







文件格式相关
PKL (Pickle)
- 优点:
- 支持序列化 Python 对象,包括模型、字典等。
- 可以保存复杂的数据结构。
- 适用场景:
- 保存训练好的模型(比如使用
scikit-learn或PyTorch)。 - 存储数据处理后的中间结果。
- 保存训练好的模型(比如使用
以前我保存过程文件的时候,通常都用CSV。然后发现CSV格式比较单一,而且文件比较大。所以直接弃用CSV,现在都是用PKL。不过他的缺点就是不安全
保存过程或者结果
TODO
怎么读取
我实际用到的例子
import inspect
import pickle
from datetime import datetime
import pickle
import pandas as pd
def preprocessing(args):
data = pickle.load(open(save_path_name, 'rb'))
return data
pickle.dump(data, open(save_path_name, 'wb'))
return data
HDF5 或者叫H5
这里Python和R都能读取
用RStudio查看内容,R
# 安装 BiocManager
install.packages("BiocManager")
# 更新 Bioconductor
BiocManager::install()
BiocManager::install("rhdf5")
install.packages("h5")
## 加载
library(rhdf5)
file_path <- "klein.h5"
my_dataset <- h5ls(file_path)
这个时候其实就能看到他的结构了,我粘贴个图片。
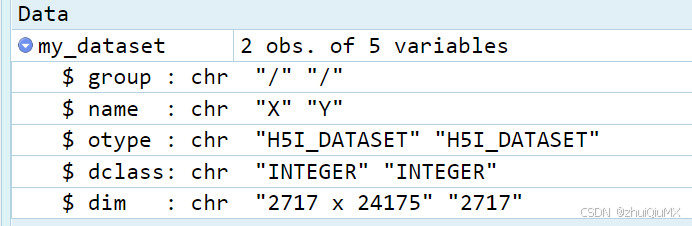 不过有时候想知道详细内容,可以继续用
不过有时候想知道详细内容,可以继续用
# 读取特定数据集
data <- h5read(file_path, my_dataset[1, "name"]) # 使用第一个数据集的名称
true_labs <- h5read(file_path, my_dataset[2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









