









对于runtimeAPI而言,与driver最大的区别就是懒加载。
就是第一个runtimeApi调用的时候,会进行cuInit初始化,避免驱动api的初始化窘境。
第一个需要context的Api调用的时候,也会进行调用cuDevicePrimaryCtxRetain。
Cuda Runtime Api是封装了Driver Api的更高级别的,更友好的Api。
// CUDA运行时头文件
#include <cuda_runtime.h>
// CUDA驱动头文件
#include <cuda.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
CUcontext context = nullptr;
cuCtxGetCurrent(&context);//因为没创建,没有create
printf("Current context = %p,当前无context\n", context);
// cuda runtime是以cuda为基准开发的运行时库
// cuda runtime所使用的CUcontext是基于cuDevicePrimaryCtxRetain函数获取的
// 即,cuDevicePrimaryCtxRetain会为每个设备关联一个context,通过cuDevicePrimaryCtxRetain函数可以获取到
// 而context初始化的时机是懒加载模式,即当你调用一个runtime api时,会触发创建动作
// 也因此,避免了cu驱动级别的init和destroy操作。使得api的调用更加容易
int device_count = 0;
//触发cuInit
checkRuntime(cudaGetDeviceCount(&device_count));//获取有多少显卡,这里显示1是有一个
printf("device_count = %d\n", device_count);
// 取而代之,是使用setdevice来控制当前上下文,当你要使用不同设备时
// 使用不同的device id
// 注意,context是线程内作用的,其他线程不相关的, 一个线程一个context stack
int device_id = 0;
//触发cuDevicePrimaryCtxRetain
printf("set current device to : %d,这个API依赖CUcontext,触发创建并设置\n", device_id);
checkRuntime(cudaSetDevice(device_id));
// 注意,是由于set device函数是“第一个执行的需要context的函数”,所以他会执行cuDevicePrimaryCtxRetain
// 并设置当前context,这一切都是默认执行的。注意:cudaGetDeviceCount是一个不需要context的函数
// 你可以认为绝大部分runtime api都是需要context的,所以第一个执行的cuda runtime函数,会创建context并设置上下文
cuCtxGetCurrent(&context);
printf("SetDevice after, Current context = %p,获取当前context\n", context);
int current_device = 0;
checkRuntime(cudaGetDevice(¤t_device));
printf("current_device = %d\n", current_device);
return 0;
}
首先当前无context是因为在最初没有创建,根本就没有context。
而后来的cudaGetDeviceCount就相当于触发cuInit,cudaSetDevice(device_id)就相当于触发cuDevicePrimaryCtxRetain。
所以后来才可以获得到Current context的值。
Memory
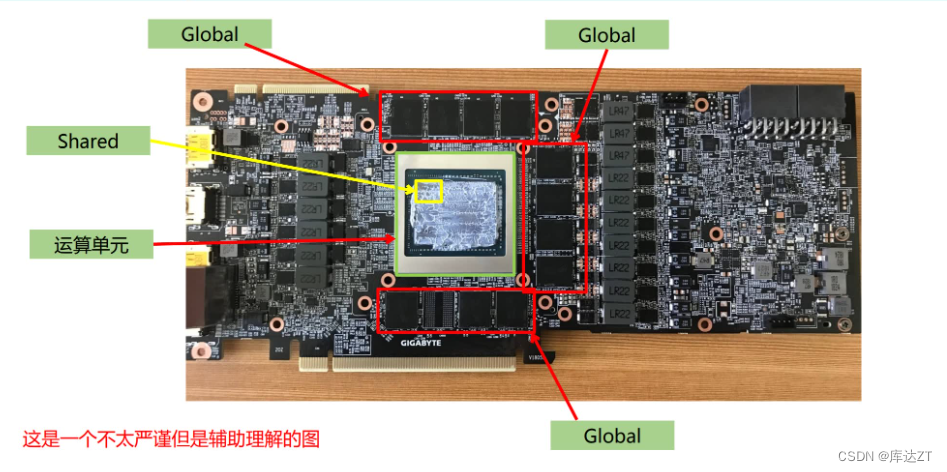
所以一般称shared是片上内存
作为host memory 内存条而言 其实分为两大类(仅仅作为逻辑区分,实际上物理层面是一个东西)
1、pageable memory 可分页内存
2、page lock memory 页锁定内存
可以理解为page lock memory 是VIP 房间,只留给你一个人住。而page lock memory是普通房间,当所需要存储的东西过多时,就会将你的普通房间空出来,给其他数据住,而作为被请出来的我们,自然就跑到硬盘上了。这种情况就会造成房间很多的假象。但实际上性能降低了。
所以pinned memory具有锁定的特性,相当于每一次去房间都能找到你。
基于前面的理解,我们总结如下:
- pinned memory具有锁定特性,是稳定不会被交换的(这很重要,相当于每次去这个房间都一定能找到你)
- pageable memory没有锁定特性,对于第三方设备(比如GPU),去访问时,因为无法感知内存是否被交换,可能得不到正确的数据(每次去房间找,说不准你的房间被人交换了)
- pageable memory的性能比pinned memory差,很可能降低你程序的优先级然后把内存交换给别人用
- pageable memory策略能使用内存假象,实际8GB但是可以使用15GB,提高程序运行数量(不是速度)
- pinned memory太多,会导致操作系统整体性能降低(程序运行数量减少),8GB就只能用8GB。注意不是你的应用程序性能降低,这一点一般都是废话,不用当回事
- GPU可以直接访问pinned memory而不能访问pageable memory(因为第二条)
- 对于页(Page)型可分页内存(Pageable Memory)而言,在将数据发送给硬盘后,当当前数据调用结束并不会自动将被换出的数据调回内存。
- 页型可分页内存是一种内存管理机制,它允许操作系统将不经常使用或暂时不需要的页面移出物理内存,并将其交换到磁盘上作为虚拟内存的一部分。这样可以释放物理内存供其他进程或数据使用,同时保留只有在需要时才被换入内存。
- 当某个数据页被换出到磁盘上时,它所占用的物理内存空间就被释放出来,可以用于其他目的。而当该数据再次被需要时,操作系统会从磁盘上将其换入内存,以供程序访问。这个过程通常涉及磁盘I/O操作,因此与直接在内存中访问数据相比,其延迟较高。
- 需要注意的是,具体的页面置换策略由操作系统决定。不同的操作系统可能采用不同的算法和策略来管理分页内存。常见的页面置换算法包括最近最久未使用(LRU)、先进先出(FIFO)等。
- 因此,除非被换出的数据再次被访问到,否则操作系统不会主动将其调回到内存中。如果您需要在数据被换出后再次访问该数据,应确保通过适当的方式触发对数据的访问,以便操作系统将其从磁盘交换回内存。
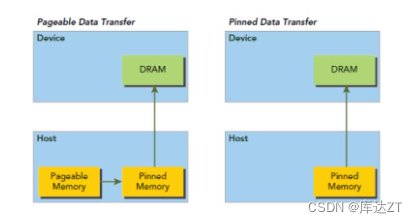
对于数据的传输,一般的pageable是先传输给pinned再给device
而对于已经pinned可以直接传输。就会很省事。
// CUDA运行时头文件
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
//global memory
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
//pageable memory
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
//pinned memory
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); // 把device的值传递给pinned memory
printf("%f\n", memory_page_locked[2]);//520.250000 打印出来的pinned和pageable一样
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
return 0;
}Memory总结如下:
- GPU可以直接访问pinned memory,称之为(DMA Direct Memory Access)
- 对于GPU访问而言,距离计算单元越近,效率越高,所以PinnedMemory<GlobalMemory<SharedMemory
- 代码中,由new、malloc分配的,是pageable memory,由cudaMallocHost分配的是PinnedMemory,由cudaMalloc分配的是GlobalMemory
- 尽量多用PinnedMemory储存host数据,或者显式处理Host到Device时,用PinnedMemory做缓存,都是提高性能的关键

















 5910
5910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









