







本文将用std::atomic_flag实现一个自旋锁并对其在指令层面进行剖析。
自旋锁相比于互斥锁,不会引起线程的上下文切换,因为线程在获取锁时会一直处于忙等待状态(自旋),直到获取到锁为止。所以在一些锁短期占用和低竞争情况下且对性能(主要指时延)要求较高的场景,自旋锁比较合适。
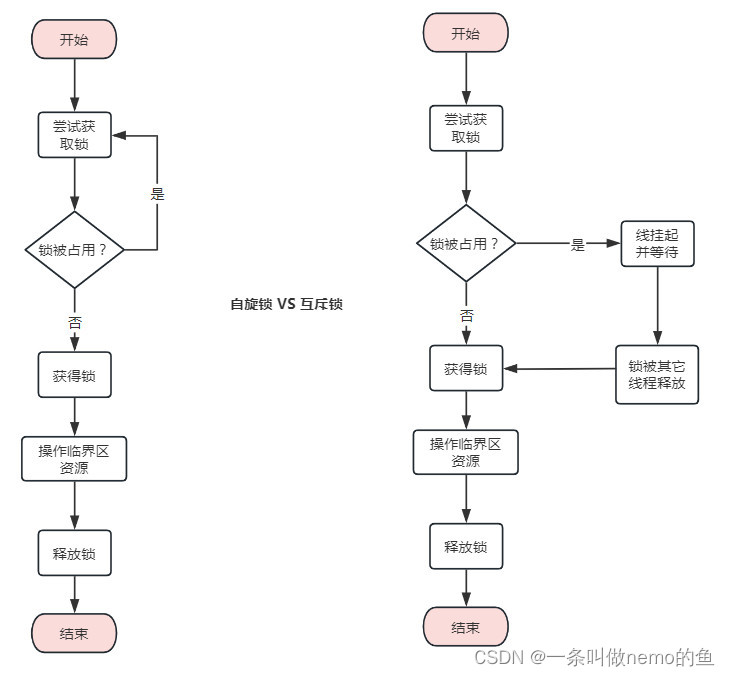
以下是基于C++11版本的实现,非常简洁。
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void spinlock_lock()
{
while (lock.test_and_set(std::memory_order_acquire));
}
void spinlock_unlock()
{
lock.clear(std::memory_order_release);
}
逐行解释:
std::atomic_flag lock = ATOMIC_FLAG_INIT;
std::atomic_flag是一个原子类型,它代表一个布尔标志。这一类型的对象可以是两种状态之一:设置或清除。必须用ATOMIC_FLAG_INIT初始化,这会将该标志初始化为清除状态。
void spinlock_lock()
{
while (lock.test_and_set(std::memory_order_acquire));
}
test_and_set函数:原子地设置 lock 的状态,并返回之前的状态。如果之前的状态为清除状态(即未被锁定),则返回 false,表示获取锁成功,并同时将lock的状态设置为锁定状态;如果之前的状态为锁定状态,则返回 true,表示锁已经被占用。
std::memory_order_acquire : 指定了获取锁时的内存顺序,确保读取操作在后续的读取操作或者之前的写入操作之后不会被重排。这确保了在获取锁的过程中: 1 此次读取操作在后续的读取操作之前执行。2 此次读取操作在之前的写入操作之后执行。确保这两点能保证每次都能读到最新的值(如果在读之前正好有线程写了,那么读到的值是从内存中load进来的最新值),并且优先于其它线程读(如果在读之后,正好其它线程也要开始读,那么当前线程先读)。
对应的汇编(x86)如下:
0000000000400f58 <_Z13spinlock_lockv>:
400f58: 55 push %rbp
400f59: 48 89 e5 mov %rsp,%rbp
400f5c: c7 45 fc 02 00 00 00 movl $0x2,-0x4(%rbp), ----> *(rbp -0x4) = 0x2
400f63: ba a0 71 60 00 mov $0x6071a0,%edx ----> edx = 0x6071a0, 0x6071a0为lock的地址
400f68: b8 01 00 00 00 mov $0x1,%eax ----> eax = 0x1
400f6d: 86 02 xchg %al,(%rdx) ----> al = *rdx, *rdx = al, xchg为原子交换操作,将al与*(rdx)值互换
400f6f: 84 c0 test %al,%al ----> if al == 0, 结果为1. 否则结果为0
400f71: 74 02 je 400f75 <_Z13spinlock_lockv+0x1d> ---->如果400f6f这条指令结果为1,则执行地址为0x400f75的指令,即成功获取锁
400f73: eb e7 jmp 400f5c <_Z13spinlock_lockv+0x4> ---->如果400f6f这条指令结果为0,则执行地址为0x400f5c的指令, 即获取锁失败,重新开始判断锁的状态
400f75: 90 nop
400f76: 5d pop %rbp
400f77: c3 retq为什么必须指定内存顺序?
编译器和现代处理器在优化代码执行时会进行指令重排,以提高性能。在多线程编程中,这种重排可能导致意外的行为或数据不一致性。内存顺序通过指定内存操作的顺序性,告知编译器和处理器如何对待原子操作,避免不必要的指令重排。
void spinlock_unlock()
{
lock.clear(std::memory_order_release);
}
clear函数:清除锁的锁定状态。
std::memory_order_release:指定了释放锁时的内存顺序,确保写入操作在后续的写入操作或者之前的读取操作之前不会被重排。这确保了在获取锁的过程中,1 此次写操作在之前的读操作之后执行。2 此次写操作在之后的写操作之前执行。确保这两点能保证其它线程不会提前读到锁的状态为清除状态(当前写入操作优先于此指令之前的读指令执行了); 后续写入操作会基于最新的值(当前写入操作执行完,并且新值对所有其它线程可见)。
对应的汇编(x86)如下:
0000000000400f78 <_Z15spinlock_unlockv>:
400f78: 55 push %rbp
400f79: 48 89 e5 mov %rsp,%rbp
400f7c: 48 83 ec 10 sub $0x10,%rsp --->rsp = rsp - 0x10
400f80: c7 45 f8 03 00 00 00 movl $0x3,-0x8(%rbp) --->*(rbp - 0x8) = 0x3
400f87: 8b 45 f8 mov -0x8(%rbp),%eax --->eax = *(rbp - 0x8) = 0x3
400f8a: be ff ff 00 00 mov $0xffff,%esi ---> esi = 0xffff
400f8f: 89 c7 mov %eax,%edi ---> edi = eax = 0x3
400f91: e8 31 03 00 00 callq 4012c7 <_ZStanSt12memory_orderSt23__memory_order_modifier> //调用_ZStanSt12memory_orderSt23__memory_order_modifier函数
400f96: 89 45 fc mov %eax,-0x4(%rbp) ----> *(rbp - 0x4) = eax = 0x3
400f99: b8 a0 71 60 00 mov $0x6071a0,%eax ----> eax = 0x6071a0, 0x6071a0为lock的地址
400f9e: ba 00 00 00 00 mov $0x0,%edx ----> edx = 0
400fa3: 88 10 mov %dl,(%rax) ----> *rax = dl = 0,即将lock设置为0,释放锁
400fa5: 0f ae f0 mfence ----> 内存屏障指令,强制所有前面的内存访问指令完成(即锁成功释放),然后才能继续执行后面的内存访问指令
400fa8: 90 nop
400fa9: c9 leaveq
400faa: c3 retq
00000000004012c7 <_ZStanSt12memory_orderSt23__memory_order_modifier>
4012c7: 55 push %rbp
4012c8: 48 89 e5 mov %rsp,%rbp
4012cb: 89 7d fc mov %edi,-0x4(%rbp) --->*(rbp - 0x4) = edi = 0x3
4012ce: 89 75 f8 mov %esi,-0x8(%rbp) --->*(rbp - 0x8) = esi = 0xffff
4012d1: 8b 55 fc mov -0x4(%rbp),%edx --->edx = *(rbp - 0x4) = 0x3
4012d4: 8b 45 f8 mov -0x8(%rbp),%eax --->eax = *(rbp - 0x8) = 0xfffff
4012d7: 21 d0 and %edx,%eax ---->eax = 0x3
4012d9: 5d pop %rbp
4012da: c3 retq
4012db: 90 nop

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











