 Boston housing 数据的线性模型分析
Boston housing 数据的线性模型分析





 这篇博客通过对Boston housing数据集的分析,探讨了不同因素如何影响特定城市房屋价格。作者将506条数据划分为训练集和测试集,使用线性模型进行训练,以预测房价并评估模型性能。通过Matlab绘制参数与房价的关系图,显示房间数与房价存在线性关系。
这篇博客通过对Boston housing数据集的分析,探讨了不同因素如何影响特定城市房屋价格。作者将506条数据划分为训练集和测试集,使用线性模型进行训练,以预测房价并评估模型性能。通过Matlab绘制参数与房价的关系图,显示房间数与房价存在线性关系。
问题分析
Boston housing已有数据列表为506*14的数据表格,具体数据对照表如图所示
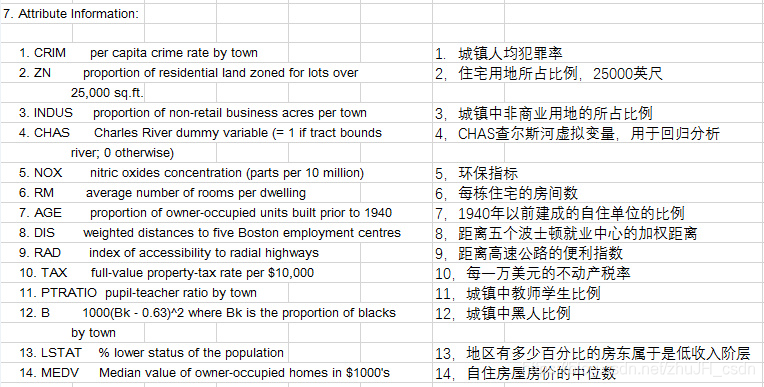
本次学习目的,就是基于已有数据分析对于特定文化下特定城市的房屋价格影响,并通过linear model的方法,完成模型训练,预测房屋价格,并表示出这个模型的好坏。
为了更好的进行训练与检测,这里把506条数据分为两组,一组404条为training组,一组102条为test组。
初步分析所有数据,调用matlab对各个参数与房屋价格进行画图分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
from sklearn.datasets import load_boston
boston = load_boston()
bos = pd.DataFrame(boston.data)
bos.columns = boston.feature_names
import matplotlib.font_manager as fm
myfont = fm.FontProperties(fname='C:/Windows/Fonts/msyh.ttc')
plt.scatter(bos.RM, bos.PRICE)
plt.xlabel(u'住宅平均房间数', fontproperties=myfont)
plt.ylabel(u'房屋价格', fontproperties=myfont)
plt.title(u'RM与PRICE的关系', fontproperties=myfont)
plt.show 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









