






学习率如何影响训练?
在深度学习模型的训练过程中,普遍采用随机梯度下降或其变体(诸如Adam、RMSProp、Adagrad等)作为优化器。这些优化策略均允许用户设定学习率参数,该参数决定了优化器根据小批量梯度信息对模型权重进行调整的幅度。
若学习率设定偏低,虽能确保训练的稳定性,但会显著延长达到损失函数最小值的时间,因为每次权重更新的步长较小。
相反,若学习率设置过高,则训练过程可能无法收敛,甚至陷入发散状态,因过大的权重调整可能导致优化器跨越最小值点,反而加剧损失。
为了有效启动训练,通常会从较高的学习率入手,鉴于初始权重随机分配且远离最优状态,随后在训练进程中适时调低学习率,以实现更为精细的权重微调。
确定一个适宜的学习率起点,可采用多种策略。一种直观的方法是,通过试验一系列不同的学习率值,以识别出在不牺牲训练效率的前提下,能最大程度降低损失的那个值。此过程可始于一个相对较大的值(例如0.1),随后逐步尝试以指数级递减的值(如0.01、0.001等)。
若以较高学习率启动时,观察到损失在训练初期未现改善甚至反增,则可以转为采用较小学习率。当观察到损失函数值在初步迭代中开始减少,则表明该较小值接近可采用的学习率上限。
需要考虑的是,此时测出来的较接近的上限值也可能偏高,不足以支持长时间的训练周期,因为随着训练深入,模型对权重更新的精细度需求会增加。因此,合理选择起始学习率时,可能需要将其设定在比初步试验所得上限低1至2个数量级的水平。
一个聪明的学习率调参方法
在论文“Cyclical Learning Rates for Training Neural Networks”的第 3.3 节中描述了一种强大的技术,用于为神经网络选择一系列学习率。具体操作如下:
首先从低学习率开始训练一个网络,并成倍增加每批的学习率。
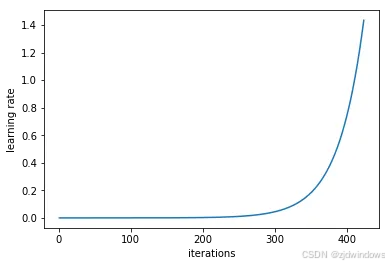
然后记录每个批次的学习率和训练损失。然后,绘制损失和学习率。
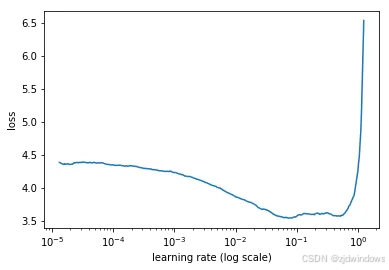
从图可以发现:在学习率低的情况下,损失缓慢改善,然后训练加速,直到学习率变得太大并且损失增加,整个训练过程开始发散。
此时可以图表上选择一个损失减少最快的点。在上图中,可以发现当学习率介于 0.001 和 0.01 之间时,损失函数会迅速减小。
查看这些数字的另一种方法是计算损失的变化率(损失函数相对于迭代数的导数),然后在 y 轴上绘制变化率,在 x 轴上绘制学习率
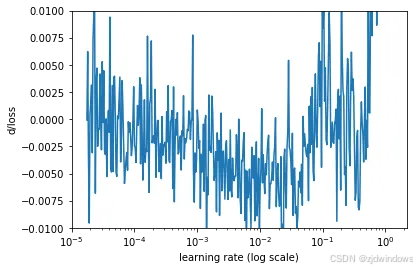
这个图看起来很嘈杂,我们可以使用简单的移动平均线来消除它。
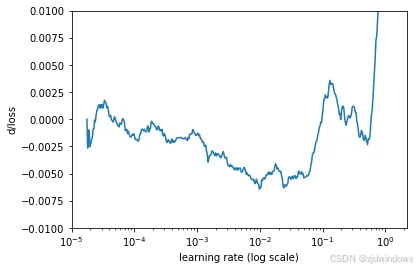
在这张图上,我们可以找到最小值。它接近lr=0.01。
总结
1 . 每 个 I t e r a t i o n 逐渐增加学习率,观察 l o s s的变化
2 . 选择一个损失下降最快的点对应的学习率:观察L o s s 梯度,找到下降最快的地方,就可以作为一个初始学习率设置
实操
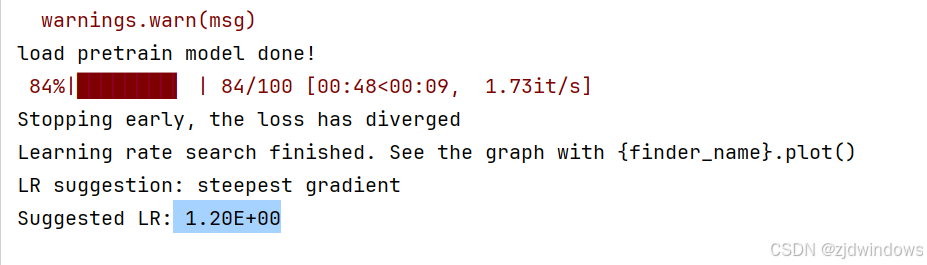
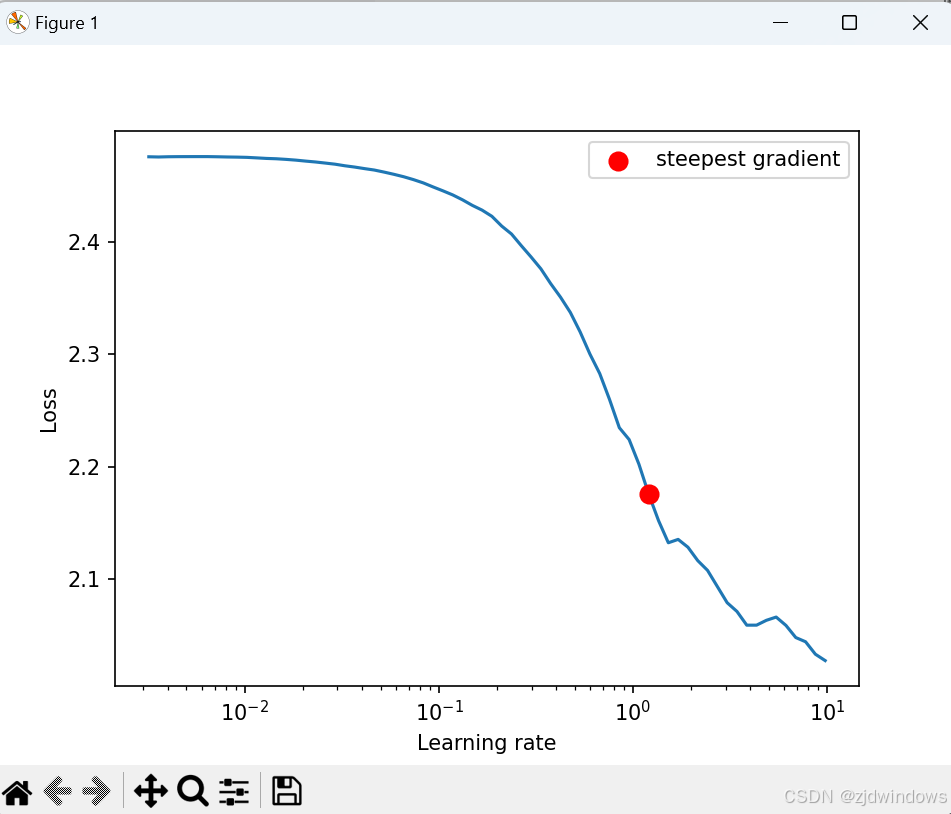
import matplotlib
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.join(BASE_DIR, '..'))
import argparse
import torch.optim as optim
import torch.nn as nn
from torch.utils.data import DataLoader
from mydatasets.camvid_dataset import CamvidDataset
from tools.common_tools import setup_seed, show_confMat, plot_line, Logger, check_data_dir
from config.camvid_config import cfg
from models.deeplabv3_plus import DeepLabV3Plus
from models.unet import UNet, UNetResnet
from models.segnet import SegNet, SegResNet
from torch_lr_finder import LRFinder
setup_seed(12345) # 先固定随机种子
parser = argparse.ArgumentParser(description='Training')
parser.add_argument('--lr', default=None, help='learning rate', type=float)
parser.add_argument('--max_epoch', default=None)
parser.add_argument('--train_bs', default=0, type=int)
parser.add_argument('--data_root_dir', default=r"E:\cv_study\study_datasets\camvid_from_paper",
help="path to your dataset")
args = parser.parse_args()
cfg.lr_init = args.lr if args.lr else cfg.lr_init
cfg.train_bs = args.train_bs if args.train_bs else cfg.train_bs
cfg.max_epoch = args.max_epoch if args.max_epoch else cfg.max_epoch
if __name__ == '__main__':
# 设置路径
path_model_50 = os.path.join(BASE_DIR, "..","..", "..", "pretrained_model", "resnet50-19c8e357.pth") # segnet
# ------------------------------------ step 1/5 : 加载数据------------------------------------
# 构建Dataset实例
root_dir = args.data_root_dir
train_img_dir = os.path.join(root_dir, 'train')
train_lable_dir = os.path.join(root_dir, 'train_labels')
path_to_dict = os.path.join(root_dir, 'class_dict.csv')
check_data_dir(train_img_dir)
check_data_dir(train_lable_dir)
train_set = CamvidDataset(train_img_dir, train_lable_dir, path_to_dict, cfg.crop_size)
train_loader = DataLoader(train_set, batch_size=cfg.train_bs, shuffle=True, num_workers=1)
# ------------------------------------ step 2/5 : 定义网络------------------------------------
model = SegResNet(num_classes=train_set.cls_num, path_model=path_model_50)
# ------------------------------------ step 3/5 : 定义损失函数和优化器 ------------------------------------
loss_f = nn.CrossEntropyLoss().to(cfg.device)
optimizer = optim.SGD(model.parameters(), lr=1e-3, weight_decay=1e-4)
# ------------------------------------ step 4/5 : 训练 --------------------------------------------------
# 接口:data loader、model、optimizer、loss_f
lr_finder = LRFinder(model, optimizer, loss_f, device=cfg.device)
lr_finder.range_test(train_loader, end_lr=100, num_iter=100)
lr_finder.plot() # to inspect the loss-learning rate graph



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









