




 本文介绍了如何利用大语言模型增强企业知识库的智能搜索功能,通过意图识别、向量匹配和引导式搜索提高搜索精度。文章详细探讨了基于AmazonOpenSearch和AmazonKendra的搜索引擎架构,以及如何结合大语言模型进行智能问答和非结构化数据注入,以实现个性化和高效的信息检索。
本文介绍了如何利用大语言模型增强企业知识库的智能搜索功能,通过意图识别、向量匹配和引导式搜索提高搜索精度。文章详细探讨了基于AmazonOpenSearch和AmazonKendra的搜索引擎架构,以及如何结合大语言模型进行智能问答和非结构化数据注入,以实现个性化和高效的信息检索。
背景
大语言模型是自然语言处理领域的一项重要技术,能够通过学习大量的文本数据,生成具有语法和意义的自然语言文本。目前大语言模型已经成为了自然语言处理领域的一个热门话题,引起了广泛的关注和研究。
知识库需求在各行各业中普遍存在,例如制造业中历史故障知识库、游戏社区平台的内容知识库、电商的商品推荐知识库和医疗健康领域的挂号推荐知识库系统等。
本文旨在介绍一些企业知识库的典型实用场景,以及如何使用智能搜索,结合大语言模型,针对企业知识库提供基于搜索的精准问答。
基于智能搜索的大语言模型增强方案介绍
架构图
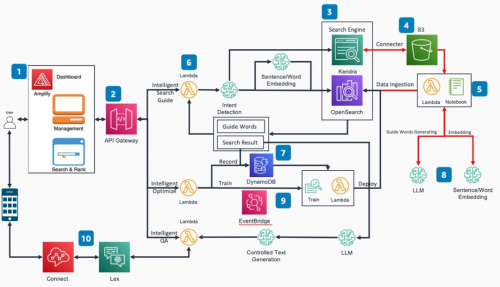
该平台将包括五大核心内容
1. 智能搜索
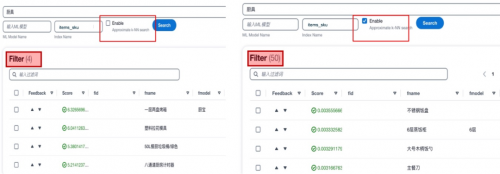
传统仅依靠关键词匹配的分词搜索的方式在很多场景下可以提供快速有效的查询,但是也存在一些固有的局限性。例如匹配一些包括停用词在内的无关词汇,无法识别同义词和缺乏抽象能力。为了解决这些问题,本方案中一方面使用意图识别大语言模型,对关键信息进行提取,从而可以有效的避免停用词等无法词汇对搜索造成的干扰。另一方面,引入AI/ML的方法来辅助实现语意搜索。具体来讲,使用同一个向量编码的大语言模型对搜索语句和文档数据库进行语意编码,在检索的过程中,使用knn方法进行向量匹配。以下是一个传统分词搜索与语意向量搜索的对比展示。可以看到,使用向量搜索功能后,可以召回更多自然语意上相近而关键词无关的内容,增加召回范围和提升搜索准确性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3953
3953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









