




Linux内存管理8(基于6.1内核)---内存初始化
一、Linux启动过程中的内存初始化
初始化过程中,还必须建立内存管理的数据结构,以及很多事务。 因为内核在内存管理完全初始化之前就需要使用内存。 在系统启动过程期间, 使用了额外的简化悉尼股市的内存管理模块,然后在初始化完成后,将旧的模块丢弃掉。Linux内核的内存管理分三个阶段:
| 阶段 | 起点 | 终点 | 描述 |
|---|---|---|---|
| 第一阶段 | 系统启动 | bootmem或者memblock初始化完成 | 此阶段只能使用memblock_reserve函数分配内存, 早期内核中使用init_bootmem_done = 1标识此阶段结束 |
| 第二阶段 | bootmem或者memblock初始化完 | buddy完成前 | 引导内存分配器bootmem或者memblock接受内存的管理工作, 早期内核中使用mem_init_done = 1标记此阶段的结束 |
| 第三阶段 | buddy初始化完成 | 系统停止运行 | 可以用cache和buddy分配内存 |
系统启动过程中的内存管理
首先我们来看看start_kernel是如何初始化系统的,init/main.c
其代码很复杂, 我们只截取出其中与内存管理初始化相关的部分, 如下所示
asmlinkage __visible __init __no_sanitize_address __noreturn __no_stack_protector
void start_kernel(void)
{
/* 设置特定架构的信息
* 同时初始化memblock */
setup_arch(&command_line);
mm_init_cpumask(&init_mm);
setup_per_cpu_areas();
mm_core_init();
kmem_cache_init_late();
kmemleak_init();
setup_per_cpu_pageset();
/* Do the rest non-__init'ed, we're now alive */
arch_call_rest_init();
}
|
函数 |
功能 |
|
setup_arch |
是一个特定于体系结构的设置函数, 其中一项任务是负责初始化自举分配器 |
|
mm_init_cpumask |
初始化CPU屏蔽字 |
|
setup_per_cpu_areas |
函数给每个CPU分配内存,并拷贝.data.percpu段的数据. 为系统中的每个CPU的per_cpu变量申请空间. |
|
mm_core_init |
建立了内核的内存分配器, |
|
kmem_cache_init_late |
在kmem_cache_init之后, 完善分配器的缓存机制, 当前3个可用的内核内存分配器slab, slob, slub都会定义此函数 |
二、第一阶段(启动过程中的内存管理)
内存管理是操作系统资源管理的重点, 但是在操作系统初始化的初期, 操作系统只是获取到了内存的基本信息, 但是内存管理的数据结构都没有建立, 而这些数据结构创建的过程本身就是一个内存分配的过程, 那么就出现一个问题。
还没有一个内存管理器去负责分配和回收内存, 而又不可能将所有的内存信息都静态创建并初始化, 那么我们怎么分配内存管理器所需要的内存呢? 这种问题的一般解决方法是, 先实现一个满足要求的但是可能效率不高的笨家伙(内存管理器), 用它来负责系统初始化初期的内存管理, 最重要的, 用它来初始化我们内存的数据结构, 直到我们真正的内存管理器被初始化完成并能投入使用, 我们将旧的内存管理器丢掉。
即因此在系统启动过程期间, 内核使用了一个额外的简化形式的内存管理模块早期的引导内存分配器(boot memory allocator–bootmem分配器)或者memblock, 用于在启动阶段早期分配内存, 而在系统初始化完成后, 该分配器被内核抛弃, 然后初始化了一套新的更加完善的内存分配器。
2.1 bootmem--->memblock
在启动过程期间, 尽管内存管理尚未初始化, 但是内核仍然需要分配内存以创建各种数据结构, 早期的内核中负责初始化阶段的内存分配器称为引导内存分配器(boot memory allocator–bootmem分配器), 在耳熟能详的伙伴系统建立前内存都是利用分配器来分配的,伙伴系统框架建立起来后,bootmem会过度到伙伴系统。 显然, 对该内存分配器的需求集中于简单性方面,而不是性能和通用性, 它仅用于初始化阶段。因此内核开发者决定实现一个最先适配(first-first)分配器用于在启动阶段管理内存, 这是可能想到的最简单的方式。
引导内存分配器(boot memory allocator–bootmem分配器)基于最先适配(first-first)分配器的原理(这儿是很多系统的内存分配所使用的原理), 使用一个位图来管理页, 以位图代替原来的空闲链表结构来表示存储空间, 位图的比特位的数目与系统中物理内存页面数目相同. 若位图中某一位是1, 则标识该页面已经被分配(已用页), 否则表示未被占有(未用页)。
在 Linux 6.x 中,bootmem 被 memblock 机制取代。memblock 是一个更加灵活且高效的机制,专门用于内核引导期间的物理内存管理。它的主要目标是在内核初始化的早期阶段管理物理内存区域,并为后续的内存分配器(如 page_alloc、slab)做好准备。memblock 不像 bootmem 那样通过固定的内存池来分配内存,而是通过动态管理物理内存块和区域来提供更加灵活的分配方式。
memblock 的关键特性包括:
- 区域管理:
memblock使用内存区域(zone)来管理内存,按照物理内存地址进行划分,支持动态地管理不同内存区域的分配。 - 延迟初始化:
memblock初始化通常在早期阶段完成,为后续内存分配器的初始化(如页分配器page_alloc)提供必要的信息。 - 不需要复杂的数据结构: 它只管理内存块(block),在内核启动时负责分配较小的内存区域,避免了复杂的内存管理机制。
memblock 的工作流程:
- 内存块初始化: 在内核引导的最初阶段,
memblock负责记录系统的内存布局,并将内存划分为不同的区域(比如memblock.memory和memblock.reserved)。 - 内存区域划分: 在启动过程中,内存被划分为多个区域,这些区域可以在后续阶段按需进行分配。
- 内存分配:
memblock负责管理这段内存的初步分配,以支持内核启动阶段需要的基本内存分配。
与 bootmem 的对比
- 灵活性:
memblock更加灵活,可以处理更加复杂的内存管理需求,不像bootmem那样简单且局限于初期内存分配。 - 延迟分配:
memblock支持更加延迟的内存分配,不会在系统启动初期就占用过多内存,这对于大型系统和多处理器系统尤为重要。 - 内存区域管理:
memblock更加注重物理内存的分区和动态管理,而bootmem更多地依赖于固定的内存池。
memblock 和早期内存管理的关系
在 Linux 6.x 内核中,memblock 并不仅仅是替代了 bootmem,它还与其他内存管理机制(如页表初始化、early pagetable)协同工作。具体而言:
early pagetable初始化: 在内核引导阶段,memblock用于管理物理内存区域,并配合早期页表(early page table)初始化,为虚拟内存管理和更复杂的内存分配提供必要支持。- 页分配器(
page_alloc)初始化:memblock的初始化为后续的页分配器初始化提供了物理内存区域的详细信息,确保内存的页级别分配能够正确进行。
2.2 memblock的初始化
前面我们的内核从start_kernel开始, 进入setup_arch(), 并完成了早期内存分配器的初始化和设置工作。arch/arm64/kernel/setup.c
void __init __no_sanitize_address setup_arch(char **cmdline_p)
{
...
/* 初始化memblock */
arm64_memblock_init( );
/* 分页机制初始化 */
paging_init();
/* 初始化内存 */
bootmem_init();
...
}
其中arm64_memblock_init就完成了arm64架构下的memblock的初始化。
三、第二阶段(初始化buddy内存管理)
在arm64架构下, 内核在start_kernel()->setup_arch()函数中依次完成了如下工作。
前面我们的内核从start_kernel开始, 进入setup_arch(), 并完成了早期内存分配器的初始化和设置工作。
void __init __no_sanitize_address setup_arch(char **cmdline_p)
{
...
/* 初始化memblock */
arm64_memblock_init( );
/* 分页机制初始化 */
paging_init();
/* 初始化内存 */
bootmem_init();
...
}
其中arm64_memblock_init就完成了arm64架构下的memblock的初始化。
而setup_arch则主要完成如下工作:
-
调用arm64_memblock_init来完成了memblock的初始化。
-
paging_init初始化内存的分页机制。
-
bootmem_init初始化内存管理。
3.1 初始化流程
以arm64架构来分析bootmem初始化内存结点和内存域的过程。
+----------------------------------+
| start_kernel |
| (内核启动入口) |
+----------------------------------+
|
v
+----------------------------------+
| setup_arch |
| (体系结构相关设置,获取物理信息) |
+----------------------------------+
|
v
+----------------------------------+
| paging_init |
| (初始化分页机制和页表信息) |
+----------------------------------+
|
v
+----------------------------------+
| bootmem_init |
| (初始化物理内存管理) |
+----------------------------------+
3.2 paging_init初始化分页机制
paging_init负责建立只能用于内核的页表, 用户空间是无法访问的. 这对管理普通应用程序和内核访问内存的方式,有深远的影响。因此在仔细考察其实现之前,很重要的一点是解释该函数的目的。
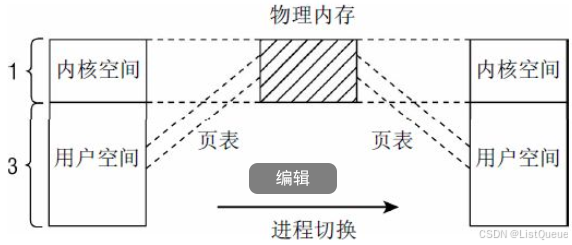
在x86_32系统上内核通常将总的4GB可用虚拟地址空间按3:1的比例划分给用户空间和内核空间, 虚拟地址空间的低端3GB。
用于用户状态应用程序, 而高端的1GB则专用于内核. 尽管在分配内核的虚拟地址空间时, 当前系统上下文是不相干的, 但每个进程都有自身特定的地址空间。
这些划分主要的动机如下所示:
-
在用户应用程序的执行切换到核心态时(例如在使用系统调用或发生周期性的时钟中断时),内核必须装载在一个可靠的环境中。因此有必要将地址空间的一部分分配给内核专用。
-
物理内存页则映射到内核地址空间的起始处,以便内核直接访问,而无需复杂的页表操作。
如果所有物理内存页都映射到用户空间进程能访问的地址空间中, 如果在系统上有几个应用程序在运行, 将导致严重的安全问题. 每个应用程序都能够读取和修改其他进程在物理内存中的内存区. 显然必须不惜任何代价防止这种情况出现.
虽然用于用户层进程的虚拟地址部分随进程切换而改变,但是内核部分总是相同的
3.3 虚拟地址空间
以32位系统为例,出于内存保护等一系列的考虑, 内核将整个进程的虚拟运行空间划分为内核虚拟运行空间和内核虚拟运行空间。
按3:1的比例划分地址空间, 只是约略反映了内核中的情况,内核地址空间作为内核的常驻虚拟地址空间, 自身又分为各个段。
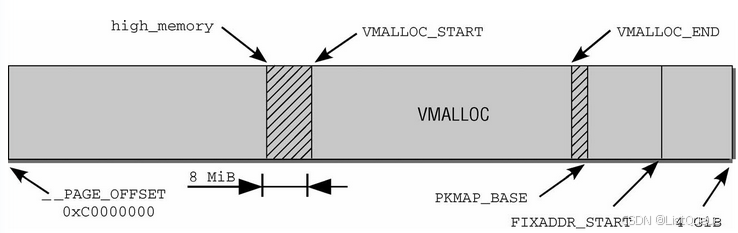
地址空间的第一段用于将系统的所有物理内存页映射到内核的虚拟地址空间中。由于内核地址空间从偏移量0xC0000000开始,即经常提到的3 GiB,每个虚拟地址x都对应于物理地址x—0xC0000000,因此这是一个简单的线性平移。
直接映射区域从0xC0000000到high_memory地址,high_memory准确的数值稍后讨论。这种方案有一问题。由于内核的虚拟地址空间只有1 GiB,最多只能映射1 GiB物理内存。IA-32系统(没有PAE)最大的内存配置可以达到4 GiB,引出的一个问题是,如何处理剩下的内存?
这里有个坏消息。如果物理内存超过896 MiB,则内核无法直接映射全部物理内存。该值甚至比此前提到的最大限制1 GiB还小,因为内核必须保留地址空间最后的128 MiB用于其他目的。将这128 MiB加上直接映射的896 MiB内存,则得到内核虚拟地址空间的总数为1 024 MiB = 1GiB。内核使用两个经常使用的缩写normal和highmem,来区分是否可以直接映射的页帧。
内核地址空间的最后128 MiB用于何种用途呢?如下:
1. 内核映射区域(Kernel Mapping Area)
- 内核映射区域通常是内核空间的一部分,用于映射物理内存到内核虚拟地址空间。这一部分内存允许内核直接访问所有的物理内存资源,特别是需要频繁访问的硬件资源或设备内存。
- 在一些操作系统(如Linux、Windows等)中,内核通过该区域对硬件进行直接操作,进行设备驱动、内存管理和系统调用等任务。
2. I/O 内存映射(I/O Memory Mapping)
- 这部分内存也常常用于 I/O 内存映射。这意味着操作系统可以通过映射到虚拟内存的方式,直接访问硬件设备的内存区域。例如,GPU、硬盘控制器、网络适配器等硬件设备可能通过这种方式与操作系统进行交互。
- I/O 内存区域的映射帮助操作系统高效地控制硬件设备,提高访问速度和减少延迟。
3. Page Table Management
- 在64位架构中,内核需要管理大量的页面表来映射虚拟内存到物理内存。最后128 MiB的内核地址空间可能用于存储这些页面表项,尤其是在大内存系统上,操作系统需要大量的内核空间来维护虚拟内存的映射。
- 一些操作系统(如Linux)使用这些区域来存储 页表 或其他内存管理结构,如页目录、页表项等。
4. CPU特定的系统区域
- 在某些硬件架构上(尤其是x86-64或ARM64等),最后128 MiB可能被预留给CPU特定的系统区域,比如控制寄存器、硬件中断向量、调度器等的使用空间。
- 例如,在x86架构中,内核地址空间的上部会预留一定的空间给 硬件异常处理、调度程序 或其他内核内部任务。
5. 保护区(Protection Area)
- 最后128 MiB也可以作为保护区,防止内核空间被用户程序恶意或无意间篡改。这一块区域可能会用于存储操作系统的关键数据结构,如 内核堆栈、内核调用栈等,用于提升系统的安全性。
- 这种保护机制有助于防止用户程序突破权限边界,直接干扰或攻击内核的工作。
6. 内核堆和栈区域(Kernel Heap & Stack)
- 一些操作系统在内核地址空间的最后部分划分出堆和栈区域,用于内核的内存分配和函数调用。与用户空间不同,内核的堆和栈是为内核任务(如进程调度、系统调用处理等)而专门设置的。
用户空间也被划分为几个段, 包括从高地址到低地址分别为 :
+-------------------------+
| 栈 (Stack) | ← 高地址
|-------------------------|
| 堆 (Heap) |
|-------------------------|
| 数据段 (Data) |
|-------------------------|
| BSS段 (BSS) |
|-------------------------|
| 代码段 (Text) | ← 低地址
+-------------------------+
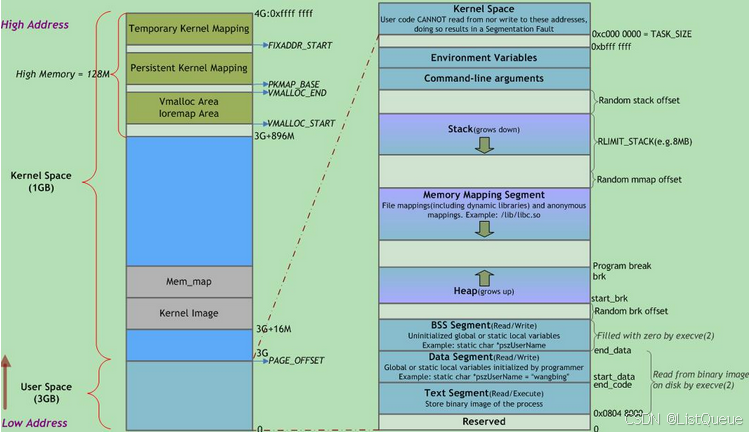
| 区域 | 存储内容 |
|---|---|
| 栈 | 局部变量, 函数参数, 返回地址等 |
| 堆 | 动态分配的内存 |
| BSS段 | 未初始化或初值为0的全局变量和静态局部变量 |
| 数据段 | 一初始化且初值非0的全局变量和静态局部变量 |
| 代码段 | 可执行代码, 字符串面值, 只读变量 |
3.4 bootmem_init初始化内存的基础数据结构
在paging_init之后, 系统的页帧已经建立起来, 然后通过bootmem_init中, 系统开始完成bootmem的初始化工作。
不同的体系结构bootmem_init的实现, 没有很大的区别, 但是在初始化的过程中, 其中的很多函数, 依据系统是NUMA还是UMA结构则有不同的定义。
bootmem_init函数的实现如下arch/arm64/mm/init.c
void __init bootmem_init(void)
{
unsigned long min, max;
min = PFN_UP(memblock_start_of_DRAM());
max = PFN_DOWN(memblock_end_of_DRAM());
early_memtest(min << PAGE_SHIFT, max << PAGE_SHIFT);
max_pfn = max_low_pfn = max;
min_low_pfn = min;
arch_numa_init();
/*
* must be done after arch_numa_init() which calls numa_init() to
* initialize node_online_map that gets used in hugetlb_cma_reserve()
* while allocating required CMA size across online nodes.
*/
#if defined(CONFIG_HUGETLB_PAGE) && defined(CONFIG_CMA)
arm64_hugetlb_cma_reserve();
#endif
kvm_hyp_reserve();
/*
* sparse_init() tries to allocate memory from memblock, so must be
* done after the fixed reservations
*/
sparse_init();
zone_sizes_init();
/*
* Reserve the CMA area after arm64_dma_phys_limit was initialised.
*/
dma_contiguous_reserve(arm64_dma_phys_limit);
/*
* request_standard_resources() depends on crashkernel's memory being
* reserved, so do it here.
*/
reserve_crashkernel();
memblock_dump_all();
}
3.5 build_all_zonelists初始化每个内存节点的zonelists
mm/mm_init.c
/*
* Set up kernel memory allocators
*/
void __init mm_core_init(void)
{
/* Initializations relying on SMP setup */
build_all_zonelists(NULL);
...
}
内核setup_arch的最后通过bootmem_init中完成了内存数据结构的初始化(包括内存结点pg_data_t, 内存管理域zone和页面信息page), 数据结构已经基本准备好了, 在后面为内存管理做得一个准备工作就是将所有节点的管理区都链入到zonelist中,便于后面内存分配工作的进行.
内存节点pg_data_t中将内存节点中的内存区域zone按照某种组织层次存储在一个zonelist中, 即pglist_data->node_zonelists成员信息。include/linux/mmzone.h
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
struct zone node_zones[MAX_NR_ZONES];
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
struct zonelist node_zonelists[MAX_ZONELISTS];
内核定义了内存的一个层次结构关系, 首先试图分配廉价的内存,如果失败,则根据访问速度和容量,逐渐尝试分配更昂贵的内存。
高端内存最廉价, 因为内核没有任何部分依赖于从该内存域分配的内存, 如果高端内存用尽, 对内核没有副作用, 所以优先分配高端内存。
普通内存域的情况有所不同, 许多内核数据结构必须保存在该内存域, 而不能放置到高端内存域, 因此如果普通内存域用尽, 那么内核会面临内存紧张的情况。
DMA内存域最昂贵,因为它用于外设和系统之间的数据传输。
举例来讲,如果内核指定想要分配高端内存域。它首先在当前结点的高端内存域寻找适当的空闲内存段,如果失败,则查看该结点的普通内存域,如果还失败,则试图在该结点的DMA内存域分配。如果在3个本地内存域都无法找到空闲内存,则查看其他结点。这种情况下,备选结点应该尽可能靠近主结点,以最小化访问非本地内存引起的性能损失。
四、内存初始化总结
4.1 start_kernel启动流程
start_kernel()
|---->page_address_init()
| 考虑支持高端内存
| 业务:初始化page_address_pool链表;
| 将page_address_maps数组元素按索引降序插入
| page_address_pool链表;
| 初始化page_address_htable数组.
|
|---->setup_arch(&command_line);
| 初始化特定体系结构的内容
|---->arm64_memblock_init( ); [参见memblock和bootmem]
| 初始化引导阶段的内存分配器memblock
|
|---->paging_init(); [参见分页机制初始化paging_init]
| 分页机制初始化
|
|---->bootmem_init(); [与build_all_zonelist共同完成内存数据结构的初始化]
| 初始化内存数据结构包括内存节点和内存域
|
|---->setup_per_cpu_areas();
| 为per-CPU变量分配空间
|
|---->mm_core_init---->build_all_zonelist() [bootmem_init初始化数据结构, 该函数初始化zonelists]
| 为系统中的zone建立后备zone的列表.
| 所有zone的后备列表都在
| pglist_data->node_zonelists[0]中;
|
| 期间也对per-CPU变量boot_pageset做了初始化.
|
|---->mm_core_init---->page_alloc_init()
|---->hotcpu_notifier(page_alloc_cpu_notifier, 0);
| 不考虑热插拔CPU
|
|
|---->vfs_caches_init_early()
|---->dcache_init_early()
| dentry_hashtable空间,d_hash_shift, h_hash_mask赋值;
| 同pidhash_init();
| 区别:
| 散列度变化了(13 - PAGE_SHIFT);
| 传入alloc_large_system_hash的最后参数值为0;
|
|---->inode_init_early()
| inode_hashtable空间,i_hash_shift, i_hash_mask赋值;
| 同pidhash_init();
| 区别:
| 散列度变化了(14 - PAGE_SHIFT);
| 传入alloc_large_system_hash的最后参数值为0;
|
4.2 体系结构相关的初始化工作setup_arch
setup_arch(char **cmdline_p)
|---->arm64_memblock_init( );
| 初始化引导阶段的内存分配器memblock
|
|
|---->paging_init();
| 分页机制初始化
|
|
|---->bootmem_init();
| 初始化内存数据结构包括内存节点和内存域
}
4.3 bootmem_init初始化内存的基础数据结构(结点pg_data, 内存域zone, 页面page)
bootmem_init(void)
|---->min = PFN_UP(memblock_start_of_DRAM());
|---->max = PFN_DOWN(memblock_end_of_DRAM());
|
|
|---->arm64_numa_init();
| 支持numa架构
|---->arm64_numa_init();
| 支持numa架构
|
|
|---->zone_sizes_init(min, max);
来初始化节点和管理区的一些数据项
|
|---->free_area_init_node
| 初始化内存节点
|
|
|---->free_area_init_core初始化zone
|
|
|---->memmap_init初始化page页面
|
|
|
|---->memblock_dump_all();
| 初始化完成, 显示memblock的保留的所有内存信息
4.4 build_all_zonelists初始化每个内存节点的zonelists
void build_all_zonelists(void)
|---->set_zonelist_order()
|---->current_zonelist_order = ZONELIST_ORDER_ZONE;
|
|---->__build_all_zonelists(NULL);
| Memory不支持热插拔, 为每个zone建立后备的zone,
| 每个zone及自己后备的zone,形成zonelist
|
|---->pg_data_t *pgdat = NULL;
| pgdat = &contig_page_data;(单node)
|
|---->build_zonelists(pgdat);
| 为每个zone建立后备zone的列表
|
|---->struct zonelist *zonelist = NULL;
| enum zone_type j;
| zonelist = &pgdat->node_zonelists[0];
|
|---->j = build_zonelists_node(pddat, zonelist, 0, MAX_NR_ZONES - 1);
| 为pgdat->node_zones[0]建立后备的zone,node_zones[0]后备的zone
| 存储在node_zonelist[0]内,对于node_zone[0]的后备zone,其后备的zone
| 链表如下(只考虑UMA体系,而且不考虑ZONE_DMA):
| node_zonelist[0]._zonerefs[0].zone = &node_zones[2];
| node_zonelist[0]._zonerefs[0].zone_idx = 2;
| node_zonelist[0]._zonerefs[1].zone = &node_zones[1];
| node_zonelist[0]._zonerefs[1].zone_idx = 1;
| node_zonelist[0]._zonerefs[2].zone = &node_zones[0];
| node_zonelist[0]._zonerefs[2].zone_idx = 0;
|
| zonelist->_zonerefs[3].zone = NULL;
| zonelist->_zonerefs[3].zone_idx = 0;
|
|---->build_zonelist_cache(pgdat);
|---->pdat->node_zonelists[0].zlcache_ptr = NULL;
| UMA体系结构
|
|---->for_each_possible_cpu(cpu)
| setup_pageset(&per_cpu(boot_pageset, cpu), 0);
|详见下文
|---->vm_total_pages = nr_free_pagecache_pages();
| 业务:获得所有zone中的present_pages总和.
|
|---->page_group_by_mobility_disabled = 0;
| 对于代码中的判断条件一般不会成立,因为页数会最够多(内存较大)

















 1827
1827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









