







论文题目(Title):Aspect Feature Distillation and Enhancement Network for Aspect-based Sentiment Analysis
研究问题(Question):方面级情感分析(特征提取、增强)
研究动机(Motivation):之前的工作主要是两类:
1)利用不同的注意力:跟所有的方面都计算分数,部分跟aspect无关,因此引入了噪声;
2)利用交叉熵损失函数进行微调:这种方法很难捕捉到正确的标签,以及正确标签与不正确标签之间的潜在信息,从而导致学到的方面特征在同一类别中表现的十分松散,在不同类别中边界不明确。
主要贡献(Contribution):
1)用到了一些对抗的思想来蒸馏特征,将特征分成aspect-related和aspect-unrelated两部分
2)模型结构中有一部分是有监督对比学习,它拉近了相同类内距离,同时拉远了不同类间距离
研究思路(Idea):
首先提出了一个双特征提取模块,通过注意机制和图卷积网络提取方面相关和方面不相关的特征。
然后,为了消除方面无关词的干扰,作者设计了一个新的方面特征蒸馏模块,该模块包含一个通过对抗训练学习方面无关上下文特征的梯度反向层和一个方面特定的正交投影层,进一步将方面相关特征投影到方面无关特征的正交空间。
最后,提出了一个方面特征增强模块,该模块利用监督对比学习来捕获相同情感标签之间和不同情感标签之间的隐含信息。
研究方法(Method):
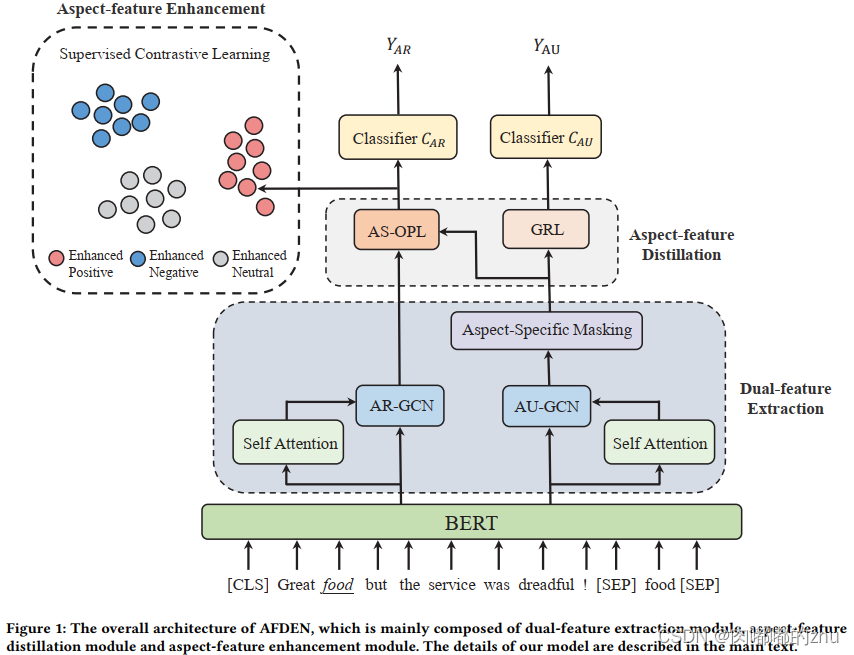
模型主要分为5部分:
1)embedding layer:用bert,输入形式:[CLS] sentence [SEP] aspect [SEP]
2)Dual-feature Extraction:
这一模块被分成了两部分,一部分用来得到aspect-related,另一部分用来得到aspect-unrelated,两部分的结构相同,但是不共享参数
首先都经过一个self-attention,之后将得到的注意力分数矩阵作为图神经网络的邻接矩阵,bert得到的表示作为节点表示,进一步丰富向量表征。
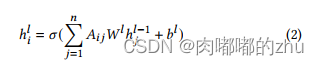
经由AR-GCN输出的向量记为 hAR ,AU-GCN输出的向量记为 hAU
对 hAU 又做了式(3)展示的aspect-specific Masking,即只保留aspect的表示,其他的表示置0
![]()
3)Aspect-feature Distillation:(划分表征)
第一步,Gradient Reverse Layer梯度反转层
这一层经常用在对抗学习中,比如forward是A—>GRL—>B,反向传播时B的梯度为c,那么a的梯度是-lamdac。这样GRL前后的网络训练目标刚好相反,就实现了对抗。GRL的forward和backward过程分别展示在式(4)和式(5)

第二步,Aspect-specific Orthographic Projection Layer
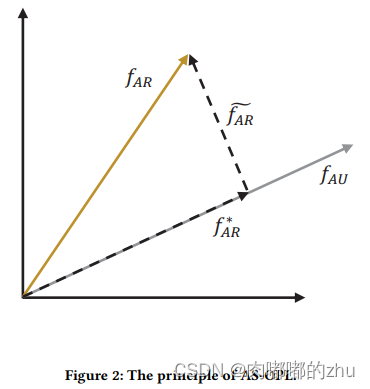
这个模块就在把aspect-related和aspect-unrelated信息分开了,用到了简单的数学变换,变换的思想如Figure 2所示(Figure 2是以2维向量为例,词向量一般是更高维的向量)。为了得到更干净的aspect-related表示,这种映射分成了两步
step1: 将aspect-related表征映射到aspect-unrelated空间上,这一步得到的是aspect-related中所有unrelated的表征
step2: 将aspect-related表征映射到第一步所得表征的正交空间中,这一步就拿到了aspect-related中更pure的related表征 fAR~
4)分类
对应两个表示,分类器也有两个,一个将 fAU~ 作为输入,一个将 fAR~ 作为输入
5)Aspect-feature Enhancement
这一块用到了自监督对比学习,用图像领域的小例子简单说明一下自监督对比学习和自监督的区别:
自监督的方法认为同源的图片互为正例,认为不同源的图片是负例,这种方法会拉近同源图片之间的距离,会拉远非同源图片之间的距离。但是对于非同源,但是同label的图片,这种方法是无法处理的,比如两个都是dog标签的图片,他们的距离也会被拉远,这样是无法适配下游任务的。有监督对比学习不但拉近同源例子之间的距离,还拉进相同label例子之间的距离。
那在这里用该方法是想在每一个batch运算的时候拉近同为positive(negative/neutral)label的表示,即类内聚集,类间分散。
6)损失函数
A.AR classifier的交叉熵
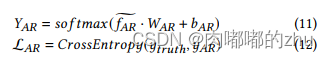
B.AU classifier的交叉熵
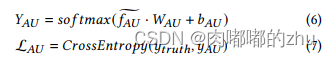
C.自监督对比学习损失
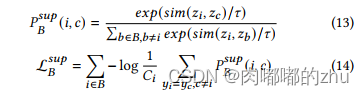
研究过程(Process):
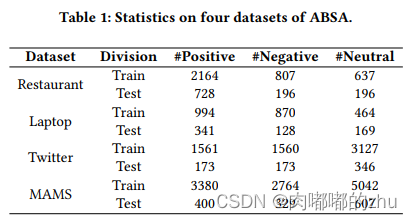
1.数据集(Dataset)
2.评估指标(Evaluation):准确率,平均F1
3.实验结果(Result)
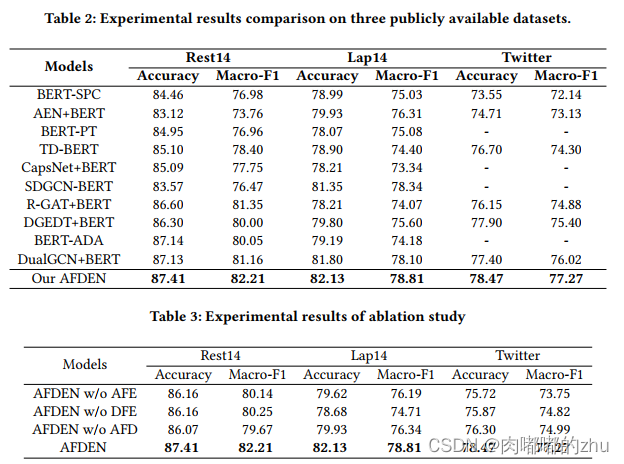
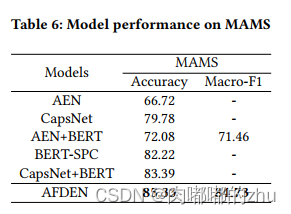
总结(Conclusion):在基准数据集、MAMS数据集和ARTS数据集表明,AFDEN模型比基线模型具有更好的性能和鲁棒性。

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









