






第一节 模型评估与模型参数选择
前言:
若对于给定的输入x,若某个模型的输出y^=f(x)偏离真实目标值y,那么就说明模型存在误差;
y^偏离y的程度可以用关于y^和y某个函数L(y,y^)来表示,y^为误差的度量标准;这样的函数 L(y,y^)称为损失函数
训练集上的平均误差被称为训练误差,测试集上的误差称为泛化误差。
由于我们训练得到一个模型最终的目的是为了在未知的数据上得到尽可能准的结果,因此泛化误差是衡量一个模型泛化能力的重要标准。
数据集:训练集,验证集,测试集
·误差:预测输出与真实输出v之间的差异 ; ·经验误差、训练误差,在训练集上的误差; ·泛化误差:在新样本上的误差。
·泛化误差越小越好,经验误差不一定越小越好,可能导致过拟合。
1.验证集
当我们的模型训练好之后,我们并不知道他的表现如何。这个时候就可以使用验证集
(Validation Dataset)来看看模型在新数据( 验证集和测试集是不同的数据)上的表现如何。同时通过调整超参数,让模型处于最好的状态。
作用: (1)评估模型效果,为了调整超参数而服务
(2)调整超参数,使得模型在验证集上的效果最好
说明:
·验证集不像训练集和测试集,它是非必需的,如果不需要调整超参数,就可以不使用验证集,直接用测试集来评估效果。
·验证集评估出来的效果并非模型的最终效果,主要是用来调整超参数的,模型最终效果以测试集的评估结果为准。
2.测试集
通过测试集的评估,我们会得到一些最终的评估指标,例如:准确率、精确率、召回率、F1等。
3.划分数据集
(1)对于小规模样本集(几万量级),常用的划分比例:
训练集:验证集:测试集=6:2:2 训练集:测试集==8:2、7:3
(2)对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可。
例如有100w条数据,那么留1w验证集,1w测试集即可。·1000w 的数据,同样留1w验证集和1w测试集。
(3)超参数越少,或者超参 整,那么可以减少验证集的比例,更多的分配给训练集。
过拟合:将训练样本自身的一些特点当作所有样本潜在的泛化特点。
表现:在训练集上表现很好,在测试集上表现不好。
过拟合的原因:
(1)训练数据太少(比如只有几百组)
(2)模型的复杂度太高(比如隐藏层层数设置的过多,神经元的数量设置的过大) (3)数据不纯
为了选择效果最佳的模型,防止过拟合的问题,通常可以采取的方法有:
1.移除特征,降低模型的复杂度:减少神经元的个数,减少隐藏层的层数。2.-训练集增加更多的数据。3.重新清洗数据。4.数据增强。5.正则化。6.早停。
欠拟合:还没训练好。 (1).欠拟合的原因:
1.数据未做归一化处理 训练集上的表现 测试集上的表现 结论
2.神经网络拟合能力不足 不好 不好 欠拟合
3.数据的特征项不够
(2).解决方法:
1.寻找最优的权重初始化方案
2.增加网络层数、epoch
3.使用适当的激活函数、优化器和学习率
4.减少正则化参数
5.增加特征
第二节 监督学习
前言:
如果数据集中样本点只包含了模型的输入x,那么就需要采用非监督学习的算法。 如果这些样本点以(x,y)这样的输入-输出二元组的形式出现(有数据标签),那么就可以采用监督学习的算法。
模型与最优化算法的选择,很大程度上取决于能得到什么样的数据。
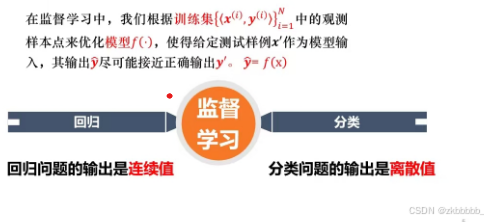
1.回归
1.预测房价 假设我们想要预测某个城市的房价。我们可以收集到该城市过去几年的房价数据,以及一些相关的因素,比如房屋的面积、房龄、所处区域、楼层等。我们可以使用这些数据建立一条最佳拟合直线,从而对未来的房价进行预测。
在这个例子中,自变量可以包括面积、房龄、所处区域等,因变量是房价。
我们可以通过最小二乘法来估计截距和斜率的值,从而得到一条最佳拟合直线。这条直线可以用来预测未来的房价,也可以用来分析不同因素对房价的影响。
2.预测销售额
·假设我们想要预测某家公司未来一年的销售额。我们可以收集到该公司过去几年的销售额数据,以及一些相关的因素,比如广告投入、促销活动、季节性因素等。我们可以使用这些数据建立一条最佳拟合直线,从而对未来的销售额进行预测。
在这个例子中,自变量可以包括广告投入、促销活动、季节性因素等,因变量是销售额。我们可以通过最小二乘法来估计截距和斜率的值,从而得到一条最佳拟合直线。这条直线可以用来预测未来的销售额,也可以用来分析不同因素对销售额的影响。
2.分类
想要预测(检测)的目标是猫,那么在数据集中猫为 正样本
( Positive),其他狗、兔子、狮子这些数据为负样本(Negative)。
·将这只猫预测(分类)为狗、兔子、其他预测结果为错(False);将这只猫预测为猫,预测结果为对(True)。
将正样本预测为正样本 (True Positive,TP) 将负类样本预测为正样本(False Positive,FP)
将正样本预测为负样本 (False Negative,FN) 将负类样本预测为负样本(True Negative,TN)

虽然准确率可以判断总的正确率,但是在样本不平衡的情况下,并不能作为很好的指标来衡量结果。
这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。


召回率越高,也代表网络可以该井的空间越大
把精确率(Precision)和召回率(Recall)之间的关系用图来表达,就是下面的PR曲线:
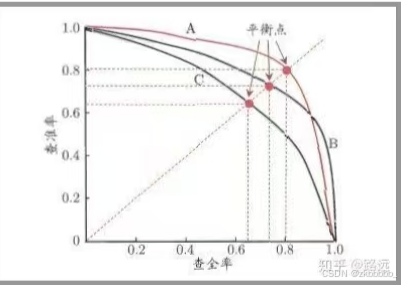
平衡点(BEP) P=R
AP(Average Precision):PR曲线下的面积。通常来说一个越好的分类器,AP值越高
mAP是多个类别AP的平均值。这个mAP的意思是对每个类的AP再平均,得到的就是mAP的值,mAP的大小一定在[0,1]区好。该指标是目标检测算法中最重要的一个。
F-度量则是在召回率与精确率之间去调和平均数;有时候在实际问题上,若重其中某一个度量,还可以给它加上一个权值a,称为F_a-度量:
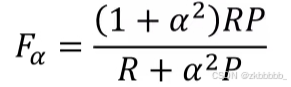
特殊地,当α = 1时
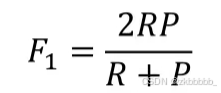
FI分数(Fl-score)是分类问题的一个衡量指标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









