



 文章介绍了解释器模式在计算机科学中的应用,包括如何定义语言的文法表示,抽象语法树的构建,以及解释器模式的角色和案例。优点包括易于扩展和维护简单文法,但缺点是处理复杂文法和执行效率低。
文章介绍了解释器模式在计算机科学中的应用,包括如何定义语言的文法表示,抽象语法树的构建,以及解释器模式的角色和案例。优点包括易于扩展和维护简单文法,但缺点是处理复杂文法和执行效率低。
目录
定义
给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
以计算器为例,其语法规则为
expression ::= value | plus | minus
plus ::= expression ‘+’ expression
minus ::= expression ‘-’ expression
value ::= integer
这里的符号“::=”表示“定义为”的意思,竖线 | 表示或,左右的其中一个,引号内为字符本身,引号外为语法
解释:
- expression可以取value、plus、minus三者其一。
- plus可以只可取expression,即上面三个都可以取。例如:value+plus+value = value+value+value+value(如果取到plus,即非终结者表达式,则将expression '+' expression取代plus,直至全为终结者表达式)
- minus与plus相同
- value只能取到Integer的值,属于终结者表达式
在计算机科学中,抽象语法树(AbstractSyntaxTree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
用树形来表示符合文法规则的句子。
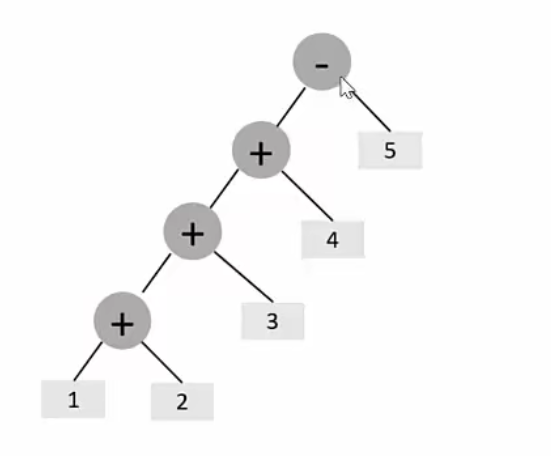
结构
解释器模式包含以下主要角色。
- 抽象表达式角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
- 终结符表达式角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
- 非终结符表达式角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
- 环境角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
- 客户端:主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
案例
抽象表达式类
public abstract class AbstractExpression {
abstract int interpret(Context context);
}环境类(作为终结者解释器与非终结者解释器取值的容器)
public class Context {
private Map<Variable , Integer> map = new HashMap<>();
//添加表达式
public void assign(Variable var, Integer value){
map.put(var,value);
}
//获取表达式的值
public int getValue(Variable var){
return map.get(var);
}
}非终结者解释器
public class Variable extends AbstractExpression{
private String name;
public Variable(String name) {
this.name = name;
}
@Override
int interpret(Context context) {
//由于还未终结,因此要接着拼接,自身将要拼接的的内容返回
return context.getValue(this);
}
public String toString(){
return name;
}
}
//加法解释器
public class Plus extends AbstractExpression{
private AbstractExpression left;
private AbstractExpression right;
public Plus(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
int interpret(Context context) {
//根据初始化时的值来判断执行终结者还是非终结者的解释器
return left.interpret(context)+right.interpret(context);
}
public String toString(){
return left.toString()+"+"+right.toString();
}
}
//减法表达式
public class Minus extends AbstractExpression{
private AbstractExpression left;
private AbstractExpression right;
public Minus(AbstractExpression left, AbstractExpression right) {
this.left = left;
this.right = right;
}
@Override
int interpret(Context context) {
return left.interpret(context)-right.interpret(context);
}
public String toString(){
return left.toString()+"-"+right.toString();
}
}终结者标识符
public class Value extends AbstractExpression{
private int value;
public Value(int value) {
this.value = value;
}
@Override
int interpret(Context context) {
return value;
}
public String toString(){
return String.valueOf(value);
}
}测试
public class Client {
public static void main(String[] args) {
Context context = new Context();
//定义了四个表达式变量
Variable a = new Variable("a");
Variable b = new Variable("b");
Variable c = new Variable("c");
Variable d = new Variable("d");
Value value = new Value(5);
context.assign(a,1);
context.assign(b,2);
context.assign(c,3);
context.assign(d,4);
//创建一个总表达式对象 a+b-c+d-value
AbstractExpression abstractExpression =new Minus(new Plus(a,new Plus(new Minus(b,c),d)),value);
System.out.println(abstractExpression+"="+abstractExpression.interpret(context));
}
}a+b-c+d-5=-1
其实就是遍历二叉树,由于终结者表达式与非终结者表达式根据均继承了抽象表达式重写了interpret()方法,因此,在执行left与right的interpret()方法时,根据对象类型分别执行不同的重写方法。
优点
- 易于改变和扩展文法。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
- 实现文法较为容易。在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂。
- 增加新的解释表达式较为方便。如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合 "开闭原则"。
缺点
- 对于复杂文法难以维护。在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护。
- 执行效率较低。由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
使用场景
- 当语言的文法较为简单,且执行效率不是关键问题时。
- 当问题重复出现,且可以用一种简单的语言来进行表达时。
- 当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候。



















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











