




Linux文件系统1(基于6.1内核)---ext4框架
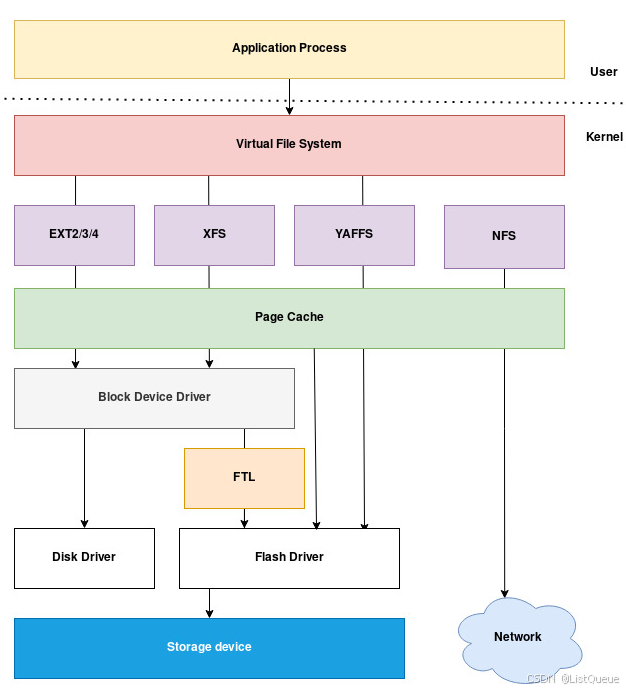
一、文件系统框架
从下图可以看到整个文件系统包含:
- 用户层:用户空间对文件的读写操作open/read/write等;
- VFS层:虚拟文件系统层,承上启下,为上下层提供接口;
- 文件系统层:可以存在很多类型的文件系统,VFS层的接口会调用到不同的文件系统层的接口;
- 缓存层:文件系统底下有缓存,Page Cache,加速性能;
- 块设备驱动层:对硬盘进行读写操作进行管理;
二、EXT4文件系统布局
linux ext4 文件系统,将磁盘分成一系列块组,磁盘的布局可以用如下图显示:
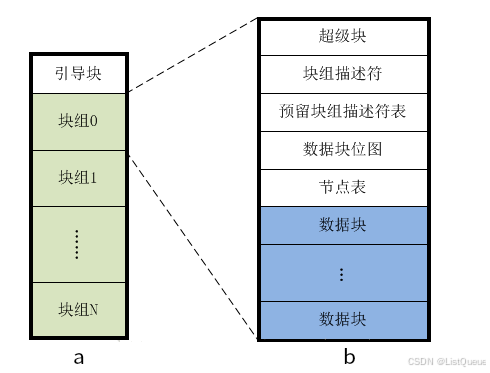
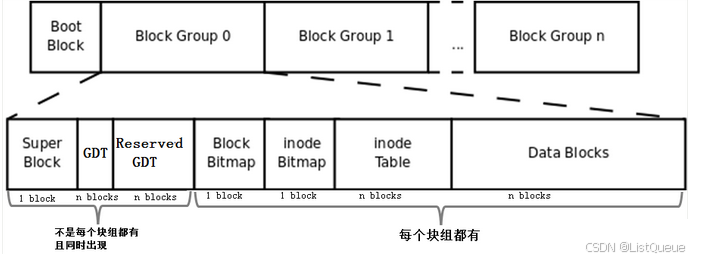
2.1、超级块(SuperBlock)
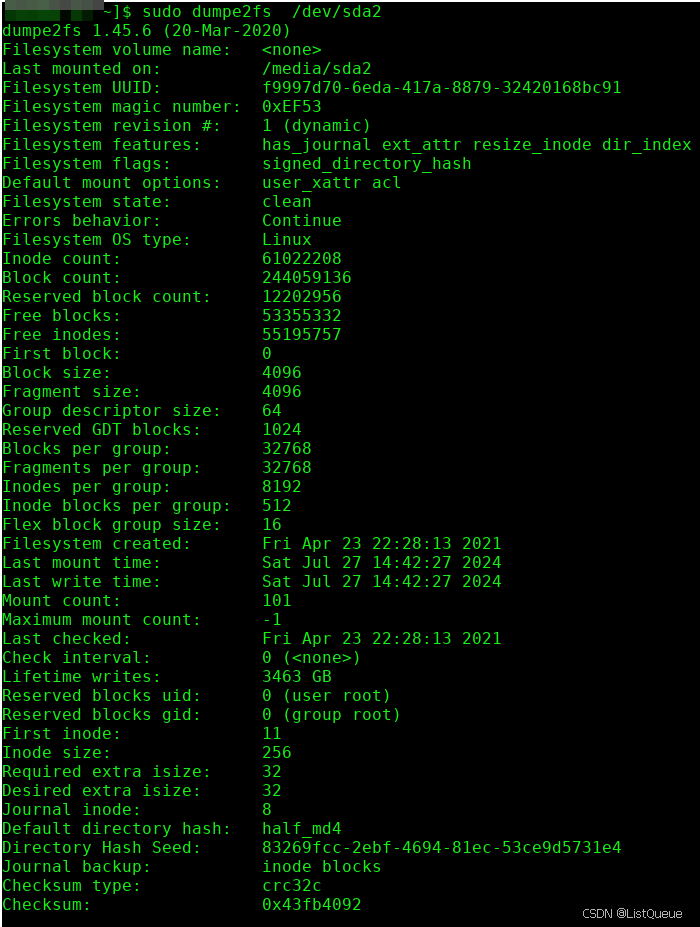
用于描述文件系统的配置信息:block的总数量和空闲数量、块组的数量、inode的数量等,存储这些。占用1kb的大小,只有块组号是3, 5 ,7的幂的块组(譬如说1,3,5,7,9,25,49…)才备份这个拷贝。通常情况下,只有主拷贝(第0块块组)的超级块信息被文件系统使用,其它拷贝只有在主拷贝被破坏的情况下才使用。
可以使用dumpe2fs来查看超级快的内容如下:
对应的描叙超级块信息的结构体:fs/ext4/ext4.h
/*
* Structure of the super block
*/
struct ext4_super_block {
/*00*/ __le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count_lo; /* Blocks count */
__le32 s_r_blocks_count_lo; /* Reserved blocks count */
__le32 s_free_blocks_count_lo; /* Free blocks count */
/*10*/ __le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_cluster_size; /* Allocation cluster size */
/*20*/ __le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_clusters_per_group; /* # Clusters per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
/*30*/ __le32 s_wtime; /* Write time */
__le16 s_mnt_count; /* Mount count */
__le16 s_max_mnt_count; /* Maximal mount count */
__le16 s_magic; /* Magic signature */
__le16 s_state; /* File system state */
__le16 s_errors; /* Behaviour when detecting errors */
__le16 s_minor_rev_level; /* minor revision level */
/*40*/ __le32 s_lastcheck; /* time of last check */
__le32 s_checkinterval; /* max. time between checks */
__le32 s_creator_os; /* OS */
__le32 s_rev_level; /* Revision level */
/*50*/ __le16 s_def_resuid; /* Default uid for reserved blocks */
__le16 s_def_resgid; /* Default gid for reserved blocks */
/*
* These fields are for EXT4_DYNAMIC_REV superblocks only.
*
* Note: the difference between the compatible feature set and
* the incompatible feature set is that if there is a bit set
* in the incompatible feature set that the kernel doesn't
* know about, it should refuse to mount the filesystem.
*
* e2fsck's requirements are more strict; if it doesn't know
* about a feature in either the compatible or incompatible
* feature set, it must abort and not try to meddle with
* things it doesn't understand...
*/
__le32 s_first_ino; /* First non-reserved inode */
__le16 s_inode_size; /* size of inode structure */
__le16 s_block_group_nr; /* block group # of this superblock */
__le32 s_feature_compat; /* compatible feature set */
/*60*/ __le32 s_feature_incompat; /* incompatible feature set */
__le32 s_feature_ro_compat; /* readonly-compatible feature set */
/*68*/ __u8 s_uuid[16]; /* 128-bit uuid for volume */
/*78*/ char s_volume_name[EXT4_LABEL_MAX]; /* volume name */
/*88*/ char s_last_mounted[64] __nonstring; /* directory where last mounted */
/*C8*/ __le32 s_algorithm_usage_bitmap; /* For compression */
/*
* Performance hints. Directory preallocation should only
* happen if the EXT4_FEATURE_COMPAT_DIR_PREALLOC flag is on.
*/
__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/
__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */
__le16 s_reserved_gdt_blocks; /* Per group desc for online growth */
/*
* Journaling support valid if EXT4_FEATURE_COMPAT_HAS_JOURNAL set.
*/
/*D0*/ __u8 s_journal_uuid[16]; /* uuid of journal superblock */
/*E0*/ __le32 s_journal_inum; /* inode number of journal file */
__le32 s_journal_dev; /* device number of journal file */
__le32 s_last_orphan; /* start of list of inodes to delete */
__le32 s_hash_seed[4]; /* HTREE hash seed */
__u8 s_def_hash_version; /* Default hash version to use */
__u8 s_jnl_backup_type;
__le16 s_desc_size; /* size of group descriptor */
/*100*/ __le32 s_default_mount_opts;
__le32 s_first_meta_bg; /* First metablock block group */
__le32 s_mkfs_time; /* When the filesystem was created */
__le32 s_jnl_blocks[17]; /* Backup of the journal inode */
/* 64bit support valid if EXT4_FEATURE_INCOMPAT_64BIT */
/*150*/ __le32 s_blocks_count_hi; /* Blocks count */
__le32 s_r_blocks_count_hi; /* Reserved blocks count */
__le32 s_free_blocks_count_hi; /* Free blocks count */
__le16 s_min_extra_isize; /* All inodes have at least # bytes */
__le16 s_want_extra_isize; /* New inodes should reserve # bytes */
__le32 s_flags; /* Miscellaneous flags */
__le16 s_raid_stride; /* RAID stride */
__le16 s_mmp_update_interval; /* # seconds to wait in MMP checking */
__le64 s_mmp_block; /* Block for multi-mount protection */
__le32 s_raid_stripe_width; /* blocks on all data disks (N*stride)*/
__u8 s_log_groups_per_flex; /* FLEX_BG group size */
__u8 s_checksum_type; /* metadata checksum algorithm used */
__u8 s_encryption_level; /* versioning level for encryption */
__u8 s_reserved_pad; /* Padding to next 32bits */
__le64 s_kbytes_written; /* nr of lifetime kilobytes written */
__le32 s_snapshot_inum; /* Inode number of active snapshot */
__le32 s_snapshot_id; /* sequential ID of active snapshot */
__le64 s_snapshot_r_blocks_count; /* reserved blocks for active
snapshot's future use */
__le32 s_snapshot_list; /* inode number of the head of the
on-disk snapshot list */
#define EXT4_S_ERR_START offsetof(struct ext4_super_block, s_error_count)
__le32 s_error_count; /* number of fs errors */
__le32 s_first_error_time; /* first time an error happened */
__le32 s_first_error_ino; /* inode involved in first error */
__le64 s_first_error_block; /* block involved of first error */
__u8 s_first_error_func[32] __nonstring; /* function where the error happened */
__le32 s_first_error_line; /* line number where error happened */
__le32 s_last_error_time; /* most recent time of an error */
__le32 s_last_error_ino; /* inode involved in last error */
__le32 s_last_error_line; /* line number where error happened */
__le64 s_last_error_block; /* block involved of last error */
__u8 s_last_error_func[32] __nonstring; /* function where the error happened */
#define EXT4_S_ERR_END offsetof(struct ext4_super_block, s_mount_opts)
__u8 s_mount_opts[64];
__le32 s_usr_quota_inum; /* inode for tracking user quota */
__le32 s_grp_quota_inum; /* inode for tracking group quota */
__le32 s_overhead_clusters; /* overhead blocks/clusters in fs */
__le32 s_backup_bgs[2]; /* groups with sparse_super2 SBs */
__u8 s_encrypt_algos[4]; /* Encryption algorithms in use */
__u8 s_encrypt_pw_salt[16]; /* Salt used for string2key algorithm */
__le32 s_lpf_ino; /* Location of the lost+found inode */
__le32 s_prj_quota_inum; /* inode for tracking project quota */
__le32 s_checksum_seed; /* crc32c(uuid) if csum_seed set */
__u8 s_wtime_hi;
__u8 s_mtime_hi;
__u8 s_mkfs_time_hi;
__u8 s_lastcheck_hi;
__u8 s_first_error_time_hi;
__u8 s_last_error_time_hi;
__u8 s_first_error_errcode;
__u8 s_last_error_errcode;
__le16 s_encoding; /* Filename charset encoding */
__le16 s_encoding_flags; /* Filename charset encoding flags */
__le32 s_orphan_file_inum; /* Inode for tracking orphan inodes */
__le32 s_reserved[94]; /* Padding to the end of the block */
__le32 s_checksum; /* crc32c(superblock) */
};
2.2、块组描述符(GDT)
块组描叙符用保存开组的信息,其占用一个或者多个数据块,具体取决于文件系统的大小,
它主要包含块位图,inode位图和inode表位置,当前空闲块数,inode数以及使用的目录数:
fs/ext4/ext4.h
/*
* Structure of a blocks group descriptor
*/
struct ext4_group_desc
{
__le32 bg_block_bitmap_lo; /* Blocks bitmap block */
__le32 bg_inode_bitmap_lo; /* Inodes bitmap block */
__le32 bg_inode_table_lo; /* Inodes table block */
__le16 bg_free_blocks_count_lo;/* Free blocks count */
__le16 bg_free_inodes_count_lo;/* Free inodes count */
__le16 bg_used_dirs_count_lo; /* Directories count */
__le16 bg_flags; /* EXT4_BG_flags (INODE_UNINIT, etc) */
__le32 bg_exclude_bitmap_lo; /* Exclude bitmap for snapshots */
__le16 bg_block_bitmap_csum_lo;/* crc32c(s_uuid+grp_num+bbitmap) LE */
__le16 bg_inode_bitmap_csum_lo;/* crc32c(s_uuid+grp_num+ibitmap) LE */
__le16 bg_itable_unused_lo; /* Unused inodes count */
__le16 bg_checksum; /* crc16(sb_uuid+group+desc) */
__le32 bg_block_bitmap_hi; /* Blocks bitmap block MSB */
__le32 bg_inode_bitmap_hi; /* Inodes bitmap block MSB */
__le32 bg_inode_table_hi; /* Inodes table block MSB */
__le16 bg_free_blocks_count_hi;/* Free blocks count MSB */
__le16 bg_free_inodes_count_hi;/* Free inodes count MSB */
__le16 bg_used_dirs_count_hi; /* Directories count MSB */
__le16 bg_itable_unused_hi; /* Unused inodes count MSB */
__le32 bg_exclude_bitmap_hi; /* Exclude bitmap block MSB */
__le16 bg_block_bitmap_csum_hi;/* crc32c(s_uuid+grp_num+bbitmap) BE */
__le16 bg_inode_bitmap_csum_hi;/* crc32c(s_uuid+grp_num+ibitmap) BE */
__u32 bg_reserved;
};
2.3、数据块位图(Block Bitmap)
块位图用于描述该块组所管理的块的分配状态。如果某个块对应的位未置位,那么代表该块未分配,
可以用于存储数据;否则,代表该块已经用于存储数据或者该块不能够使用(譬如该块物理上不存在)。由
于块位图仅占一个块,因此这也就决定了块组的大小;
2.4、inode位图(Inode Bitmap)
Inode位图用于描述该块组所管理的inode的分配状态。我们知道inode是用于描述文件的元数据,每个inode对应文件系统中唯一的一个号,如果inode位图中相应位置位,那么代表该inode已经分配出去,否则可以使用;
Inode位图是一个位数组,每一位(bit)代表一个Inode的状态。位图中的每一位可以有两种状态:
- 0:表示该Inode是空闲的,即未分配给一个文件或目录。
- 1:表示该Inode已被分配给一个文件或目录。
Inode位图在文件系统管理中扮演着重要角色:
- 文件创建:当创建一个新文件或目录时,文件系统会在Inode位图中查找一个空闲位(值为0的位),然后将其标记为已分配(将位设置为1),并将新文件或目录的元数据写入对应的Inode中。
- 文件删除:当删除一个文件或目录时,文件系统会将其Inode标记为空闲(将Inode位图中对应的位设置为0),并将Inode本身的内容(元数据)清除或标记为无效。
Inode位图的存储位置
Inode位图存储在文件系统的超级块(Superblock)中指定的位置。超级块包含了文件系统的整体信息和元数据结构的地址,包括Inode位图的位置。
查看Inode位图
在正常情况下,用户不会直接查看或修改Inode位图,因为这些操作涉及底层的文件系统结构和数据,通常是通过文件系统驱动程序和内核代码来处理的。不过,可以使用一些工具(如dumpe2fs)来查看文件系统的详细信息,包括Inode位图的信息。
例如,使用dumpe2fs命令查看EXT4文件系统的详细信息:

2.5、节点表(Inode Table)
为了找到与一个文件相关的信息,必须遍历目录文件找到与文件相关的目录项,然后加载inode找到该文件的元数据。inode存储了inode号、文件属性元数据、指向文件占用的block的指针,每一个inode占用128字节或256字节。举例:每一个家庭都要向派出所登记户口信息,通过户口本可以知道家庭住址,而每个镇或街道的派出所将本镇或本街道的所有户口整合在一起,要查找某一户地址时,在派出所就能快速查找到。inode table就是这里的派出所。其中inode结构体如下:

fs/ext4/ext4.h
/*
* Structure of an inode on the disk
*/
struct ext4_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
union {
struct {
__le32 l_i_version;
} linux1;
struct {
__u32 h_i_translator;
} hurd1;
struct {
__u32 m_i_reserved1;
} masix1;
} osd1; /* OS dependent 1 */
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
__le32 i_obso_faddr; /* Obsoleted fragment address */
union {
struct {
__le16 l_i_blocks_high; /* were l_i_reserved1 */
__le16 l_i_file_acl_high;
__le16 l_i_uid_high; /* these 2 fields */
__le16 l_i_gid_high; /* were reserved2[0] */
__le16 l_i_checksum_lo;/* crc32c(uuid+inum+inode) LE */
__le16 l_i_reserved;
} linux2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__u16 h_i_mode_high;
__u16 h_i_uid_high;
__u16 h_i_gid_high;
__u32 h_i_author;
} hurd2;
struct {
__le16 h_i_reserved1; /* Obsoleted fragment number/size which are removed in ext4 */
__le16 m_i_file_acl_high;
__u32 m_i_reserved2[2];
} masix2;
} osd2; /* OS dependent 2 */
__le16 i_extra_isize;
__le16 i_checksum_hi; /* crc32c(uuid+inum+inode) BE */
__le32 i_ctime_extra; /* extra Change time (nsec << 2 | epoch) */
__le32 i_mtime_extra; /* extra Modification time(nsec << 2 | epoch) */
__le32 i_atime_extra; /* extra Access time (nsec << 2 | epoch) */
__le32 i_crtime; /* File Creation time */
__le32 i_crtime_extra; /* extra FileCreationtime (nsec << 2 | epoch) */
__le32 i_version_hi; /* high 32 bits for 64-bit version */
__le32 i_projid; /* Project ID */
};
三、EXT4文件系统总结
Ext4(第四代扩展文件系统,Extended File System 4)是 Linux 系统中广泛使用的文件系统之一,它是 ext3 文件系统的继任者,并引入了一些增强功能和性能优化。Ext4 文件系统是基于块的文件系统,结构上做了多项改进,以提高存储效率和性能。
Ext4 文件系统的架构由多个组件和数据结构组成,主要包括以下部分:
- 超级块(Superblock)
- 块组(Block Groups)
- inode 表(Inode Table)
- 数据块(Data Blocks)
- 目录项(Directory Entries)
- 位图(Bitmap)
- 日志(Journaling)
这些组件共同工作,提供文件的存储和管理功能。
超级块(Superblock)
超级块是文件系统的核心数据结构,包含了文件系统的元数据信息。它存储了文件系统的整体信息,包括:
- 文件系统的总大小
- 文件系统的块大小
- 数据块的数量
- 空闲数据块数量
- 空闲 inode 数量
- 文件系统的状态(例如,是否启用日志)
- 文件系统的版本信息
在文件系统挂载时,超级块会被加载到内存中,以便操作系统能够访问和管理文件系统。
块组(Block Groups)
Ext4 文件系统将磁盘分为多个块组,每个块组是一个逻辑划分单元。每个块组内部包含数据块、inode 表、位图等。块组的设计可以提高文件系统的性能,尤其是在处理大文件时。
每个块组包括以下几个部分:
- 数据块:用于存储文件的数据。
- inode 表:存储该块组内所有文件和目录的元数据。
- 位图:分别管理 inode 位图和数据块位图,记录哪些 inode 和数据块是已使用的,哪些是空闲的。
- 超级块副本:用于在超级块损坏时恢复文件系统。
块组的数量和大小会影响文件系统的效率和空间利用率,Ext4 通过优化块组的布局来提升性能。
inode 表(Inode Table)
每个文件或目录都对应一个 inode,inode 存储了文件的元数据(例如文件大小、权限、创建时间、最后访问时间、数据块指针等)。inode 表存储了该块组内所有 inode 的集合。文件系统在创建文件时会分配一个 inode,在删除文件时释放该 inode。
每个 inode 通常包含以下内容:
- 文件类型(普通文件、目录、符号链接等)
- 文件权限(读取、写入、执行权限)
- 文件拥有者(用户和组)
- 文件的创建、修改和访问时间
- 文件数据块指针:指向存储文件内容的物理块。
在 Ext4 中,每个 inode 的大小通常为 128 或 256 字节(取决于文件系统的配置),每个块组会有一个独立的 inode 表。
数据块(Data Blocks)
数据块是文件系统用来存储实际文件内容的地方。文件系统将数据划分为固定大小的块,通常为 4KB。文件内容会分散存储在数据块中,inode 中的指针指向这些数据块。
在 Ext4 中,数据块可以是:
- 直接块(Direct Blocks):直接指向文件数据的块。
- 间接块(Indirect Blocks):当文件大小超出直接块的存储范围时,inode 指向间接块,间接块可以包含更多的块指针。
- 单级间接块
- 双级间接块
- 三级间接块
通过这种方式,Ext4 可以支持非常大的文件。
目录项(Directory Entries)
Ext4 中的目录是一个特殊的文件,它包含文件名和相应的 inode 索引。目录项通过 inode 指向实际的文件内容或子目录。目录的结构通常如下:
[文件名1, inode1]
[文件名2, inode2]
[文件名3, inode3]
...
每个目录项都关联一个 inode,操作系统通过 inode 来查找文件的元数据和数据块。
位图(Bitmap)
位图是管理文件系统中 inode 和数据块是否被分配的结构。Ext4 中有两个主要的位图:
- inode 位图:记录文件系统中的 inode 是否被使用。每个 inode 对应位图中的一个比特位,
1表示该 inode 已分配,0表示该 inode 空闲。 - 块位图:记录文件系统中的数据块是否被使用。每个数据块对应位图中的一个比特位,
1表示该数据块已分配,0表示该数据块空闲。
位图有助于高效地管理磁盘空间,确保文件系统内存占用最小,避免碎片化。
日志(Journaling)
Ext4 是一个支持日志的文件系统,这意味着所有的元数据操作(例如 inode 分配、数据块分配)都会被记录到一个特殊的区域(称为日志区域)。如果文件系统崩溃,系统可以通过日志来恢复文件系统的完整性,减少数据丢失的风险。
Ext4 支持两种日志模式:
- 写前日志(Write-Ahead Logging, WAL):确保在写入磁盘之前,所有的更改操作首先被记录到日志中。
- 延迟分配(Delayed Allocation):文件的数据块可能不会立刻分配,而是延迟到真正写入时,这样可以有效减少碎片。
Ext4 相较于 Ext3 的优势
- 更大的文件和文件系统支持:Ext4 支持更大的文件和文件系统。例如,Ext3 的文件系统最大支持 16TB,而 Ext4 最大支持 1EB(Exabyte)。
- 更高效的空间管理:通过块组的优化、延迟分配等技术,Ext4 可以更高效地管理磁盘空间,减少磁盘碎片。
- 更快的文件系统检查:Ext4 引入了新的检查工具(如
e2fsck),可以显著减少文件系统检查的时间。 - 日志性能优化:Ext4 在日志写入方面进行了优化,提升了文件系统的性能,尤其在高负载下。

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









