




统计中文词频需要用到python中的jieba库,用cmd模式下的pip install jieba命令安装好jieba库,下载好三国演义的文档并保存。注意,三国演义文档要保存为以下编码,否则出现错误。(用的python3.6 64位)
代码如下: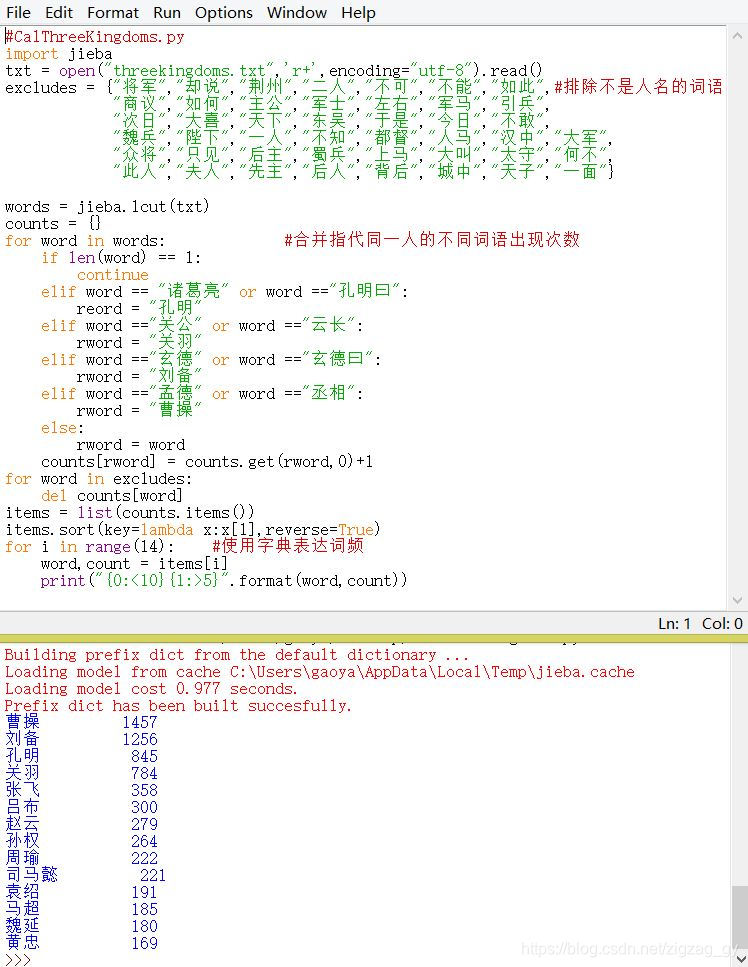
#CalThreeKingdoms.py
import jieba
txt = open("threekingdoms.txt",'r+',encoding="utf-8").read()
excludes = {"将军","却说","荆州","二人","不可","不能","如此",#排除不是人名的词语
"商议","如何","主公","军士","左右","军马","引兵",
"次日","大喜","天下","东吴","于是","今日","不敢",
"魏兵","陛下","一人","不知","都督","人马","汉中","大军",
"众将","只见","后主","蜀兵","上马","大叫","太守","何不",
"此人","夫人","先主","后人","背后","城中","天子","一面"}
words = jieba.lcut(txt)
counts = {}
for word in words: #合并指代同一人的不同词语出现次数
if len(word) == 1:
continue
elif word == "诸葛亮" or word =="孔明曰":
reord = "孔明"
elif word =="关公" or word =="云长":
rwor 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









