



 文章讲述了作者在排查接口超时问题时,发现问题集中在nginx的半连接队列满、磁盘I/O过高以及一个未察觉的定时任务影响。最终,解决之道在于调整半连接队列大小、关注磁盘使用率并停止导致I/O飙升的定时任务。
文章讲述了作者在排查接口超时问题时,发现问题集中在nginx的半连接队列满、磁盘I/O过高以及一个未察觉的定时任务影响。最终,解决之道在于调整半连接队列大小、关注磁盘使用率并停止导致I/O飙升的定时任务。
背景
收到接口超时的告警,本以为和往常一样,按照公网、负载均衡、nginx、java服务层层抽丝剥茧很容易定位到问题,结果打脸了 。通过排查,定位到问题在nginx层,同样的请求,直接在nginx所在主机上curl后端服务响应很快(几十毫秒),但是请求nginx通过nginx代理后端的服务就非常慢(十几秒)。百思不得其解。
排查结果现象
-
现象1:netstat 查看连接状态,NGINX 主机出现大量CLOSE_WAIT 状态的连接
-
现网2:抓包发现,TCP握手阶段出现重传

-
现象3: netstat -s |grep -i listen ,发现出现SYN到LISTEN的包的丢失一直在增加

-
现象4:ss -ln|grep <nginx端口> 发现nginx对应监听端口的半连接队列为512,且已经基本满了(截图是已经修改后截的)

-
现象5:同一个NGINX 进程,A端口的代理不超时,B端口下的所有代理都超时了
-
现象6:分析NGINX 的访问日志中,超时请求较多的时候,出现大量状态码为499的请求
-
手动测试一次向nginx代理地址的请求,发现虽然超时,但是访问日志里request_time和upstream_response_time 字段的值都非常低(几十毫秒)。
处理过程
1、半连接队列满
通过TCP重传、SYN到LISTEN 阶段的丢包,ss -ln的 信息,基本确认是半连接队列满,很激动地开始了内核参数的修改
vim /etc/sysctl.conf
net.core.somaxconn = 3072
net.ipv4.tcp_max_syn_backlog = 3072
#让配置生效
sudo sysctl -p
#修改nginx的半连接队列长度,还需要在listen的配置项显示设置backlog值
vim nginc.conf
listen 8084 backlog=3072;
重启Nginx再次ss -ln|grep 8084 查看,当前队列已经调整为3072
处理完半连接的问题后,发现超时问题还是依旧,而且半连接队列过不了多久又会满,正常Nginx的处理性能,3072应该是错错有余的。继续找原因
2、磁盘使用率高
期间发现了磁盘使用率高,但是大意的认为不是根本原因,因为在出现超时请求之前磁盘IO也高。查看的方法如下图:
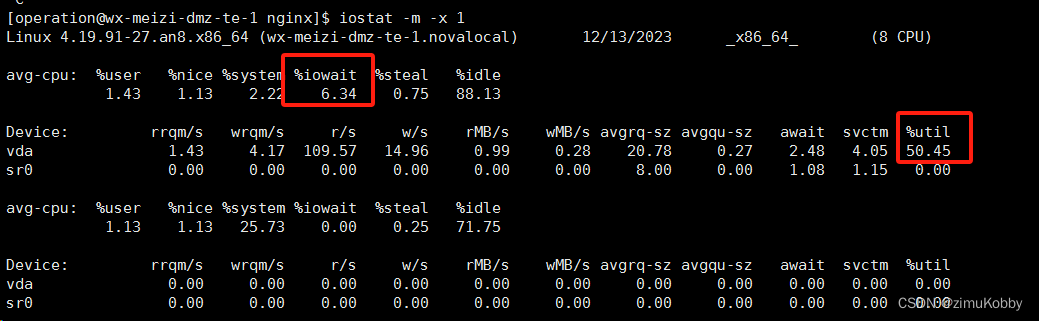
在出问题的时间段,%iowait 值达到10+%,%util 达到90+%,且经常飙升到100%。因为查看历史监控,主机的%util 一直比较高,因此认为主机磁盘不是根因。期间甚至怀疑是nginx的bug、更换了腾讯的tengine。结果问题依旧。
3、凌晨3点超时现象自动恢复
准备日次再定位问题,等早上再看的时候,超时问题已恢复,再查看一下状态码为499的请求分布情况,凌晨3点左右断崖式下降,不得其解,以为是业务上有什么变化,看了业务曲线,并没有业务量的的明显变化。
4、偶然的发现解决所有疑惑
无意中执行 ps -ef|grep nginx ,发现有一个tac nginx/logs/access.log 的进程,跟踪其父进程,发现是管理平台上一个定时任务在扫描nginx的访问日志,而且每次扫描都是tac 全量文件扫描。当前nginx日志已经达到好几个G,这个定时任务每5分钟全量读一下日志,虚拟机的普通盘肯定吃不消。于是赶紧停了这个任务。
任务停止后再次验证,发现磁盘IO使用率立即下降了,接口也不超时了,状态码499的问题也没有了。联想到nginx日志切割的时间是凌晨3点左右,那么3点左右超时恢复就说的过去了 ,因为最新的 access.log 数据量小,所以tac查看的时候不怎么消耗磁盘IO,因此业务在3点左右自动恢复。
结论
放过了一个磁盘IO的线索,坑了自己。原先也了解过iostat -m -x 查看的磁盘使用率,util=100% 不一定就表示繁忙程度就是100%,只是表示在每一个时钟刻度内都有磁盘IO发生。看来以后在运维和定位问题的时候,磁盘UTIL 超过60%的时候就得引起重视,超过90% 肯定要考虑扩容或者升级高配存储了。当前CPU使用率中%iowait指标也值得重点关注,在笔者的环境中,%iowait到10+% 就出现了前面的问题。

















 172万+
172万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









