 词向量与Skip-gram模型
词向量与Skip-gram模型





 本文介绍了Word2Vec作者提出的skip-gram模型及其扩展,包括高频词二次采样、分层softmax、短语向量表示等技术,展示了模型在类比推理任务上的优秀性能。
本文介绍了Word2Vec作者提出的skip-gram模型及其扩展,包括高频词二次采样、分层softmax、短语向量表示等技术,展示了模型在类比推理任务上的优秀性能。
简介
这篇文章是Word2Vec的作者,主要工作:
1. 提出skip-gram模型的扩展。如通过对高频词的二次取样(Subsampling)以提高高频词词向量的训练速度(2-10倍)和较低频词的词向量表示的质量;
skip-gram模型:学习高质量分布式向量表示的有效方法,可以捕获大量准确的句法和语义关系。
2. 提出了简化的噪声对比估计变体(simplified variant of Noise Contrastive Estimation,NCE)——分层softmax(Hierarchical softmax ,HS)训练skip-gram模型。(与在之前的工作使用过的更复杂的分层softmax相比,该算法可提高高频词的训练速度和提供更好的高频词的向量表示。
3. 使用向量来表示完整短语使得Skip-gram模型更具表现力。旨在通过组合单词向量来表示句子含义的其他技术,例如递归自动编码器(Recursive autoencoders),也将受益于使用短语向量而不是单词向量。
4. 描述了一种负采样(negative sampling)作为分层softmax的简单替代方案
5. 词表示的内在局限性是无法表示词序,也不能表示惯用短语。作者提出了一个简单的方法来寻找文本中的短语,并表示学习数百万个短语的良好向量表示是可能的。
6. 基于单词的模型如何扩展到基于短语的模型
1). 使用数据驱动方法(data-driven approach)识别大量短语,然后在训练期间将短语视为单独的标记。
2). 为了评估短语向量的质量,作者开发了一个类比推理任务测试集
7.描述了skip-gram模型的另一个性质:组合性(Compositionality)——通过对单词向量表示进行基本的数学运算,可以获得程度不明显的的语言理解程度。
研究工作
语料库:an internal Google dataset with one billion words
实验过程:
1. Skip-gram模型
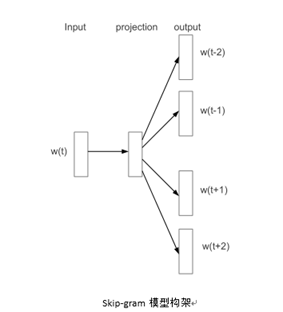
Skip-gram的训练目标是预测某个词的周围可能出现的词的词向量表示(COWB模型与此相反)。
给定一系列训练词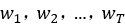 ,skip-gram模型的目标是最大化平均对数概率:
,skip-gram模型的目标是最大化平均对数概率:
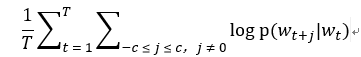
其中c是训练上下文的大小,也就是训练词wt的前后各c个词 (也可以是中心词wt的函数)。较大的c代表有更多的训练示例,从而准确性更高,但是训练时间开销大。基本的skip-gram公式使用softmax函数:
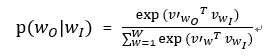
其中vw和v’w分别是w的输入向量表示和输入向量表示,W是词汇表中的单词数。这个公式不实际,因为计算量∇log p(wO |wI)与W成正比,而W往往很大。
1.2 分层softmax(Hierarchical softmax,HS)
优点:计算效率上近似为full softmax;不需要计算神经网络中W个输出结点的概率分布,只需要评估log_2W个结点。
使用二叉树(binary tree)表示输出层,W个单词代表它的叶节点,并且,对于每个节点,显式地表示它的子节点的相对概率。这些定义了赋予单词概率的随机游走(random walk)。每个单词w都可以通过根节点被找到。每个节点的子节点存储和这个词相关的词。节点中只存储该词与子节点词的相对概率。
分层的softmax定义p(wO |wI)为:
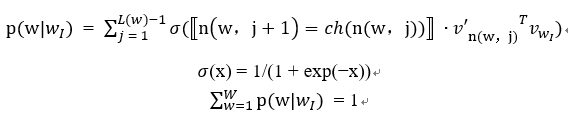
n(w,j)表示从根到w的路径上第j个结点,L(w)表示该路径的长度。对于任何内部节点n,设ch(n)是n的任意固定子节点,如果x为真,则⟦x⟧ = 1,否则为-1。
这样一来,∇log p(w_O |w_I)和log p(w_O |w_I) 的计算开销就与L(w_O )成正比,平均不大于logW。
本文使用的是二叉哈夫曼树(binary Huffman tree),高频词编码较短(训练较快),低频词汇编码较长。之前已经观察到,对于基于神经网络的语言模型来说,根据频率将单词进行分组是一种非常简单的加速技术。
1.2 负采样(Negative sampling)(NEG)
分层softmax的另一种可替代方案是噪声对比估计(NCE)。NCE认为一个好的模型应该能够通过logistic回归来区分数据和噪声。这与hinge loss相似,通过将数据排序在噪声之上来训练模型。
作者定义负采样(NEG):
![log〖σ(〖〖v'〗_(w_O )〗^T v_(w_I ))〗 + ∑_(i=1)^k▒E_(w_i~P_n (w)) [log〖σ(-〖〖v'〗_(w_i )〗^T v_(w_I ))〗 ]](https://i-blog.csdnimg.cn/blog_migrate/0bad5892869840f448dacd5d2bb572bb.png)
它用来替换skip-gram模型中的每个log p(w_O |w_I)项。任务是利用logistic回归从噪声分布Pn(w)中区分目标词w_O,其中每个数据样本有k个负样本。
k值:5-20(小型训练集);2-5(大型训练集)。
负采样(negative sampling, NEG)和噪声对比估计(NCE)的主要区别在于,NCE需要样本和噪声分布P_n (w)的数值概率,而负采样只需要样本。当NCE近似地使softmax的对数概率最大化时,这个性质对于我们的应用并不重要。
NEG和NCE都将Pn (w)作为自由参数,我们调查了许多Pn (w)的选择,发现在我们尝试的每个任务(包括语言建模)中,提高到3/4次方的unigram分布U(w)显著优于unigram和均匀分布。即:
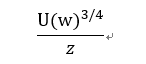
1.3 高频词的二次采样(subsampling of frequent words)
二次抽样方法:每个词wi 被丢弃的概率为:

其中f(w_i)表示单词w_i的出现频率;
作用:加速了学习效率;提高了稀有词的学习向量的准确性。
2. 学习短语
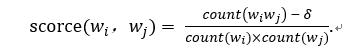
δ: discounting coefficient 打折系数,防止形成太多由不常见的词组成短语;
结果和总结:
句法类比syntactic analogies (such as “quick” : “quickly” :: “slow” : “slowly”);
语义类比semantic analogies(such as the country to capital city relationship)。
1. 结果
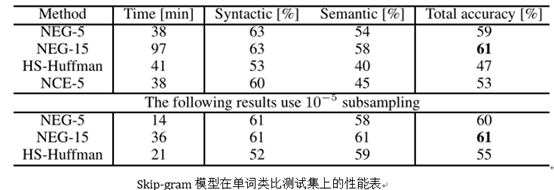
NEG-k: k个负样本的负采样;
NCE: 噪声对比估计;
HS-Huffman代表基于频率的Huffman码的分级softmax。
从表中可以看出,在类比推理任务上,负采样的性能优于层次Softmax,甚至比噪声对比估计的性能稍好。
频繁词的二次采样(Subsampling)使训练速度提高了几倍,使词的表示更加准确。
Skip-gram模型的线性使得其向量更适合于这种线性类比推理。标准的s型递归神经网络(高度非线性)所学习的向量随着训练数据量的增加而显著提高,这表明非线性模型也倾向于使用线性结构的词表示。
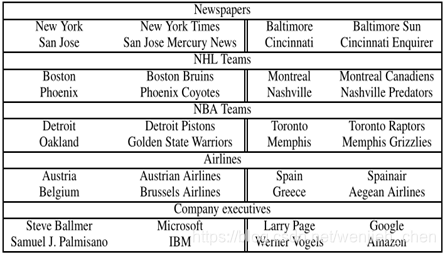
短语的类比推理任务的例子(完整的测试集有3218个例子)。目标是使用前三个短语计算第四个短语。
我们的最佳模型在这个数据集上达到了72%的准确率。

短语类比数据集上skip-gram模型的准确性
与之前的结果一致,由一个分层softmax和二次采样构成的模型来学习得到最佳短语表示。
4. 组合性

我们证明了通过skip-gram模型学习的单词和短语表示呈现出一种线性结构,这使得使用简单的向量算术来执行精确的类比推理成为可能。
同时我们发现skip-gram表示展示了另一种线性结构,这种结构使得通过向量表示相加来有意义地组合单词成为可能。如上图。
5. 已发表的词表示模型比较:
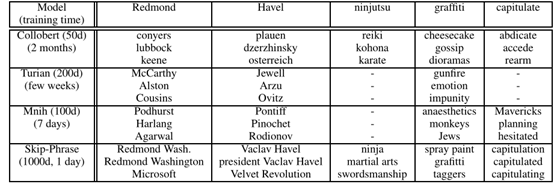
上图表明,在大型语料库上训练的skip-gram模型在学习向量表示的质量上明显优于其他所有模型。且训练时间成本最低。
原因:训练了大约300亿个单词,这比之前工作中使用的典型数据多了2-3个数量级。
总结:
- 展示了如何使用Skip-gram模型来训练单词和短语的分布式表示,并展示了这些表示呈现线性结构,这使得精确的类比推理成为可能。本文介绍的技术也可用于训练连续的bag of word模型。
- 频繁词的采样:提高训练速度和更好的不常见词的向量表示。
- 负采样算法:学习准确的向量的表示,尤其是高频词的向量表示。
- 影响性能的最关键的决定是模型架构的选择、向量的大小、子采样率和训练窗口的大小。
- 表示短语向量
1). 使用简单的向量加法就可以在某种程度上有意义地组合单词向量;
2). 简单地用一个标记来表示短语向量。
这两种方法的结合提供了一种强大而简单的方式来表示较长的文本,同时具有最小的计算复杂性。
因此,我们的工作可以看作是对现有方法的补充,现有方法试图用递归矩阵向量运算来表示短语。
生词:
discounting coefficient 打折系数
random walk随机游走
hinge loss铰链损失
unigram分布U(w)
论文引用
[1]. Mikolov T . Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013, 26:3111-3119.

















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









