): -
if (alloc_and_link_pwqs(wq) < 0) goto err_unreg_lockdep;- 调用
alloc_and_link_pwqs函数分配并连接工作队列池(pwqs),如果失败,跳转到错误处理部分。
- 调用
-
初始化工作队列的 "rescuer" 线程:
-
if (wq_online && init_rescuer(wq) < 0) goto err_destroy;- 如果工作队列是在线的(
wq_online),则初始化工作队列的 "rescuer" 线程,负责抢救失效的工作队列任务。
- 如果工作队列是在线的(
-
注册工作队列的 SysFS 接口:
-
if ((wq->flags & WQ_SYSFS) && workqueue_sysfs_register(wq)) goto err_destroy;- 如果工作队列支持 SysFS 接口,尝试注册该接口。
-
调整最大并发数并将工作队列添加到全局工作队列列表:
mutex_lock(&wq_pool_mutex);
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq)
pwq_adjust_max_active(pwq);
mutex_unlock(&wq->mutex);
list_add_tail_rcu(&wq->list, &workqueues);
mutex_unlock(&wq_pool_mutex);
- 获取全局锁
wq_pool_mutex,然后调整工作队列池中每个池的最大并发数,并将工作队列添加到全局的工作队列链表中。
在 Linux 6.x 版本中,工作队列机制进行了改进,主要的变化包括:
-
内核线程管理的变化:原来使用
create_workqueue_thread()创建的工作线程,现在已经被新的线程管理机制所取代。新的工作队列机制使用workqueues结构来管理任务,而不再直接依赖于手动创建和管理工作线程。内核会根据负载和需要自动管理工作线程。 -
工作队列的改进:在 Linux 6.x 中,工作队列的实现细节发生了一些变化,工作队列的线程不再是显式创建的,而是通过内核的工作队列框架动态地管理。这意味着,开发者在使用工作队列时,不再需要手动管理工作线程的生命周期。内核会自动为工作队列分配和调度内核线程。
-
内存管理和资源优化:内核对于工作队列的管理进行了性能优化,包括对线程池的更好管理以及对内存资源的优化。在 Linux 6.x 中,工作队列的处理更高效,支持更高并发性和更低的开销。
5.4、work执行的时机
work执行的时机是和调度器相关的,当系统调度到worker thread这个内核线程后,该thread就会开始工作。每个cpu上执行的worker thread的内核线程的代码逻辑都是一样的,在worker_thread中实现:
而worker_thread也则是workqueue_init中实现创建的。kernel/workqueue.c
void __init workqueue_init(void)
{
struct workqueue_struct *wq;
struct worker_pool *pool;
int cpu, bkt;
wq_cpu_intensive_thresh_init();
mutex_lock(&wq_pool_mutex);
/*
* Per-cpu pools created earlier could be missing node hint. Fix them
* up. Also, create a rescuer for workqueues that requested it.
*/
for_each_possible_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->node = cpu_to_node(cpu);
}
}
list_for_each_entry(wq, &workqueues, list) {
WARN(init_rescuer(wq),
"workqueue: failed to create early rescuer for %s",
wq->name);
}
mutex_unlock(&wq_pool_mutex);
/* create the initial workers */
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
hash_for_each(unbound_pool_hash, bkt, pool, hash_node)
BUG_ON(!create_worker(pool));
wq_online = true;
wq_watchdog_init();
}
kernel/workqueue.c
/**
* create_worker - create a new workqueue worker
* @pool: pool the new worker will belong to
*
* Create and start a new worker which is attached to @pool.
*
* CONTEXT:
* Might sleep. Does GFP_KERNEL allocations.
*
* Return:
* Pointer to the newly created worker.
*/
static struct worker *create_worker(struct worker_pool *pool)
{
struct worker *worker;
int id;
char id_buf[23];
/* ID is needed to determine kthread name */
id = ida_alloc(&pool->worker_ida, GFP_KERNEL);
if (id < 0) {
pr_err_once("workqueue: Failed to allocate a worker ID: %pe\n",
ERR_PTR(id));
return NULL;
}
worker = alloc_worker(pool->node);
if (!worker) {
pr_err_once("workqueue: Failed to allocate a worker\n");
goto fail;
}
worker->id = id;
if (pool->cpu >= 0)
snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
pool->attrs->nice < 0 ? "H" : "");
else
snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
if (IS_ERR(worker->task)) {
if (PTR_ERR(worker->task) == -EINTR) {
pr_err("workqueue: Interrupted when creating a worker thread \"kworker/%s\"\n",
id_buf);
} else {
pr_err_once("workqueue: Failed to create a worker thread: %pe",
worker->task);
}
goto fail;
}
set_user_nice(worker->task, pool->attrs->nice);
kthread_bind_mask(worker->task, pool_allowed_cpus(pool));
/* successful, attach the worker to the pool */
worker_attach_to_pool(worker, pool);
/* start the newly created worker */
raw_spin_lock_irq(&pool->lock);
worker->pool->nr_workers++;
worker_enter_idle(worker);
kick_pool(pool);
/*
* @worker is waiting on a completion in kthread() and will trigger hung
* check if not woken up soon. As kick_pool() might not have waken it
* up, wake it up explicitly once more.
*/
wake_up_process(worker->task);
raw_spin_unlock_irq(&pool->lock);
return worker;
fail:
ida_free(&pool->worker_ida, id);
kfree(worker);
return NULL;
}
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct worker_pool *pool = worker->pool;
/* tell the scheduler that this is a workqueue worker */
set_pf_worker(true);
woke_up:
raw_spin_lock_irq(&pool->lock);
/* am I supposed to die? */
if (unlikely(worker->flags & WORKER_DIE)) {
raw_spin_unlock_irq(&pool->lock);
set_pf_worker(false);
set_task_comm(worker->task, "kworker/dying");
ida_free(&pool->worker_ida, worker->id);
worker_detach_from_pool(worker);
WARN_ON_ONCE(!list_empty(&worker->entry));
kfree(worker);
return 0;
}
worker_leave_idle(worker);
recheck:
/* no more worker necessary? */
if (!need_more_worker(pool))
goto sleep;
/* do we need to manage? */
if (unlikely(!may_start_working(pool)) && manage_workers(worker))
goto recheck;
/*
* ->scheduled list can only be filled while a worker is
* preparing to process a work or actually processing it.
* Make sure nobody diddled with it while I was sleeping.
*/
WARN_ON_ONCE(!list_empty(&worker->scheduled));
/*
* Finish PREP stage. We're guaranteed to have at least one idle
* worker or that someone else has already assumed the manager
* role. This is where @worker starts participating in concurrency
* management if applicable and concurrency management is restored
* after being rebound. See rebind_workers() for details.
*/
worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
if (assign_work(work, worker, NULL))
process_scheduled_works(worker);
} while (keep_working(pool));
worker_set_flags(worker, WORKER_PREP);
sleep:
/*
* pool->lock is held and there's no work to process and no need to
* manage, sleep. Workers are woken up only while holding
* pool->lock or from local cpu, so setting the current state
* before releasing pool->lock is enough to prevent losing any
* event.
*/
worker_enter_idle(worker);
__set_current_state(TASK_IDLE);
raw_spin_unlock_irq(&pool->lock);
schedule();
goto woke_up;
}
导致worker thread进入sleep状态有三个条件:(a)电源管理模块没有请求冻结该worker thread。(b)该thread没有被其他模块请求停掉。(c)work list为空,也就是说没有work要处理。
下面看一下任务是怎么被执行的:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
#ifdef CONFIG_RT_MUTEXES
lockdep_assert(!tsk->sched_rt_mutex);
#endif
if (!task_is_running(tsk))
sched_submit_work(tsk);
__schedule_loop(SM_NONE);
sched_update_worker(tsk);
}
EXPORT_SYMBOL(schedule);
schedule() 负责实现任务调度。它的主要功能包括:
- 上下文切换(Context Switching):决定当前任务是否需要被切换,以及应该切换到哪个任务。
- 任务调度(Task Scheduling):根据任务的优先级、状态等信息,选择下一个要执行的任务。
- 任务提交(Task Submission):如果任务不在运行,可能会将任务提交给调度器,等待调度。
- 状态更新:更新当前任务或工作线程的状态,确保调度器能够正确跟踪任务。
这里说一下,带延时功能的等待队列,其实原理很简单。include/linux/workqueue.h
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
就是在普通的work_struct 上增加了一个内核定时器,先注册内核定时器,等定时器时间到,定时任务触发后,再在定时器任务里面添加work到keventd_wq工作队列中。
注:延时工作队列,只能加入到keventd_wq的工作队列之中。
include/linux/workqueue.h
/**
* schedule_delayed_work - put work task in global workqueue after delay
* @dwork: job to be done
* @delay: number of jiffies to wait or 0 for immediate execution
*
* After waiting for a given time this puts a job in the kernel-global
* workqueue.
*/
int schedule_delayed_work(struct delayed_work *dwork,
unsigned long delay)
{
return queue_delayed_work(keventd_wq, dwork, delay); //延时任务挂到keventd_wq任务
}
/**
* queue_delayed_work - queue work on a workqueue after delay
* @wq: workqueue to use
* @dwork: delayable work to queue
* @delay: number of jiffies to wait before queueing
*
* Equivalent to queue_delayed_work_on() but tries to use the local CPU.
*/
static inline bool queue_delayed_work(struct workqueue_struct *wq,
struct delayed_work *dwork,
unsigned long delay)
{
return queue_delayed_work_on(WORK_CPU_UNBOUND, wq, dwork, delay);
}
kernel/workqueue.c
bool queue_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay)
{
struct work_struct *work = &dwork->work;
bool ret = false;
unsigned long flags;
/* read the comment in __queue_work() */
local_irq_save(flags);
if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {
__queue_delayed_work(cpu, wq, dwork, delay);
ret = true;
}
local_irq_restore(flags);
return ret;
}
EXPORT_SYMBOL(queue_delayed_work_on);
static void __queue_delayed_work(int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay)
{
struct timer_list *timer = &dwork->timer;
struct work_struct *work = &dwork->work;
WARN_ON_ONCE(!wq);
WARN_ON_ONCE(timer->function != delayed_work_timer_fn);
WARN_ON_ONCE(timer_pending(timer));
WARN_ON_ONCE(!list_empty(&work->entry));
/*
* If @delay is 0, queue @dwork->work immediately. This is for
* both optimization and correctness. The earliest @timer can
* expire is on the closest next tick and delayed_work users depend
* on that there's no such delay when @delay is 0.
*/
if (!delay) {
__queue_work(cpu, wq, &dwork->work);
return;
}
dwork->wq = wq;
dwork->cpu = cpu;
timer->expires = jiffies + delay;
if (unlikely(cpu != WORK_CPU_UNBOUND))
add_timer_on(timer, cpu);
else
add_timer(timer);
}
//在定时器任务中,执行work挂入,cpu_workqueue_struct的worklist链表中
void delayed_work_timer_fn(struct timer_list *t)
{
struct delayed_work *dwork = from_timer(dwork, t, timer);
/* should have been called from irqsafe timer with irq already off */
__queue_work(dwork->cpu, dwork->wq, &dwork->work);
}
EXPORT_SYMBOL(delayed_work_timer_fn);
当然也可以销毁创建的工作队列,使用下面函数:include/linux/workqueue.h
extern void destroy_workqueue(struct workqueue_struct *wq);
六、举例
下面是一个简单的示例,展示了如何使用 Linux 工作队列来异步执行任务:
示例:使用工作队列
- 定义一个工作队列
- 创建一个工作项(work item)
- 初始化并排队工作项
- 定义工作函数来处理任务
- 清理工作项和工作队列
代码示例
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/workqueue.h>
#include <linux/delay.h>
// 定义一个工作队列
static struct workqueue_struct *my_wq;
// 定义一个工作项结构体
static struct work_struct my_work;
// 工作函数:执行工作队列中的任务
static void my_work_function(struct work_struct *work)
{
pr_info("工作队列任务正在执行...\n");
msleep(1000); // 模拟一个延迟操作
pr_info("工作队列任务执行完成\n");
}
// 模块初始化函数
static int __init workqueue_example_init(void)
{
pr_info("模块初始化,创建工作队列...\n");
// 创建工作队列
my_wq = create_workqueue("my_workqueue");
if (!my_wq) {
pr_err("创建工作队列失败\n");
return -ENOMEM;
}
// 初始化工作项
INIT_WORK(&my_work, my_work_function);
// 将工作项加入工作队列
queue_work(my_wq, &my_work);
return 0;
}
// 模块清理函数
static void __exit workqueue_example_exit(void)
{
pr_info("模块退出,销毁工作队列...\n");
// 等待工作队列中的所有任务完成
flush_workqueue(my_wq);
// 销毁工作队列
destroy_workqueue(my_wq);
}
module_init(workqueue_example_init);
module_exit(workqueue_example_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Your Name");
MODULE_DESCRIPTION("一个简单的工作队列示例");

















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









