







 本文探讨了Fetch API中Response.json()返回Promise的原因,指出两次await分别对应HTTP的head和body传输。通过实验证明了该观点,还介绍了head与body分离特性的用途。此外,科普了大文件经中转站传输时使用流(stream pipe)的原理和优势。
本文探讨了Fetch API中Response.json()返回Promise的原因,指出两次await分别对应HTTP的head和body传输。通过实验证明了该观点,还介绍了head与body分离特性的用途。此外,科普了大文件经中转站传输时使用流(stream pipe)的原理和优势。
Response.json()为啥返回一个promise?
自从基于promise的fetch api横空出世以后,AJAX也改名叫AJAJ了。处理http请求变得更简单了,但使用fetch的时候经常需要这样写:
let response = await fetch(MY_URL);
let json = await response.json();
其中第一个await很好理解,等待网络响应需要await一下,可是response对象得到以后居然还需要一次await才能从response中得到body内容,不止是json()方法,其余的parse方法都返回一个promise:
- arrayBuffer()
- blob()
- formData()
- json()
- text()
为啥在本地处理数据需要异步执行?为啥不能同步?有网友认为对很大的原始数据进行JSON.parse很耗时,容易堵塞UI(问题连接),那为啥response.text()也返回一个promise?而且现在浏览器都有单独的UI线程。显然这个结论是不成立的。
当然,spec就是这样规定的,而且也没说为什么。。。规格详情见这里:
https://fetch.spec.whatwg.org/#dom-body-arraybuffer
很遗憾,在国内论坛里没找到和我有相同疑问的帖子,后来在StackOverflow上找到了。
stack上普遍认同的观点是,当http包很大的时候:
第一个promise等到head到来,第二个promise等到body到来。
我也认为这是最合理的解释,毕竟head写在body之前,也就是说,第一个promise结束后,http响应并没有结束,数据仍然在传输中!
做个实验:
首先准备一个30m的大文件big.file,放在服务器上,然后fetch它,并利用计时器来检测响应时间:
(async url => {
console.time('head');
console.time('all');
const response = await fetch(url);
console.log(response);
console.timeEnd('head');
await response.arrayBuffer();
console.timeEnd('all');
})('./big.file');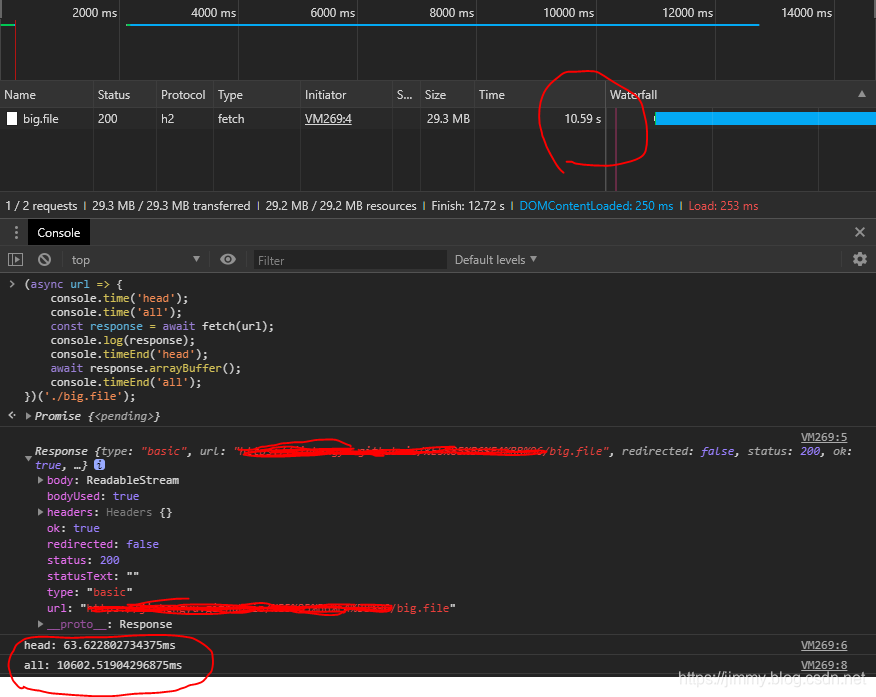
图中可以看到,当response对象拿到手只经过了64ms,而等整个http请求完成却花了10s!第一个fetch()方法得到的promise远远快于第二个promise。(当然,如果是一个小文件的话,你会发现2次时间相差无几)
而64ms结束后response对象顺利的打印出来了,可以看到,Response.body属性是一个ReadableStream流,说明此时数据流仍在进行,看不到body,但是head已经可以看到了。
实验证明了上述的观点:fetch后2次promise分别对应http的head和body的传输,这种新奇的玄学现象和写法也正是由于http的特性造成的(head和body分离)。
head与body分离的特性在很多场合是非常有用的,有时候我们不需要等待http传输完成,就可以从head中得到关键信息,从而影响后面的决策,比如从head中的状态码可以预先判断请求是否成功,不必将错误信息写在body中了。
大文件经过中转站时候需要用流(stream pipe)【科普】
上面涉及到了流的概念,我们对"stream"这个词应该并不陌生,很多场景下,"stream"更是代表着性能上的优化。在web应用的开发中,HTTP body stream更是家喻户晓。各种开发语言都提供有对HTTP实现的封装来实现对远端web服务的交互,某些高级类库更是提供了给开发人员方便使用的request stream和response stream的接口,只需要简单调用即可。那什么时候需要使用流呢?
首先,一切数据传输都是流。
比如用户请求一个图片,一般的做法是,服务器从FS(文件系统)中读出这个图片文件到内存中,然后把数据一点一点的传送给客户端,这里的“一点一点”就是形容“流”:像水流一样把数据分成若干份,一点一点的传输。
既然一切都是流,那为啥还有专门的流接口给我们使用?
因为如果请求的文件很大,就不能一次性把文件全部放到服务器宝贵的内存中了,而要一点一点的放,这就涉及到“转发”的概念了,FS或者DB(数据库)和服务器是不同的主机,FS或DB想要和客户端交换数据必须经过服务器。这时服务器需要做的是“监听”:每当FS取出一点数据就立刻把它送给客户端,然后赶紧删掉这个数据块等待下一块,循环这个操作直到结束,这样的话占用内存的空间从原来的整个文件下降到一个数据块的大小(通常几K)。
上面这个循环监听的过程就是一个建立管道的api:将外存(FS)接进来的ReadableStream通过管道(pipe)连接上通往客户端的WritableStream,服务器就是中转站,而中转站是不需要存储传输中的数据的。
所以一句话概括“流”:大文件通过中转站传输的时候需要通过管道连接。
参考链接(对2次await问题的各种讨论)
https://stackoverflow.com/questions/39170556/why-are-these-fetch-methods-asynchronous
https://fetch.spec.whatwg.org/#dom-body-arraybuffer
https://github.com/github/fetch/issues/240
https://stackoverflow.com/questions/37555031/why-does-json-return-a-promise


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











