




Linux文件系统2(基于6.1内核)---VFS读写流程
一、文件系统框架:
从文件系统一种我们了解了linux文件系统的框架,这里我们首先再通过下面简洁的流程图
来展示linux文件系统文件读写的大框架:
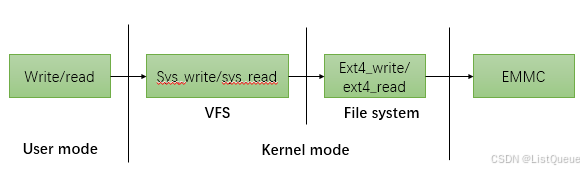
从上图中可以看出linux文件系统的读写通过调用虚拟文件系统(VFS)的对应接口,从而
调用到实际文件系统的读写接口,来进行emmc的操作,这样可以实现多文件系统兼容,如android
中的boot/system分区是ext4的格式,但cache/userdata我们可以配置为f2fs的文件系统格式,但
VFS层的调用接口是不变的。对应的相关结构体直接的关系:
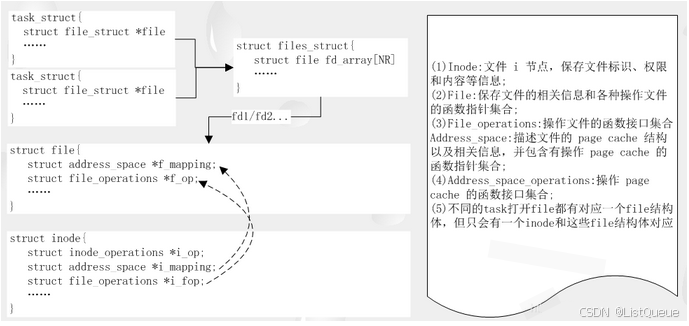
二、抓取调用trace方法
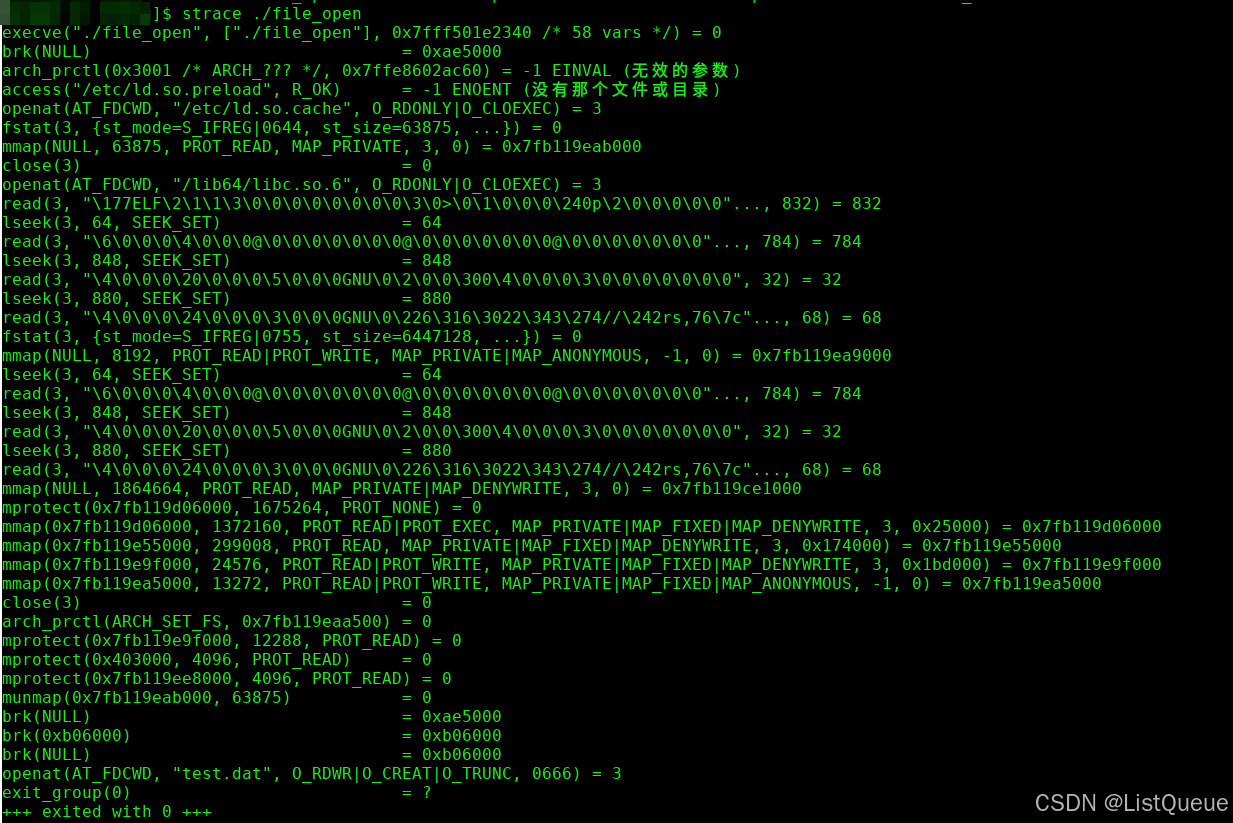
2.1、linux应用层操作方法
举例说明:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
int main(void)
{
int i,f;
FILE *fp;
char string[24];
fp = fopen("test.dat","w+");
return 0;
}
gcc file_open.c -o file_open
strace ./file_open 可以抓取到应用层调用的trace:
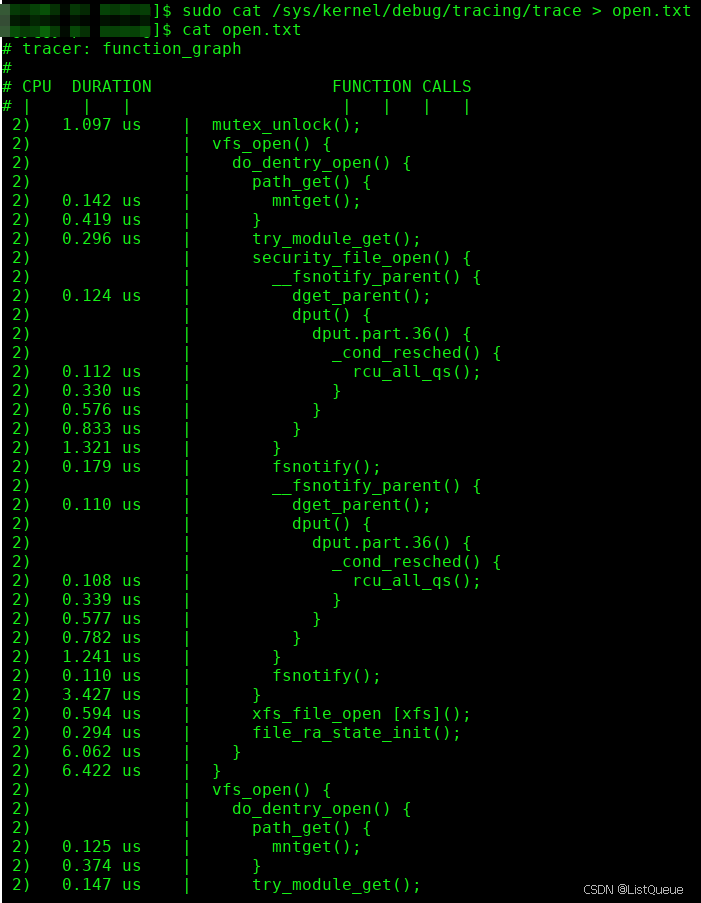
2.2、kernel ftrace抓取
举例说明:
# function.sh
#!/bin/bash
debugfs=/sys/kernel/debug
echo nop > $debugfs/tracing/current_tracer
echo 0 > $debugfs/tracing/tracing_on
echo $$ > $debugfs/tracing/set_ftrace_pid
echo function_graph > $debugfs/tracing/current_tracer
echo vfs_open > $debugfs/tracing/set_graph_function
# echo test_proc_write > $debugfs/tracing/set_graph_function
echo 1 > $debugfs/tracing/tracing_on
exec $@
./function.sh ./file_open
cat /sys/kernel/debug/tracing/trace > open.txt
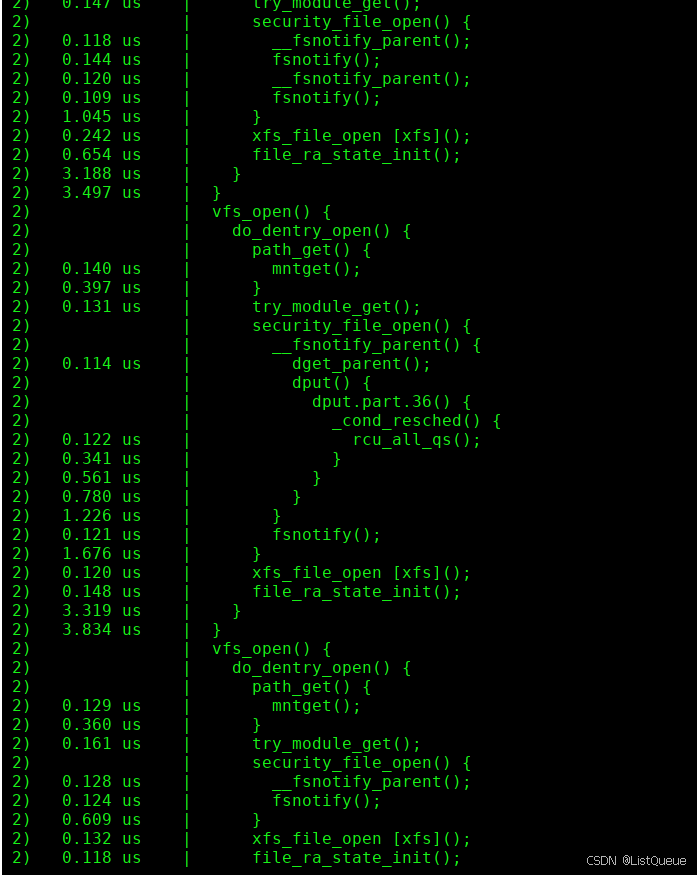
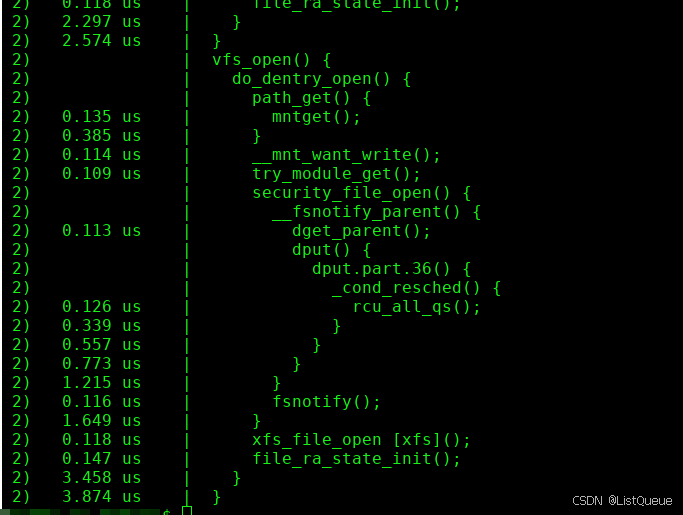
三、调用流程解析
3.1 open流程
+-------------------------+
| 用户调用 open() |
| (glibc 用户空间封装) |
+-------------------------+
|
v
+-------------------------+
| 系统调用进入内核 |
| 调用 sys_open() |
+-------------------------+
|
v
+-------------------------+
| 检查参数 |
| (路径和标志检查) |
+-------------------------+
|
v
+-------------------------+
| 调用 do_sys_open() |
| (核心打开逻辑) |
+-------------------------+
|
v
+-------------------------+
| 调用 do_sys_openat2() |
| (打开带路径的文件) |
+-------------------------+
|
v
+-------------------------+
| 调用 do_filp_open() |
| (打开文件对象) |
+-------------------------+
|
v
+-------------------------+
| 调用 path_openat() |
| (路径查找) |
+-------------------------+
|
v
+-------------------------+
| 调用 do_o_path() |
| (路径解析和文件查找) |
+-------------------------+
|
v
+-------------------------+
| 调用 vfs_open() |
| (虚拟文件系统层的打开) |
+-------------------------+
|
v
+-------------------------+
| 调用 do_dentry_open() |
| (dentry 操作) |
+-------------------------+
|
v
+-------------------------+
| 调用 ext4_file_open() |
| (ext4 文件系统的打开) |
+-------------------------+
|
v
+-------------------------+
| 返回文件描述符 |
+-------------------------+
详细步骤:
-
用户调用
open():- 应用程序通过标准库调用
open()系统调用,传递文件路径和打开标志。
- 应用程序通过标准库调用
-
进入内核,调用
sys_open():- 系统调用触发,进入内核层,调用
sys_open()处理。
- 系统调用触发,进入内核层,调用
-
检查参数:
- 内核检查传入的路径、打开标志(如
O_RDONLY、O_WRONLY等),确保它们有效且合法。
- 内核检查传入的路径、打开标志(如
-
调用
do_sys_open():sys_open()调用do_sys_open(),这是实际的文件打开处理函数。
-
调用
do_sys_openat2():do_sys_open()最终调用do_sys_openat2()以处理文件的具体打开操作。
-
调用
do_filp_open():do_filp_open()是一个封装函数,用来管理文件结构体(file)和文件描述符的分配。
-
调用
path_openat():- 在路径查找的过程中,调用
path_openat()来解析传入的路径,并进行必要的权限检查。
- 在路径查找的过程中,调用
-
调用
do_o_path():path_openat()调用do_o_path()来完成路径解析,确保文件的路径和权限都正确。
-
调用
vfs_open():do_o_path()调用vfs_open(),这是虚拟文件系统(VFS)层的文件打开接口,处理与文件系统相关的更多细节。
-
调用
do_dentry_open():vfs_open()调用do_dentry_open()来进行 dentry(目录项)的操作,这是文件路径查找的关键部分。
-
调用
ext4_file_open():- 如果文件在 ext4 文件系统上,最终会调用
ext4_file_open()来完成与具体文件系统的交互,处理文件的打开。
- 如果文件在 ext4 文件系统上,最终会调用
-
返回文件描述符:
- 成功打开文件后,内核返回一个文件描述符给用户空间,应用程序可以通过该文件描述符进行文件读写等操作。
代码描述:
fs/open.c
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_how how = build_open_how(flags, mode);
return do_sys_openat2(dfd, filename, &how);
}
static long do_sys_openat2(int dfd, const char __user *filename,
struct open_how *how)
{
struct open_flags op;
int fd = build_open_flags(how, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(how->flags);
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fd_install(fd, f);
}
}
putname(tmp);
return fd;
}
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd;
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname, NULL);
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
restore_nameidata();
return filp;
}
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
struct file *file;
int error;
file = alloc_empty_file(op->open_flag, current_cred());
if (IS_ERR(file))
return file;
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file);
} else if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
} else {
const char *s = path_init(nd, flags);
while (!(error = link_path_walk(s, nd)) &&
(s = open_last_lookups(nd, file, op)) != NULL)
;
if (!error)
error = do_open(nd, file, op);
terminate_walk(nd);
}
if (likely(!error)) {
if (likely(file->f_mode & FMODE_OPENED))
return file;
WARN_ON(1);
error = -EINVAL;
}
fput(file);
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
return ERR_PTR(error);
}
static int do_o_path(struct nameidata *nd, unsigned flags, struct file *file)
{
struct path path;
int error = path_lookupat(nd, flags, &path);
if (!error) {
audit_inode(nd->name, path.dentry, 0);
error = vfs_open(&path, file);
path_put(&path);
}
return error;
}
/**
* vfs_open - open the file at the given path
* @path: path to open
* @file: newly allocated file with f_flag initialized
*/
int vfs_open(const struct path *path, struct file *file)
{
file->f_path = *path;
return do_dentry_open(file, d_backing_inode(path->dentry), NULL);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *))
{
static const struct file_operations empty_fops = {};
int error;
path_get(&f->f_path);
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
f->f_wb_err = filemap_sample_wb_err(f->f_mapping);
f->f_sb_err = file_sample_sb_err(f);
if (unlikely(f->f_flags & O_PATH)) {
f->f_mode = FMODE_PATH | FMODE_OPENED;
f->f_op = &empty_fops;
return 0;
}
if ((f->f_mode & (FMODE_READ | FMODE_WRITE)) == FMODE_READ) {
i_readcount_inc(inode);
} else if (f->f_mode & FMODE_WRITE && !special_file(inode->i_mode)) {
error = get_write_access(inode);
if (unlikely(error))
goto cleanup_file;
error = __mnt_want_write(f->f_path.mnt);
if (unlikely(error)) {
put_write_access(inode);
goto cleanup_file;
}
f->f_mode |= FMODE_WRITER;
}
/* POSIX.1-2008/SUSv4 Section XSI 2.9.7 */
if (S_ISREG(inode->i_mode) || S_ISDIR(inode->i_mode))
f->f_mode |= FMODE_ATOMIC_POS;
f->f_op = fops_get(inode->i_fop);
if (WARN_ON(!f->f_op)) {
error = -ENODEV;
goto cleanup_all;
}
error = security_file_open(f);
if (error)
goto cleanup_all;
error = break_lease(file_inode(f), f->f_flags);
if (error)
goto cleanup_all;
/* normally all 3 are set; ->open() can clear them if needed */
f->f_mode |= FMODE_LSEEK | FMODE_PREAD | FMODE_PWRITE;
if (!open)
open = f->f_op->open;
if (open) {
error = open(inode, f);
if (error)
goto cleanup_all;
}
f->f_mode |= FMODE_OPENED;
if ((f->f_mode & FMODE_READ) &&
likely(f->f_op->read || f->f_op->read_iter))
f->f_mode |= FMODE_CAN_READ;
if ((f->f_mode & FMODE_WRITE) &&
likely(f->f_op->write || f->f_op->write_iter))
f->f_mode |= FMODE_CAN_WRITE;
if ((f->f_mode & FMODE_LSEEK) && !f->f_op->llseek)
f->f_mode &= ~FMODE_LSEEK;
if (f->f_mapping->a_ops && f->f_mapping->a_ops->direct_IO)
f->f_mode |= FMODE_CAN_ODIRECT;
f->f_flags &= ~(O_CREAT | O_EXCL | O_NOCTTY | O_TRUNC);
f->f_iocb_flags = iocb_flags(f);
file_ra_state_init(&f->f_ra, f->f_mapping->host->i_mapping);
if ((f->f_flags & O_DIRECT) && !(f->f_mode & FMODE_CAN_ODIRECT))
return -EINVAL;
/*
* XXX: Huge page cache doesn't support writing yet. Drop all page
* cache for this file before processing writes.
*/
if (f->f_mode & FMODE_WRITE) {
/*
* Paired with smp_mb() in collapse_file() to ensure nr_thps
* is up to date and the update to i_writecount by
* get_write_access() is visible. Ensures subsequent insertion
* of THPs into the page cache will fail.
*/
smp_mb();
if (filemap_nr_thps(inode->i_mapping)) {
struct address_space *mapping = inode->i_mapping;
filemap_invalidate_lock(inode->i_mapping);
/*
* unmap_mapping_range just need to be called once
* here, because the private pages is not need to be
* unmapped mapping (e.g. data segment of dynamic
* shared libraries here).
*/
unmap_mapping_range(mapping, 0, 0, 0);
truncate_inode_pages(mapping, 0);
filemap_invalidate_unlock(inode->i_mapping);
}
}
/*
* Once we return a file with FMODE_OPENED, __fput() will call
* fsnotify_close(), so we need fsnotify_open() here for symmetry.
*/
fsnotify_open(f);
return 0;
cleanup_all:
if (WARN_ON_ONCE(error > 0))
error = -EINVAL;
fops_put(f->f_op);
put_file_access(f);
cleanup_file:
path_put(&f->f_path);
f->f_path.mnt = NULL;
f->f_path.dentry = NULL;
f->f_inode = NULL;
return error;
}
/**
* path_get - get a reference to a path
* @path: path to get the reference to
*
* Given a path increment the reference count to the dentry and the vfsmount.
*/
void path_get(const struct path *path)
{
mntget(path->mnt);
dget(path->dentry);
}
EXPORT_SYMBOL(path_get);
...
VFS层经过层层调用后会调用到具体的文件系统的接口ext4_file_open
fs/ext4/file.c
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.iopoll = iocb_bio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open, //f->f_op->open
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = ext4_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
3.2 read流程
+-------------------------------+
| 用户调用 read() |
| (glibc 用户空间封装) |
+-------------------------------+
|
v
+-------------------------------+
| 系统调用进入内核 |
| 调用 ksys_read() |
+-------------------------------+
|
v
+-------------------------------+
| 进行参数检查 |
| (文件描述符、缓冲区、大小等) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 vfs_read() |
| (虚拟文件系统的读取接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 new_sync_read() |
| (同步读取接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 call_read_iter() |
| (文件读取的具体迭代接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 file->f_op->read_iter() |
| (文件操作结构体中的读接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 ext4_file_read_iter() |
| (ext4 文件系统的读取实现) |
+-------------------------------+
|
v
+-------------------------------+
| 返回读取的数据 |
+-------------------------------+
详细步骤:
-
用户调用
read():- 应用程序在用户空间调用
read()函数,这通常是通过标准 C 库(glibc)提供的接口。read()函数的参数包括文件描述符、缓冲区地址和读取字节数。
- 应用程序在用户空间调用
-
系统调用进入内核,调用
ksys_read():- 用户空间的
read()函数调用会触发一个系统调用,进入内核并调用ksys_read()函数,ksys_read()是 Linux 内核中实际处理文件读取的系统调用接口。
- 用户空间的
-
参数检查:
- 在
ksys_read()中,内核会首先检查传递的参数是否合法,如文件描述符是否有效、缓冲区指针是否有效、读取字节数是否合法等。如果参数有误,内核会返回错误。
- 在
-
调用
vfs_read():ksys_read()调用vfs_read(),这是虚拟文件系统(VFS)层的读取接口。vfs_read()的作用是将读取请求传递到具体的文件系统层,处理实际的文件读取。
-
调用
new_sync_read():- 在
vfs_read()中,通常会调用new_sync_read()来执行同步读取操作,确保读取过程在文件系统的锁保护下进行。new_sync_read()会检查文件是否是阻塞模式,并进行相应的同步操作。
- 在
-
调用
call_read_iter():new_sync_read()进一步调用call_read_iter(),该函数是一个通用的文件读取迭代接口,它会根据文件操作结构体(f_op)的read_iter方法来执行读取操作。
-
调用
file->f_op->read_iter():call_read_iter()会调用文件的操作结构体(f_op)中的read_iter()方法。f_op是文件对象(file)中指向文件操作的结构体,其中的read_iter()函数会被具体的文件系统实现所填充,执行文件的读取操作。
-
调用
ext4_file_read_iter():- 如果文件是通过
ext4文件系统打开的,file->f_op->read_iter会指向ext4_file_read_iter(),这是ext4文件系统实现的具体读取函数。ext4_file_read_iter()会完成实际的磁盘读取操作,读取文件的数据并将其拷贝到用户空间的缓冲区中。
- 如果文件是通过
-
返回读取的数据:
- 最终,
ext4_file_read_iter()将读取的数据返回给用户空间,操作系统会将数据拷贝到用户空间提供的缓冲区,并返回读取的字节数。如果发生错误,则返回相应的错误码。
- 最终,
代码描述:
fs/read_write.c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos, *ppos = file_ppos(f.file);
if (ppos) {
pos = *ppos;
ppos = &pos;
}
ret = vfs_read(f.file, buf, count, ppos);
if (ret >= 0 && ppos)
f.file->f_pos = pos;
fdput_pos(f);
}
return ret;
}
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_READ))
return -EINVAL;
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count);
if (ret)
return ret;
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
if (file->f_op->read)
ret = file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
ret = new_sync_read(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
return ret;
}
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = (ppos ? *ppos : 0);
iov_iter_ubuf(&iter, ITER_DEST, buf, len);
ret = call_read_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ppos)
*ppos = kiocb.ki_pos;
return ret;
}
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->read_iter(kio, iter);
}
...
VFS层经过层层调用后会调用到具体的文件系统的接口ext4_file_read_iter
fs/ext4/file.c
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.iopoll = iocb_bio_iopoll,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = ext4_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
struct inode *inode = file_inode(iocb->ki_filp);
if (unlikely(ext4_forced_shutdown(inode->i_sb)))
return -EIO;
if (!iov_iter_count(to))
return 0; /* skip atime */
#ifdef CONFIG_FS_DAX
if (IS_DAX(inode))
return ext4_dax_read_iter(iocb, to);
#endif
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_read_iter(iocb, to);
return generic_file_read_iter(iocb, to);
}
3.3 write流程
+-------------------------------+
| 用户调用 write() |
| (glibc 用户空间封装) |
+-------------------------------+
|
v
+-------------------------------+
| 系统调用进入内核 |
| 调用 ksys_write() |
+-------------------------------+
|
v
+-------------------------------+
| 进行参数检查 |
| (文件描述符、缓冲区、字节数等) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 vfs_write() |
| (虚拟文件系统的写入接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 new_sync_write() |
| (同步写入接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 call_write_iter() |
| (文件写入的具体迭代接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 file->f_op->write_iter() |
| (文件操作结构体中的写接口) |
+-------------------------------+
|
v
+-------------------------------+
| 调用 ext4_file_write_iter() |
| (ext4 文件系统的写入实现) |
+-------------------------------+
|
v
+-------------------------------+
| 返回写入的字节数或错误 |
+-------------------------------+
详细步骤:
-
用户调用
write():- 应用程序在用户空间调用
write()函数,write()函数的参数包括文件描述符、缓冲区地址和写入字节数。它是通过标准 C 库(glibc)提供的接口。
- 应用程序在用户空间调用
-
系统调用进入内核,调用
ksys_write():- 用户空间的
write()函数会触发系统调用,进入内核并调用ksys_write()函数。ksys_write()是 Linux 内核中实际处理文件写入的系统调用接口。
- 用户空间的
-
参数检查:
- 在
ksys_write()中,内核首先会对传递的参数进行合法性检查,如文件描述符、缓冲区指针是否有效、写入字节数是否合理等。如果参数无效,内核会返回错误。
- 在
-
调用
vfs_write():ksys_write()调用vfs_write(),这是虚拟文件系统(VFS)层的写入接口。vfs_write()会根据文件描述符将写入请求转发到具体的文件系统层,执行实际的写操作。
-
调用
new_sync_write():- 在
vfs_write()中,通常会调用new_sync_write()来执行同步写入操作。new_sync_write()会确保写入操作在文件系统的锁保护下进行,并且保证数据一致性。
- 在
-
调用
call_write_iter():new_sync_write()进一步调用call_write_iter(),这是一个通用的文件写入迭代接口。该函数根据文件操作结构体(f_op)的write_iter方法来执行具体的写入操作。
-
调用
file->f_op->write_iter():call_write_iter()会调用文件操作结构体(f_op)中的write_iter()方法。f_op是文件对象(file)中指向文件操作的结构体,其中的write_iter()方法会被具体的文件系统实现所填充,执行文件的写入操作。
-
调用
ext4_file_write_iter():- 如果文件是通过
ext4文件系统打开的,file->f_op->write_iter会指向ext4_file_write_iter(),这是ext4文件系统实现的具体写入函数。ext4_file_write_iter()会完成实际的磁盘写入操作,将数据写入磁盘。
- 如果文件是通过
-
返回写入的字节数或错误:
- 最终,
ext4_file_write_iter()会返回写入的字节数。如果发生错误,则返回相应的错误码。内核将这些结果返回给用户空间,write()系统调用也会返回最终的结果。
- 最终,
代码描述:
fs/read_write.c
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos, *ppos = file_ppos(f.file);
if (ppos) {
pos = *ppos;
ppos = &pos;
}
ret = vfs_write(f.file, buf, count, ppos);
if (ret >= 0 && ppos)
f.file->f_pos = pos;
fdput_pos(f);
}
return ret;
}
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
if (unlikely(!access_ok(buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (ret)
return ret;
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
file_start_write(file);
if (file->f_op->write)
ret = file->f_op->write(file, buf, count, pos);
else if (file->f_op->write_iter)
ret = new_sync_write(file, buf, count, pos);
else
ret = -EINVAL;
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
return ret;
}
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = (ppos ? *ppos : 0);
iov_iter_ubuf(&iter, ITER_SOURCE, (void __user *)buf, len);
ret = call_write_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0 && ppos)
*ppos = kiocb.ki_pos;
return ret;
}
static inline ssize_t call_write_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->write_iter(kio, iter);
}
...
VFS层经过层层调用后会调用到具体的文件系统的接口ext4_file_write_iter
fs/ext4/file.c
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct inode *inode = file_inode(iocb->ki_filp);
if (unlikely(ext4_forced_shutdown(inode->i_sb)))
return -EIO;
#ifdef CONFIG_FS_DAX
if (IS_DAX(inode))
return ext4_dax_write_iter(iocb, from);
#endif
if (iocb->ki_flags & IOCB_DIRECT)
return ext4_dio_write_iter(iocb, from);
else
return ext4_buffered_write_iter(iocb, from);
}
后面将详细介绍ext4文件系统的open/read/write的流程。


















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









