





三种蕴含了单词含义的表示方法:
- 基于同义词词典的方法(人工整理)
- 基于计数的方法(本章重点)
- 基于推理的方法(word2vec)
下面将按照顺序进行介绍。
1. 同义词词典
在同义词词典中,具有相同或相似含义的单词被归到同一个组中,比如,使用同义词词典,我们可以知道car的同义词有automobile、motorcar等。
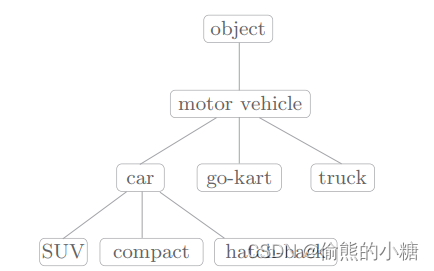
另外,这幅图还涉及到上位和下位的概念。单词motor vehicle是car的上位概念,SUV、compact和hatch-back这些更具体的车种是car的下位概念。
一个著名的同义词词典:WordNet(可以获得单词的近义词,或者利用单词网络来计算单词之间的相似度)
同义词词典存在的问题:难以顺应时代变化、人工成本高、无法表示单词的微妙差异等。所以后面的基于计数和基于推理的方法,可以有效克服这些缺点。
2. 基于计数的方法
目标:从语料库种自动且高效地提取本质。
2.1 基于Python的语料库的预处理
#后面都会以这个句子为例进行处理
text = "You say goodbye and I say hello."
text = text.lower() #将字母都变成小写
text = text.replace('.',' .') #在句号前面加一个空格
words = text.split(' ') #按照空格将句子拆分成单词
#其实这个句号也可以用正则表达式来匹配的
#words = ['you', 'say', 'goodbye', 'and', 'i', 'say', 'hello', '.']
下面使用Python字典创建单词ID和单词的对照表:
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
#id_to_word = {0: 'you', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'i', 5: 'hello', 6: '.'}
#word_to_id = {'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}
然后将单词列表words转化成单词ID列表:
import numpy as np
corpus = [word_to_id[w] for w in words]
corpus = np.array(corpus)
#corpus = array([0, 1, 2, 3, 4, 1, 5, 6])
至此,语料库的预处理结束,我们可以得到以下三个变量:corpus(单词ID列表)、word_to_id、id_to_word。下面我们将使用基于计数的方法,将单词表示为向量。
2.2 单词的分布式表示
使用类似(R,G,B) = (201,23,30)来表示深绯这种方式,将单词表示为一个向量。
2.3 分布式假设
分布式假设:某个单词的含义由它周围的单词形成。
2.4 共现矩阵
根据之前对语料库的预处理,我们的句子中一共含有7个单词,下面将窗口大小设置为1,以you为例,计算其上下文共现的单词的频数。 其实共现就是共同出现的意思,由于在原句"You say goodbye and I say hello."中,you只出现了一次,它的上下文只出现过say(窗口大小为1,也就是只看左边和右边各一个位置),所以在共现矩阵中,you对应的这一行是[0,1,0,0,0,0, 0]。
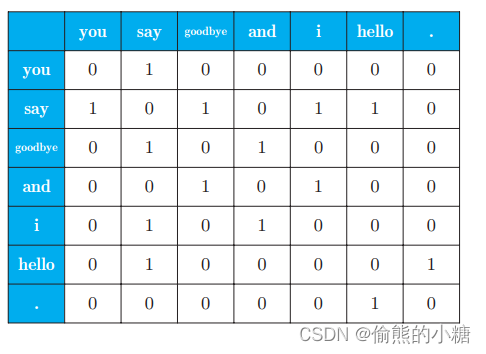 以下是生成共现矩阵的代码:
以下是生成共现矩阵的代码:
def create_co_matrix(corpus,vocab_size,window_size = 1):
corpus_size = len(corpus)
co_matrix = np.zeros((vocab_size,vocab_size),dtype=np.int32)
for idx,word_id in enumerate(corpus):
for i in range(1,window_size+1):
left_idx = idx - i
right_idx = idx + i
if left_idx >= 0:
left_word_id = corpus[left_idx]
co_matrix[word_id,left_word_id] += 1
if right_idx < corpus_size:
right_word_id = corpus[right_idx]
co_matrix[word_id,right_word_id] += 1
return co_matrix
2.5 向量间的相似度
使用余弦相似度来表示向量的相似度。设有
x
=
(
x
1
,
x
2
,
x
3
,
.
.
.
,
x
n
)
x=(x_1,x_2,x_3,...,x_n)
x=(x1,x2,x3,...,xn)和
y
=
(
y
1
,
y
2
,
y
3
,
.
.
.
,
y
n
)
y=(y_1,y_2,y_3,...,y_n)
y=(y1,y2,y3,...,yn)两个向量,它们之间的余弦相似度定义为:
s
i
m
i
l
a
r
i
t
y
(
x
,
y
)
=
x
⋅
y
∥
x
∥
∥
y
∥
=
x
1
y
1
+
x
2
y
2
+
.
.
.
+
x
n
y
n
x
1
2
+
.
.
.
+
x
n
2
y
1
2
+
.
.
.
y
n
2
similarity(x,y)=\frac{x·y}{\left \| x \right \| \left \| y\right \| }=\frac{x_1y_1+x_2y_2+...+x_ny_n}{\sqrt{x_1^2+...+x_n^2} \sqrt{y_1^2+...y_n^2} }
similarity(x,y)=∥x∥∥y∥x⋅y=x12+...+xn2y12+...yn2x1y1+x2y2+...+xnyn
该公式的实现:
def cos_similarity(x,y,eps = 1e-8):
nx = x / (np.sqrt(np.sum(x ** 2)) + eps) #eps是一个微小值,为防止除数为0
ny = y / (np.sqrt(np.sum(y ** 2)) + eps)
return np.dot(nx,ny)
2.6 相似单词的排序
使用2.5介绍的函数可以实现计算两个单词的余弦相似度,下面可以实现另外一个函数,使得查询某个单词时,按照相似度由高到低的顺序返回其相关词。
most_similar(query,word_to_id,id_to_word,word_matrix,top=5)
参数表:
| 参数名 | 说明 |
|---|---|
| query | 查询词 |
| word_to_id | 单词-单词ID的字典 |
| id_to_word | 单词ID-单词的字典 |
| word_matrix | 汇总了单词向量的矩阵 |
| top | 显示到前几位 |
函数实现:
def most_similar(query,word_to_id,id_to_word,word_matrix,top=5):
#1.取出查询词
if query not in word_to_id:
print("%s is not found" % query)
return
print('\n[query]'+query)
query_id = word_to_id[query]
query_vec = word_matrix[query_id]
#2.计算余弦相似度
vocab_size = len(id_to_word)
similarity = np.zeros(vocab_size)
for i in range(vocab_size):
similarity[i] = cos_similarity(word_matrix[i],query_vec)
#3.基于余弦相似度,降序输出值
count = 0
for i in (-1 * similarity).argsort():
if(id_to_word[i] == query):
continue
print('%s : %s '%(id_to_word[i],similarity[i]))
count += 1
if count > top:
return
以下是查询you的例子:
most_similar('you',word_to_id,id_to_word,C,top=5)
#输出结果:
[query]you
goodbye : 0.7071067691154799
i : 0.7071067691154799
hello : 0.7071067691154799
say : 0.0
and : 0.0
. : 0.0
3. 基于计数的方法的改进
3.1 点互信息
上一节7提到的共现矩阵可以表示两个单词同时出现的次数,但是这种次数并不具备好的性质。比如,我们来考虑某个语料库中 the 和 car 共现的情况。在这种情况下,我们会看到很多“…the car…”这样的短语。因此,它们的共现次数将会很大。另外, car 和 drive 也明显有很强的相关性。但是,如果只看单词的出现次数,那么与 drive 相比, the 和 car 的相关性更强。这意味着,仅仅因为 the 是个常用词,它就被认为与 car 有很强的相关性。
为了解决上述问题,可以使用点互信息 (Pointwise Mutual Information,PMI)这一指标。
P
M
I
(
x
,
y
)
=
log
2
P
(
x
,
y
)
P
(
x
)
P
(
y
)
PMI(x,y)=\log_{2}{ \frac{P(x,y)}{P(x) P(y)}}
PMI(x,y)=log2P(x)P(y)P(x,y)
P(x)表示x发生的概率,P(x,y)表示x和y同时发生的概率。PMI的值越高,表示相关性越强。
假设
某个语料库中有 10 000 个单词,其中单词 the 出现了 100 次,则
P
(
"
t
h
e
"
)
=
100
10000
=
0.01
P("the")=\frac{100}{10000}=0.01
P("the")=10000100=0.01。另外, P(x, y) 表示单词 x 和 y 同时出现的概率。假设 the 和car 一起出现了 10 次,则
P
(
"
t
h
e
"
,
"
c
a
r
"
)
=
10
10000
=
0.001
P("the","car")=\frac{10}{10000}=0.001
P("the","car")=1000010=0.001。
下面使用共现矩阵来改写PMI公式:
P
M
I
(
x
,
y
)
=
log
2
P
(
x
,
y
)
P
(
x
)
P
(
y
)
=
log
2
C
(
x
,
y
)
N
C
(
x
)
N
C
(
y
)
N
=
log
2
C
(
x
,
y
)
⋅
N
C
(
x
)
C
(
y
)
PMI(x,y)=\log_{2}{ \frac{P(x,y)}{P(x) P(y)}} = \log_2{ \frac{ \frac{C(x,y)}{N} }{ \frac{C(x)}{N} \frac{C(y)}{N} } }=\log_2{ \frac{C(x,y)·N}{C(x)C(y)} }
PMI(x,y)=log2P(x)P(y)P(x,y)=log2NC(x)NC(y)NC(x,y)=log2C(x)C(y)C(x,y)⋅N
假设语料库的单词数量( N)为 10 000, the 出现 100 次, car 出现 20 次,drive 出现 10 次, the 和 car 共现 10 次, car 和 drive 共现 5 次。这时,如果从共现次数的角度来看,则与 drive 相比, the 和 car 的相关性更强。而如果从 PMI 的角度来看,结果为:
P
M
I
(
"
t
h
e
"
,
"
c
a
r
"
)
=
log
2
10
∗
10000
1000
∗
20
≈
2.32
PMI("the","car")=\log_2{ \frac{10*10000}{1000*20} }\approx{2.32}
PMI("the","car")=log21000∗2010∗10000≈2.32
P
M
I
(
"
c
a
r
"
,
"
d
r
i
v
e
"
)
=
log
2
5
∗
10000
20
∗
10
≈
7.97
PMI("car","drive")=\log_2{\frac{5*10000}{20*10}}\approx{7.97}
PMI("car","drive")=log220∗105∗10000≈7.97
结果表明drive和car有更强的相关性。
另外,为了解决两个单词的共现次数为0的时候出现的
log
2
0
=
−
∞
\log_2{0}=-\infty
log20=−∞的问题,实践中会使用正的点互信息(Positive PMI,PPMI)。
P
P
M
I
(
x
,
y
)
=
m
a
x
(
0
,
P
M
I
(
x
,
y
)
)
PPMI(x,y)=max(0,PMI(x,y))
PPMI(x,y)=max(0,PMI(x,y))
PPMI的实现:
def ppmi(C, verbose=False, eps=1e-8): # verbose决定是否输出运行情况的标志
M = np.zeros_like(C,dtype=np.float32)
N = np.sum(C)
S = np.sum(C, axis = 0)
total = C.shape[0] * C.shape[1]
cnt = 0
for x in range(C.shape[0]):
for y in range(C.shape[1]):
#pmi = np.log2(C[x,y]*N / S[x]*S[y] + eps)
pmi = np.log2(C[x,y] * N /(S[x]*S[y]) + eps)
M[x,y] = max(0,pmi)
if verbose:
cnt += 1
if cnt % (total//100+1) == 0:
print('%.1f%% done'%(100*cnt/total))
return M
使用这个函数可以将共现矩阵转换为PPMI矩阵。
我们将2.4节中生成的共现矩阵转化为PPMI矩阵,如图所示:
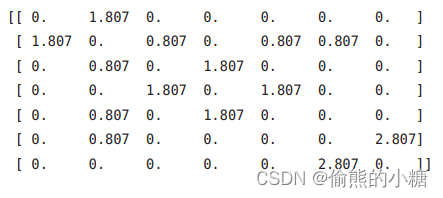
但是,这个PPMI矩阵依旧存在很大问题,随着语料库的词汇量增加,各个单词的维数也会增加,如果词汇量达到10万,那么单词向量的维数也会达到10万。
观察以上PPMI矩阵,发现其中很多元素为0,这表明向量中很多元素并不重要,也就是说,每个元素拥有的“重要性”很低。并且这样的向量很容易受到噪声影响,稳定性差。针对以上问题,一个常见方法就是降维。
3.2 降维
降维就是减少向量的维度,但是并不是简单减少,而是在尽量保留重要信息的基础上减少。
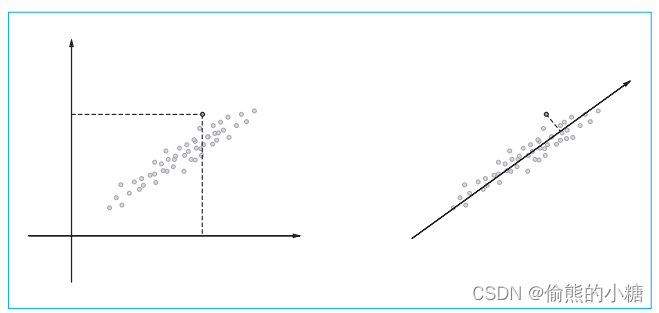 如图所示,观察左边二维数据的分布,可以导入一个新的轴,将原来用二维坐标表示的点表示为一维的。在多维数据中也可以进行相似的处理。
如图所示,观察左边二维数据的分布,可以导入一个新的轴,将原来用二维坐标表示的点表示为一维的。在多维数据中也可以进行相似的处理。
向量中大多数元素为0的矩阵(或向量)称为稀疏矩阵(或稀疏向量)。降维的重点在于从稀疏向量中找到重要的轴,用更少的维度对其进行重新表示。结果,稀疏矩阵就会被转化为大多数元素均不为0的密集矩阵。这个密集矩阵就是我们想要的单词的分布式表示。

















 8832
8832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









