




【摘要】 本文通过三篇发表在CVPR 2019上的论文,对增量学习任务进行简单的介绍和总结。在此基础上,以个人的思考为基础,对这一研究领域的未来趋势进行预测。
一、背景介绍
目前,在满足一定条件的情况下,深度学习算法在图像分类任务上的精度已经能够达到人类的水平,甚至有时已经能够超过人类的识别精度。但是要达到这样的性能,通常需要使用大量的数据和计算资源来训练深度学习模型,并且目前主流的图像分类模型对于训练过程中没见过的类别,识别的时候完全无能为力。一种比较简单粗暴的解决方法是:对于当前模型识别不了的类别,收集大量的新数据,并和原来用于训练模型的数据合并到一起,对模型进行重新训练。但是以下的一些因素限制了这种做法在实际中的应用:
1. 当存储资源有限,不足以保存全部数据的时候,模型的识别精度无法保证;
2. 重新训练模型需要消耗大量的算力,会耗费大量的时间,同时也会付出大量的经济成本(如电费、服务器租用费等)。
为了解决这些问题,使得增加模型可识别的类别数量更容易一些,近年来学术界中出现了一些针对深度学习的“增量式学习”算法。这类算法有三点主要的假设:(1)不同类别的数据是分批次提供给算法模型进行学习的,如下图所示;(2)系统的存储空间有限,至多只能保存一部分历史数据,无法保存全部历史数据,这一点比较适用于手机、PC机等应用场景;(3)在每次提供的数据中,新类别的数据量比较充足。
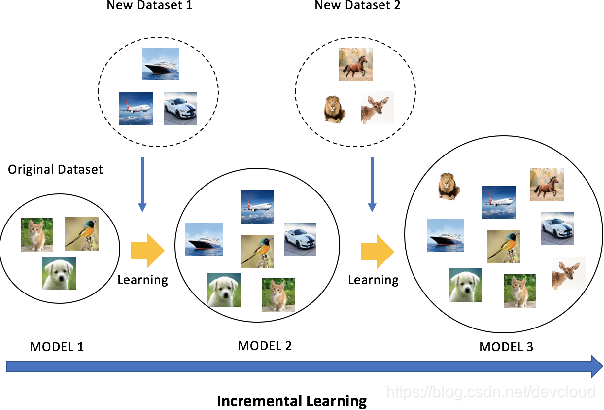
这类任务的难点主要体现在两方面:第一,由于每次对模型的参数进行更新时,只能用大量的新类别的样本和少量的旧类别的样本,因此会出现新旧类别数据量不均衡的问题,导致模型在更新完成后,更倾向于将样本预测为新增加的类别,如下图所示;第二,由于只能保存有限数量的旧类别样本,这些旧类别的样本不一定能够覆盖足够丰富的变化模式,因此随着模型的更新,一些罕见的变化模式可能会被遗忘,导致新的模型在遇到一些旧类别的样本的时候,不能正确地识别,这个现象被称作“灾难性遗忘”。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









