




 本文深入介绍了自注意力机制的原理及应用场景,包括其在处理长程依赖的优势与对局部上下文处理不足的问题。此外,还探讨了自注意力机制的多种改进方案,如增强局部上下文信息、降低序列长度依赖等,并分析了位置编码的不同实现方式。
本文深入介绍了自注意力机制的原理及应用场景,包括其在处理长程依赖的优势与对局部上下文处理不足的问题。此外,还探讨了自注意力机制的多种改进方案,如增强局部上下文信息、降低序列长度依赖等,并分析了位置编码的不同实现方式。
1. self-attention原理介绍
self-attention的概念起源自seq2seq机器翻译模型中的attention,基本思想都是计算不同部分的权重后进行加权求和,最后的效果是对attend的不同部分予以不同程度的关注,不同是seq2seq的attention是将decoder的一个状态去对比encoder的所有状态,而self-attention可以在encoder和decoder中均可使用,其计算的是同一集合内元素的相互关联。Sequence to Sequence (seq2seq) and Attention很好对二者都有非常好的介绍。
关于self-attention的介绍这里就不详细展开了,重点部分:
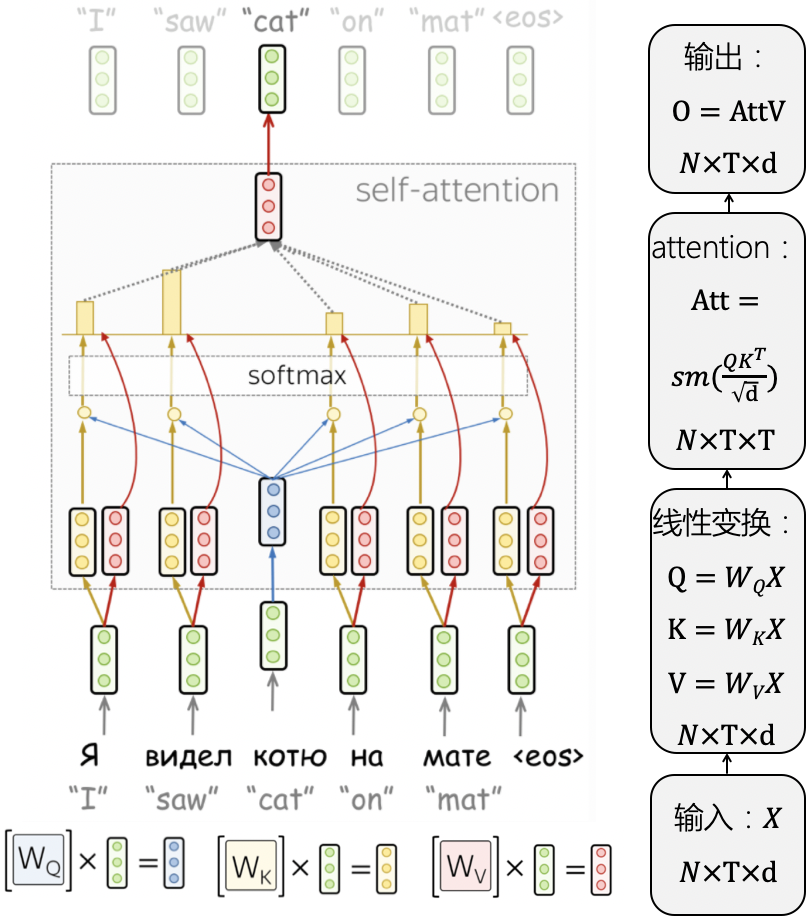
可以看到self-attention的基本计算基本都是矩阵计算,其最大的优点是不包含任何RNN、CNN结构,可以解决序列的长程依赖问题,同时矩阵计算可以因为并行化而非常快速。
其缺点也很明显:
1、由于没有任何部分处理序列信息,因此需要额外的positional encoding模块;
2、attention矩阵维度与输入序列长度
t
t
t是
O
(
t
2
)
O(t^2)
O(t2)关系,如果序列较长非常消耗内存,目前的transformer最多能处理512长度的序列;
3、虽然可以对长程依赖有效处理,但是对短程的上下文信息反而处理的不好,这会引出后续很多改进工作
推荐几篇非常好的介绍:
形象化解释:The Illustrated Transformer
哈佛代码介绍:The Annotated Transformer
论文解读:Attention Is All You Need - The Transformer
看到知乎上一个有意思的讨论:self-attention和全连接有什么区别?
全连接:可以看做特征映射,其权重表示的是特征的重要度
self-attention:并不是一种映射,其权重表示的是序列每个实体的重要度
2. self-attention改进方向
1)增强局部上下文信息
Modeling Localness for Self-Attention Networks
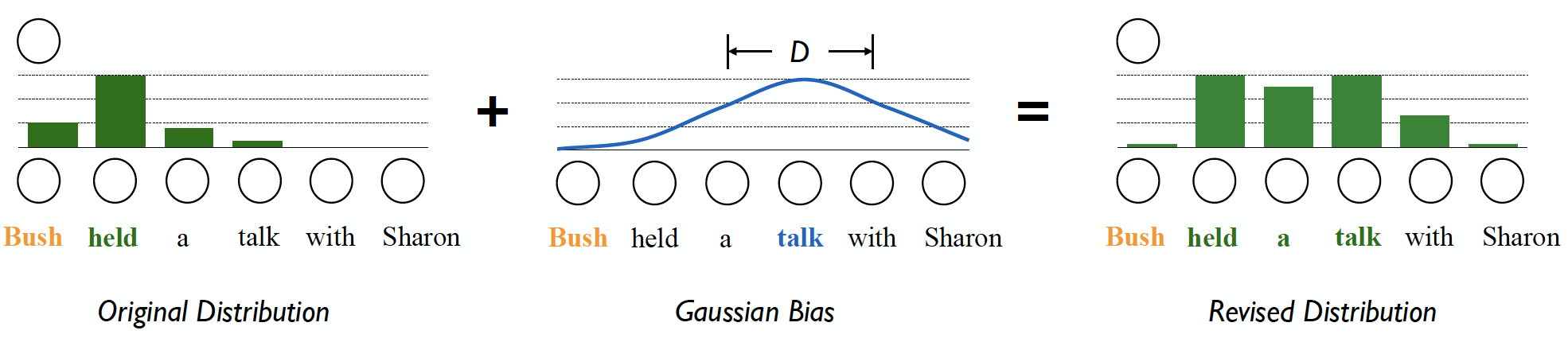
构建局部上下文信息:当“Bush”对齐到“held”时,我们希望自注意力模型能同时将更多注意力放到其邻近的词“a talk”上。这样,模型能捕获短语“held a talk”。本文将局部上下文建模设计为一种可学习的高斯偏差矩阵 G G G,其中心位置和宽度可以被学习,最终该偏差矩阵与原attention矩阵相加得到修正attention矩阵: A t t ^ = s o f t m a x ( A t t + G ) \hat{Att}=softmax(Att+G) Att^=softmax(Att+G)
Convolutional Self-Attention Networks
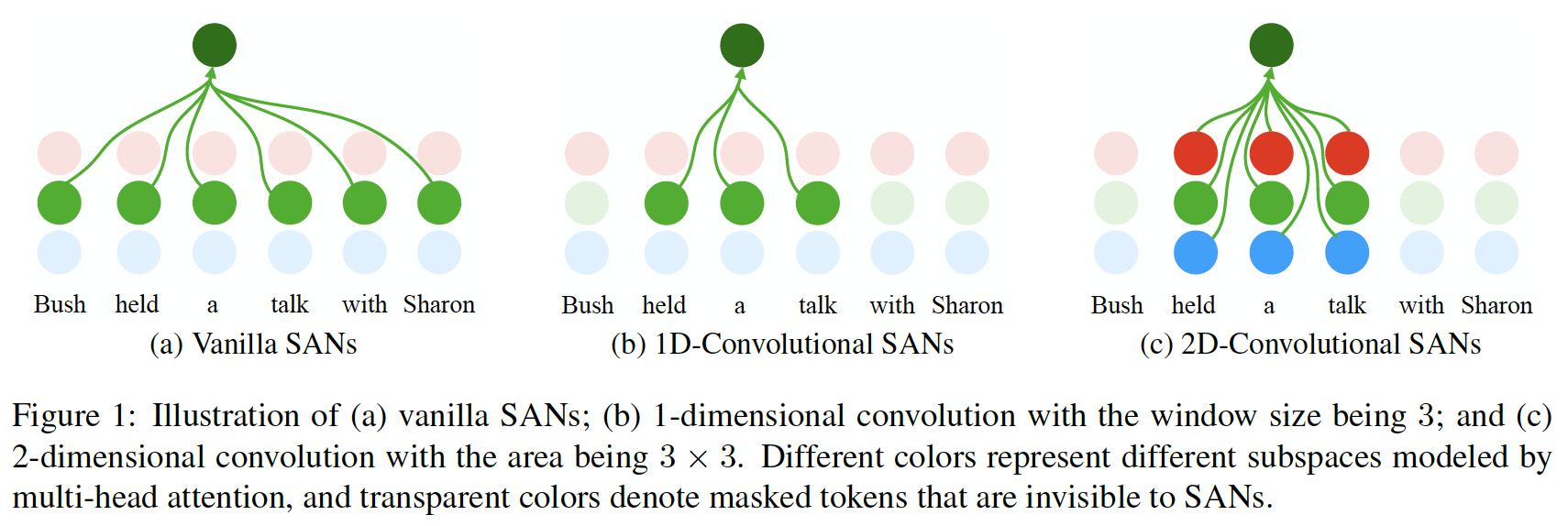
本文将局部上下文的拟合构建为类卷积形式的计算,其中1D卷积将原序列长度的attention限制在一个1D卷积核内,而2D卷积则是扩展了head维度后将attention限制在一个2D卷积核内,这种方法可以不增加模型参数
可以参考腾讯AI LAB论文解析
2)降低与序列长度的平方依赖处理更长序列
Longformer: The Long-Document Transformer
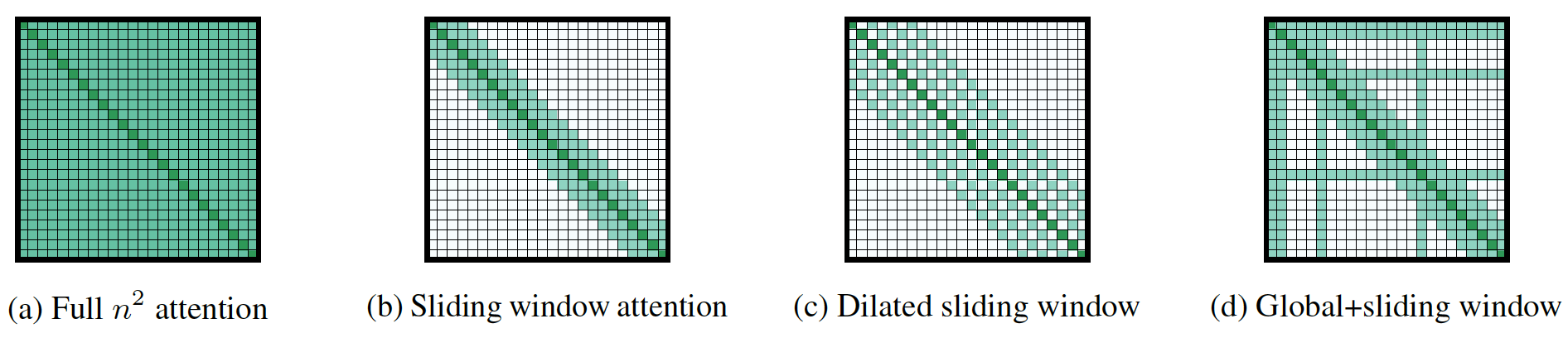
1、使用固定窗口的稀疏卷积,堆叠多层同样可以达到全注意力的感受野。同时,增加空洞可以扩大感受野
2、在不同的head中使用不同的窗口和空洞可以让不同的head学习不同大小的局部信息。在底层使用小窗口,而在顶层使用大窗口
3、在特定的token上使用全注意力,这些token可以根据不同任务选择出来的
Linformer: Self-Attention with Linear Complexity
1、论文核心贡献是发现self attention矩阵
P
P
P是低秩矩阵,从而可以通过SVD构建另一个维度小的低秩矩阵
P
ˉ
\bar{P}
Pˉ来近似,这个构建的矩阵仅选取前
k
k
k大的奇异值对应的奇异向量
2、对矩阵进行SVD仍然是耗时操作,因此可以进一步对
K
K
K和
V
V
V引入两个线性变换
E
,
F
:
k
×
T
E,F:k\times T
E,F:k×T来计算逼近
P
ˉ
\bar{P}
Pˉ
A
t
t
e
n
t
i
o
n
(
Q
W
Q
,
E
K
W
K
,
F
V
W
V
)
=
s
o
f
t
m
a
x
(
Q
W
Q
(
E
K
W
K
)
T
d
)
⏟
P
ˉ
:
T
×
k
⋅
F
V
W
V
⏟
k
×
d
Attention(QW_Q, EKW_K,FVW_V) = \underbrace{softmax(\frac{QW_Q(EKW_K)^T}{\sqrt{d}})}_{\bar{P}:T\times k}\cdot \underbrace{FVW_V}_{k\times d}
Attention(QWQ,EKWK,FVWV)=Pˉ:T×k
softmax(dQWQ(EKWK)T)⋅k×d
FVWV
这里时间和空间复杂度都变成了线性
O
(
T
k
)
O(Tk)
O(Tk),如果选择
k
≪
T
k\ll T
k≪T的话,时间和空间要求就会非常低
3、一些关于
E
,
F
E,F
E,F的空间映射技巧可以使用,比如在head里、layer间共享权重,或者在不同的head、layer使用不同的
k
k
k,甚至可以将简单的线性映射替换为pooling、conv等操作
Rethinking Attention with Performers(Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers)
由于self attention矩阵的维度是
O
(
t
2
)
O(t^2)
O(t2)的,因此如果不显式的计算就可以避免这个限制。这个想法很大胆但是实现起来确实不容易。文章通过正交随机投影和核方法将原最终输出的计算(1)变换为(2)
Y
=
D
−
1
A
V
,
A
=
e
x
p
(
Q
K
T
d
)
,
D
=
d
i
a
g
(
A
1
t
)
(
1
)
Y
=
D
^
−
1
(
Q
′
(
(
K
′
)
T
V
)
)
,
D
^
=
d
i
a
g
(
Q
′
(
(
K
′
)
T
1
t
)
)
,
Q
′
=
D
Q
ϕ
(
Q
T
)
T
,
K
′
=
D
K
ϕ
(
K
T
)
T
(
2
)
Y=D^{-1}AV, \quad A=exp(\frac{QK^T}{\sqrt{d}}),D=diag(A\bold{1}_t) \qquad(1)\\ Y=\hat{D}^{-1}(Q'((K')^TV)), \quad \hat{D}=diag(Q'((K')^T \bold{1}_t)), Q'=D_Q\phi(Q^T)^T,K'=D_K\phi(K^T)^T \qquad(2)
Y=D−1AV,A=exp(dQKT),D=diag(A1t)(1)Y=D^−1(Q′((K′)TV)),D^=diag(Q′((K′)T1t)),Q′=DQϕ(QT)T,K′=DKϕ(KT)T(2)
其中
D
Q
=
g
(
Q
i
T
)
,
D
K
=
g
(
K
i
T
)
D_Q=g(Q_i^T),D_K=g(K_i^T)
DQ=g(QiT),DK=g(KiT)分别是将行向量映射为标量的函数,
ϕ
(
X
)
\phi(X)
ϕ(X)通常为正交随机映射,是核函数的一部分。由于
(
K
′
)
T
V
∈
R
d
×
d
(K')^TV\in \R^{d\times d}
(K′)TV∈Rd×d,其中
d
d
d为特征维度常量,因此整体计算的复杂度为
O
(
t
d
2
)
=
O
(
t
)
O(td^2)=O(t)
O(td2)=O(t)。关于这篇论文的证明部分,可以参考Performer:用随机投影将Attention的复杂度线性化
最近google的一篇论文对此总结Efficient Transformers: A Survey
相关论文参考github论文集
3)attention的kernel技术
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
将原始的Scaled-Dot Attention
(
1
)
(1)
(1)输出结果的每一个row改写为
(
2
)
(2)
(2)
Y
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
)
V
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
V
(
1
)
Y
i
=
A
t
t
e
n
t
i
o
n
(
Q
i
,
K
)
V
=
∑
j
=
1
T
e
x
p
(
Q
i
⋅
K
j
d
)
V
j
∑
j
=
1
T
e
x
p
(
Q
i
⋅
K
j
d
)
=
∑
j
=
1
T
s
i
m
(
Q
i
,
K
j
)
V
j
∑
j
=
1
T
s
i
m
(
Q
i
,
K
j
)
(
2
)
Y = Attention(Q,K)V = softmax(\frac{QK^T}{\sqrt{d}})\boldsymbol{V}\qquad(1)\\ Y_i = Attention(Q_i,K)V = \frac{\sum_{j=1}^{T}exp(\frac{Q_i\cdot K_j}{\sqrt{d}})V_j}{\sum_{j=1}^{T}exp(\frac{Q_i\cdot K_j}{\sqrt{d}})} = \frac{\sum_{j=1}^{T}sim(Q_i,K_j)V_j}{\sum_{j=1}^{T}sim(Q_i,K_j)}\qquad(2)
Y=Attention(Q,K)V=softmax(dQKT)V(1)Yi=Attention(Qi,K)V=∑j=1Texp(dQi⋅Kj)∑j=1Texp(dQi⋅Kj)Vj=∑j=1Tsim(Qi,Kj)∑j=1Tsim(Qi,Kj)Vj(2)
只要定义相似度函数(核函数)
s
i
m
(
Q
i
,
K
j
)
≥
0
sim(Q_i,K_j) \ge 0
sim(Qi,Kj)≥0就可以定义各种类型的attention,原始的attention可以看做指数型,当然还可以有线性、多项式或RBF型的。论文为了实现线性化,将相似度函数通过特征映射函数表示为
s
i
m
(
Q
i
,
K
j
)
=
ϕ
(
Q
i
)
⋅
ϕ
(
K
j
)
sim(Q_i,K_j)=\phi(Q_i)\cdot\phi(K_j)
sim(Qi,Kj)=ϕ(Qi)⋅ϕ(Kj),通过乘法的交换律实现了
(
ϕ
(
Q
)
ϕ
(
K
)
T
)
V
=
ϕ
(
Q
)
(
ϕ
(
K
)
T
V
)
\left(\phi(Q)\phi(K)^T\right)V=\phi(Q)\left(\phi(K)^TV\right)
(ϕ(Q)ϕ(K)T)V=ϕ(Q)(ϕ(K)TV),其中选取
ϕ
(
x
)
=
e
l
u
(
x
)
+
1
\phi(x)=elu(x) + 1
ϕ(x)=elu(x)+1
关于这篇论文还可以参考线性Attention的探索:Attention必须有个Softmax吗?
Transformer dissection: An unified understanding for transformer’s attention via the lens of kernel
这篇论文从核函数的角度统一了多篇论文的改进,并把位置编码也融合进了核函数中。具体来说,原始Scaled-Dot Attention的分子部分可以表示成
k
e
x
p
(
f
q
+
t
q
,
f
k
+
t
k
)
k_{exp}(f_q+t_q, f_k+t_k)
kexp(fq+tq,fk+tk),这里
f
⋅
f_\cdot
f⋅表示输入的embedding,
t
⋅
t_\cdot
t⋅表示绝对位置编码,这表示位置编码是直接加入embedding后再计算
k
e
x
p
k_{exp}
kexp的,而这篇论文提出一种将位置编码独立计算kernel的计算方式:
k
F
(
f
q
,
f
k
)
⋅
k
T
(
t
q
,
t
k
)
,
w
h
e
r
e
k
F
(
f
q
,
f
k
)
=
e
x
p
(
f
q
W
F
(
f
k
W
F
)
T
d
)
,
k
T
(
t
q
,
t
k
)
=
e
x
p
(
t
q
W
T
(
t
k
W
T
)
T
d
)
k_{F}(f_q, f_k)\cdot k_{T}(t_q, t_k),\\where\quad k_{F}(f_q, f_k)=exp(\frac{f_qW_F(f_kW_F)^T}{\sqrt{d}}), k_{T}(t_q, t_k)=exp(\frac{t_qW_T(t_kW_T)^T}{\sqrt{d}})
kF(fq,fk)⋅kT(tq,tk),wherekF(fq,fk)=exp(dfqWF(fkWF)T),kT(tq,tk)=exp(dtqWT(tkWT)T)
这里位置编码仍然是sin/cos表示的绝对位置,而共享
Q
,
K
Q,K
Q,K的映射矩阵,这样使得attention矩阵最终是半正定的同时减少了参数(但据我实验效果会下降)。最后,论文表示只在
Q
,
K
Q,K
Q,K中使用位置编码,
V
V
V不使用任何形式的位置编码效果都会好一些。
4)位置编码
位置编码的应用方式有两种:将位置信息结合进输入序列中的方法称为绝对位置编码,而通过调整self-attention矩阵来计算不同位置上的注意力值的方法称为相对位置编码。还可以参考让研究人员绞尽脑汁的Transformer位置编码
方式一:绝对位置编码
Transformer原论文中就使用了固定的正余弦函数来表达序列token的绝对位置,它具有是固定的参数不随模型训练而改变,至于为何这种方式可以表达位置信息,可以参考这篇解释Transformer architecture: positional encoding。总结起来,一条经过embedding的隐层序列输入,设其token序列位置为
t
t
t,隐层维度位置为
i
i
i,那么正余弦位置编码
P
E
PE
PE的每个元素用公式表示如下:
P
E
t
(
i
)
=
f
(
t
)
(
i
)
:
=
{
sin
(
ω
k
.
t
)
,
if
i
=
2
k
cos
(
ω
k
.
t
)
,
if
i
=
2
k
+
1
,
where
ω
k
=
1
1000
0
2
k
/
d
PE_t^{(i)} = f(t)^{(i)} := \begin{cases} \sin({\omega_k} . t), & \text{if}\ i = 2k \\ \cos({\omega_k} . t), & \text{if}\ i = 2k + 1 \end{cases}, \text{where}\quad \omega_k = \frac{1}{10000^{2k / d}}
PEt(i)=f(t)(i):={sin(ωk.t),cos(ωk.t),if i=2kif i=2k+1,whereωk=100002k/d1
这样的位置编码具有如下性质
1)每一个位置
t
t
t的位置编码具有唯一性和确定性
2)不同长度的输入序列,任意两个位置的距离保持一致
3)用有限的数值可以表达无限长度的序列
其中第2步的证明如下,对于同频率的
ω
k
\omega_k
ωk的一对正余弦组合,总有和位置
t
t
t无关的旋转矩阵
M
M
M满足
[
sin
(
ω
k
.
(
t
+
ϕ
)
)
cos
(
ω
k
.
(
t
+
ϕ
)
)
]
=
[
cos
(
ω
k
.
ϕ
)
sin
(
ω
k
.
ϕ
)
−
sin
(
ω
k
.
ϕ
)
cos
(
ω
k
.
ϕ
)
]
[
sin
(
ω
k
.
t
)
cos
(
ω
k
.
t
)
]
=
M
[
sin
(
ω
k
.
t
)
cos
(
ω
k
.
t
)
]
\begin{bmatrix} \sin(\omega_k . (t + \phi)) \\ \cos(\omega_k . (t + \phi)) \end{bmatrix}= \begin{bmatrix} \cos(\omega_k .\phi) & \sin(\omega_k .\phi) \\ - \sin(\omega_k . \phi) & \cos(\omega_k .\phi) \end{bmatrix} \begin{bmatrix} \sin(\omega_k . t) \\ \cos(\omega_k . t) \end{bmatrix}= M\begin{bmatrix} \sin(\omega_k . t) \\ \cos(\omega_k . t) \end{bmatrix}
[sin(ωk.(t+ϕ))cos(ωk.(t+ϕ))]=[cos(ωk.ϕ)−sin(ωk.ϕ)sin(ωk.ϕ)cos(ωk.ϕ)][sin(ωk.t)cos(ωk.t)]=M[sin(ωk.t)cos(ωk.t)]
BERT则采用了一种更简单的可学习的位置编码,可以证明上述正余弦位置编码是可学习位置编码的一个显式解。
方式二:相对位置编码
相对位置编码考虑从绝对位置编码的计算过程来改造self-attention,绝对位置编码的计算如下
{
q
i
=
(
x
i
+
p
i
)
W
Q
k
j
=
(
x
j
+
p
j
)
W
K
v
j
=
(
x
j
+
p
j
)
W
V
a
i
,
j
=
s
o
f
t
m
a
x
(
q
i
k
j
⊤
)
o
i
=
∑
j
a
i
,
j
v
j
\left\{\begin{aligned} \boldsymbol{q}_i =&\, (\boldsymbol{x}_i + \boldsymbol{p}_i)\boldsymbol{W}_Q \\ \boldsymbol{k}_j =&\, (\boldsymbol{x}_j + \boldsymbol{p}_j)\boldsymbol{W}_K \\ \boldsymbol{v}_j =&\, (\boldsymbol{x}_j + \boldsymbol{p}_j)\boldsymbol{W}_V \\ a_{i,j} =&\, softmax\left(\boldsymbol{q}_i \boldsymbol{k}_j^{\top}\right)\\ \boldsymbol{o}_i =&\, \sum_j a_{i,j}\boldsymbol{v}_j \end{aligned}\right.
⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧qi=kj=vj=ai,j=oi=(xi+pi)WQ(xj+pj)WK(xj+pj)WVsoftmax(qikj⊤)j∑ai,jvj
Self-Attention with Relative Position Representations
Google的这篇论文首先展开
q
i
k
j
⊤
\boldsymbol{q}_i \boldsymbol{k}_j^{\top}
qikj⊤
q
i
k
j
⊤
=
(
x
i
+
p
i
)
W
Q
W
K
⊤
(
x
j
+
p
j
)
⊤
=
(
x
i
W
Q
+
p
i
W
Q
)
(
x
j
W
K
+
p
j
W
K
)
⊤
\boldsymbol{q}_i \boldsymbol{k}_j^{\top} = \left(\boldsymbol{x}_i + \boldsymbol{p}_i\right)\boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\left(\boldsymbol{x}_j + \boldsymbol{p}_j\right)^{\top} = \left(\boldsymbol{x}_i \boldsymbol{W}_Q + \boldsymbol{p}_i \boldsymbol{W}_Q\right)\left(\boldsymbol{x}_j\boldsymbol{W}_K + \boldsymbol{p}_j\boldsymbol{W}_K\right)^{\top}
qikj⊤=(xi+pi)WQWK⊤(xj+pj)⊤=(xiWQ+piWQ)(xjWK+pjWK)⊤
其中
p
i
W
Q
\boldsymbol{p}_i \boldsymbol{W}_Q
piWQ和
p
j
W
K
\boldsymbol{p}_j\boldsymbol{W}_K
pjWK都包含绝对位置信息,因此可以去掉
p
i
W
Q
\boldsymbol{p}_i \boldsymbol{W}_Q
piWQ,并将
p
j
W
K
\boldsymbol{p}_j\boldsymbol{W}_K
pjWK替换成仅依赖
i
−
j
i-j
i−j的相对距离矩阵
R
i
,
j
K
\boldsymbol{R}_{i,j}^K
Ri,jK,并同理在value计算中引入相对距离
R
i
,
j
V
\boldsymbol{R}_{i,j}^V
Ri,jV
q
i
k
j
⊤
=
x
i
W
Q
(
x
j
W
K
+
R
i
,
j
K
)
⊤
v
j
=
x
j
W
V
+
R
i
,
j
V
\begin{aligned} \boldsymbol{q}_i \boldsymbol{k}_j^{\top} & = \boldsymbol{x}_i \boldsymbol{W}_Q\left(\boldsymbol{x}_j\boldsymbol{W}_K + \color{green}{\boldsymbol{R}_{i,j}^K}\right)^{\top}\\ \boldsymbol{v}_j &= \boldsymbol{x}_j\boldsymbol{W}_V + \color{green}{\boldsymbol{R}_{i,j}^{V}} \end{aligned}
qikj⊤vj=xiWQ(xjWK+Ri,jK)⊤=xjWV+Ri,jV
在最后的
R
i
,
j
K
\boldsymbol{R}_{i,j}^K
Ri,jK和
R
i
,
j
V
\boldsymbol{R}_{i,j}^V
Ri,jV的计算中进行截断,表示过远的相对距离可以不用考虑了,并且它们的取值既可以如同transformer选择固定的正余弦编码,也可以如同BERT一样选择可学习编码。
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
在Google工作的基础上进一步展开
q
i
k
j
⊤
\boldsymbol{q}_i \boldsymbol{k}_j^{\top}
qikj⊤,直接将
p
j
\boldsymbol{p}_j
pj替换为正余弦相对位置向量
R
i
−
j
\boldsymbol{R}_{i-j}
Ri−j,而将后两项
p
i
W
Q
\boldsymbol{p}_i \boldsymbol{W}_Q
piWQ分别替换为两个可学习的位置编码
u
\boldsymbol{u}
u和
v
\boldsymbol{v}
v,并将
W
K
\boldsymbol{W}_K
WK拆分成
W
K
,
p
\boldsymbol{W}_{K,p}
WK,p和
W
K
,
R
\boldsymbol{W}_{K,R}
WK,R,原因是这两项分别是位置-key和位置-位置交叉项,对同一个
q
i
\boldsymbol{q}_i
qi都有相同的位置,因此只需要分别学习基于位置的key表示和纯位置表示即可。对于
v
j
\boldsymbol{v}_j
vj则选择直接去掉位置编码效果更好。
q
i
k
j
⊤
=
x
i
W
Q
W
K
⊤
x
j
⊤
+
x
i
W
Q
W
K
⊤
p
j
⊤
+
p
i
W
Q
W
K
⊤
x
j
⊤
+
p
i
W
Q
W
K
⊤
p
j
⊤
=
x
i
W
Q
W
K
⊤
x
j
⊤
+
x
i
W
Q
W
K
⊤
R
i
−
j
⊤
+
u
W
K
,
p
⊤
x
j
⊤
+
v
W
K
,
R
⊤
R
i
−
j
⊤
\begin{aligned} \boldsymbol{q}_i \boldsymbol{k}_j^{\top} & = \boldsymbol{x}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\boldsymbol{x}_j^{\top} + \boldsymbol{x}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\boldsymbol{p}_j^{\top} + \boldsymbol{p}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\boldsymbol{x}_j^{\top} + \boldsymbol{p}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\boldsymbol{p}_j^{\top}\\ &=\boldsymbol{x}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\boldsymbol{x}_j^{\top} + \boldsymbol{x}_i \boldsymbol{W}_Q \boldsymbol{W}_K^{\top}\color{green}{\boldsymbol{R}_{i-j}^{\top}} \color{black}+ \color{red}{\boldsymbol{u}}\color{blue}{\boldsymbol{W}_{K,p}^{\top}}\color{black}\boldsymbol{x}_j^{\top} + \color{red}{\boldsymbol{v}} \color{blue}\boldsymbol{W}_{K,R}^{\top}\color{green}{\boldsymbol{R}_{i-j}^{\top}} \end{aligned}
qikj⊤=xiWQWK⊤xj⊤+xiWQWK⊤pj⊤+piWQWK⊤xj⊤+piWQWK⊤pj⊤=xiWQWK⊤xj⊤+xiWQWK⊤Ri−j⊤+uWK,p⊤xj⊤+vWK,R⊤Ri−j⊤
3. self-attention在其他领域尝试
虽然self-attention提出时主要用在序列模型中,但是其中包含的全局依赖思想可以轻松应用在图像、视频中,那么RNN/CNN所能够发挥的领域都有它的一席之地,甚至有替代传统模型的趋势,近期优秀的self-attention跨界表现主要有以下方面:
1)图像视觉领域
2)时序信号领域
近期的AAAI 2021最佳论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
另外还可参考self-attention序列数据分析attention-for-time-series-classification-and-forecasting

















 956
956




 到【灌水乐园】发言
到【灌水乐园】发言







