







 本文介绍Pandas数据分析工具包,基于numpy构建,适用于高效处理一维和二维数据。文章详细讲解了Series和DataFrame的创建及访问方法,包括使用列表、字典初始化Series,以及通过索引和位置访问元素。
本文介绍Pandas数据分析工具包,基于numpy构建,适用于高效处理一维和二维数据。文章详细讲解了Series和DataFrame的创建及访问方法,包括使用列表、字典初始化Series,以及通过索引和位置访问元素。
Pandas 数据分析工具包
基于numpy构建,主要应用与数据分析。其主要一维数组Series + 二维数组DataFrame,可直接读取数据并处理(高效简单),
支持各种分析算法
Series
Series是一个一维数组,同时特别的是,
- 其带有索引,所以可以是数字也可以是字符串等,若对索引不做特殊要求,按照0~(Series长度-1)排序
- 每个series还有自己的名字
一、两种初始化方式
首先导如pandas的库
import pandas as pd
- 使用列表创建
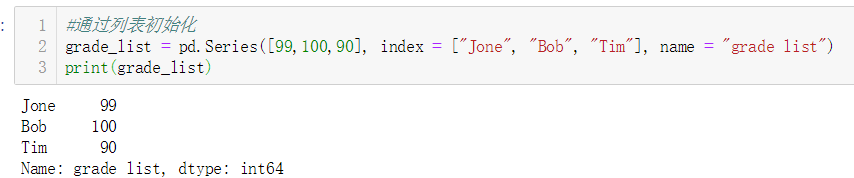
#通过列表初始化
grade_list = pd.Series([99,100,90], index = ["Jone", "Bob", "Tim"], name = "grade list")
print(grade_list)
结果
当不对索引进行设置时,结果如下
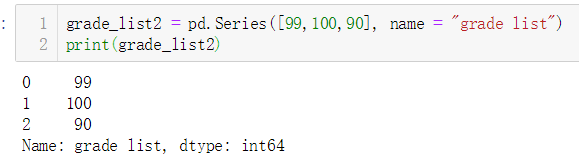
2.使用字典创建
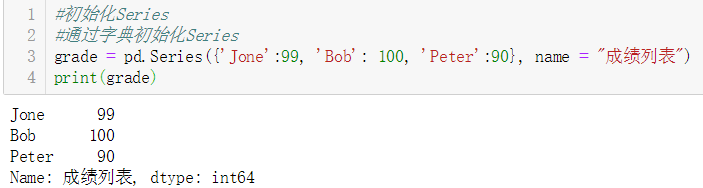
#通过字典初始化Series
grade = pd.Series({'Jone':99, 'Bob': 100, 'Peter':90}, name = "成绩列表")
print(grade)
结果:
- 访问Series中的元素
- 基于索引访问
print(grade.loc['Jone'],',',grade.loc['Peter'])
loc即location,用Series.loc()可以通过索引值进行访问
结果:

2.基于元素位置访问
(1)用Series.iloc()
官网的解释是Purely integer-location based indexing for selection by position.
print(grade.iloc[0],',',grade.iloc[2])
结果:

(2)通过[]方式进行访问
与numpy中访问元素方式的相同(这是我自己试的,不知道会有什么问题,欢迎批评指正)
print(grade[0],',',grade[1])
结果:
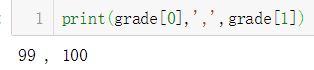
完整代码如下
import pandas as pd
#初始化Series
#通过字典初始化Series
grade = pd.Series({'Jone':99, 'Bob': 100, 'Peter':90}, name = "成绩列表")
print(grade)
#通过列表初始化
grade_list = pd.Series([99,100,90], index = ["Jone", "Bob", "Tim"], name = "grade list")
print(grade_list)
grade_list2 = pd.Series([99,100,90], name = "grade list")
print(grade_list2)
#Series访问
print(grade.loc['Jone'],',',grade.loc['Peter'])
print(grade.iloc[0],',',grade.iloc[2])
print(grade[0],',',grade[1])


















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











