






LangChain 就像是一个积木建筑师,可以帮你搭建与大语言模型交互的应用而不必被外部服务束缚。
基本安装
环境准备
# 准备Python虚拟环境
python -m venv langchain-env
source langchain-env/bin/activate # Linux/Mac
# 或者在Windows上
# langchain-env\Scripts\activate
# 安装LangChain核心包
pip install langchain
# 安装本地模型支持
pip install llama-cpp-python
# 安装向量数据库
pip install chromadb
模型获取
# 下载开源模型
# 确保目录存在
import os
os.makedirs("models", exist_ok=True)
# 使用wget或curl下载(Linux/Mac)
# !wget https://huggingface.co/TheBloke/Llama-2-7B-GGUF/resolve/main/llama-2-7b.Q4_K_M.gguf -O models/llama-2-7b.gguf
# 使用requests下载(跨平台)
import requests
def 下载模型(url, 保存路径):
response = requests.get(url, stream=True)
total_size = int(response.headers.get('content-length', 0))
with open(保存路径, 'wb') as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"模型已下载到: {保存路径}")
本地模型加载
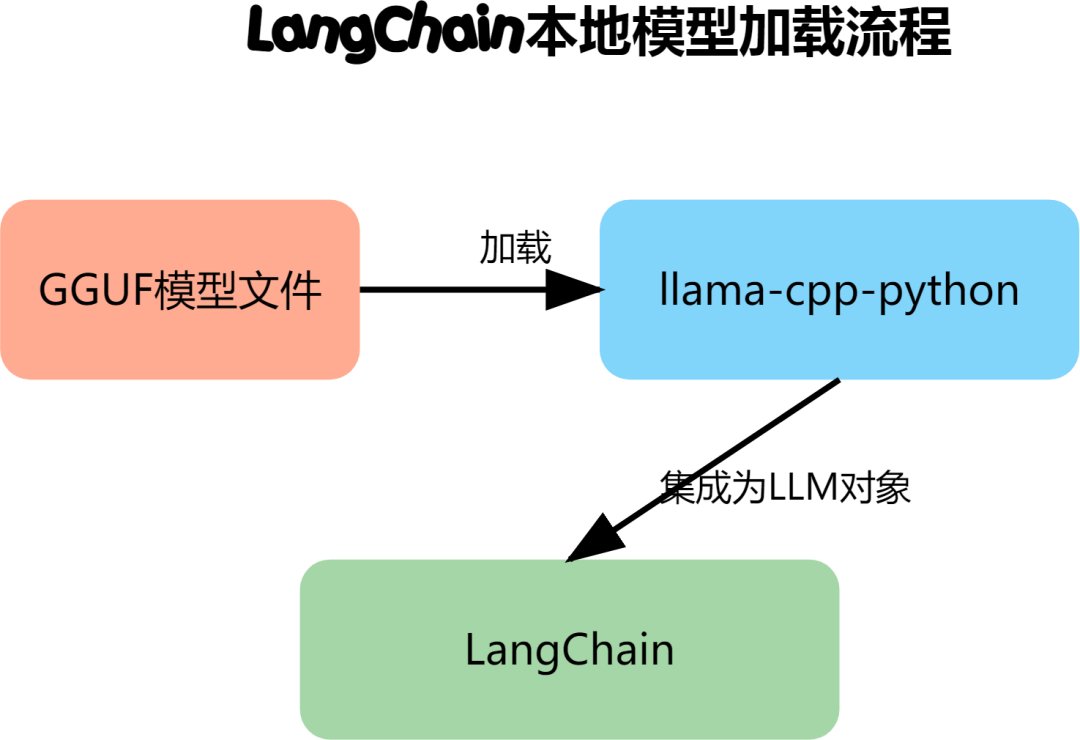
创建LLM对象
# 使用llama-cpp加载本地模型
from langchain.llms import LlamaCpp
# 创建本地LLM实例
llm = LlamaCpp(
model_path="models/llama-2-7b.gguf",
temperature=0.7, # 控制创造性
max_tokens=1000, # 最大输出长度
n_ctx=2048, # 上下文大小
verbose=True # 显示加载进度
)
# 测试简单对话
response = llm("你好,请用Python写一个快速排序算法")
print(response)
创建对话链
# 构建更复杂的对话模式
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 创建带记忆的对话链
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True # 显示中间过程
)
# 进行对话
response = conversation.predict(input="我想学习机器学习,有什么建议?")
print(response)
# 继续对话,模型会记住上下文
follow_up = conversation.predict(input="有哪些适合初学者的项目?")
print(follow_up)
向量存储设置
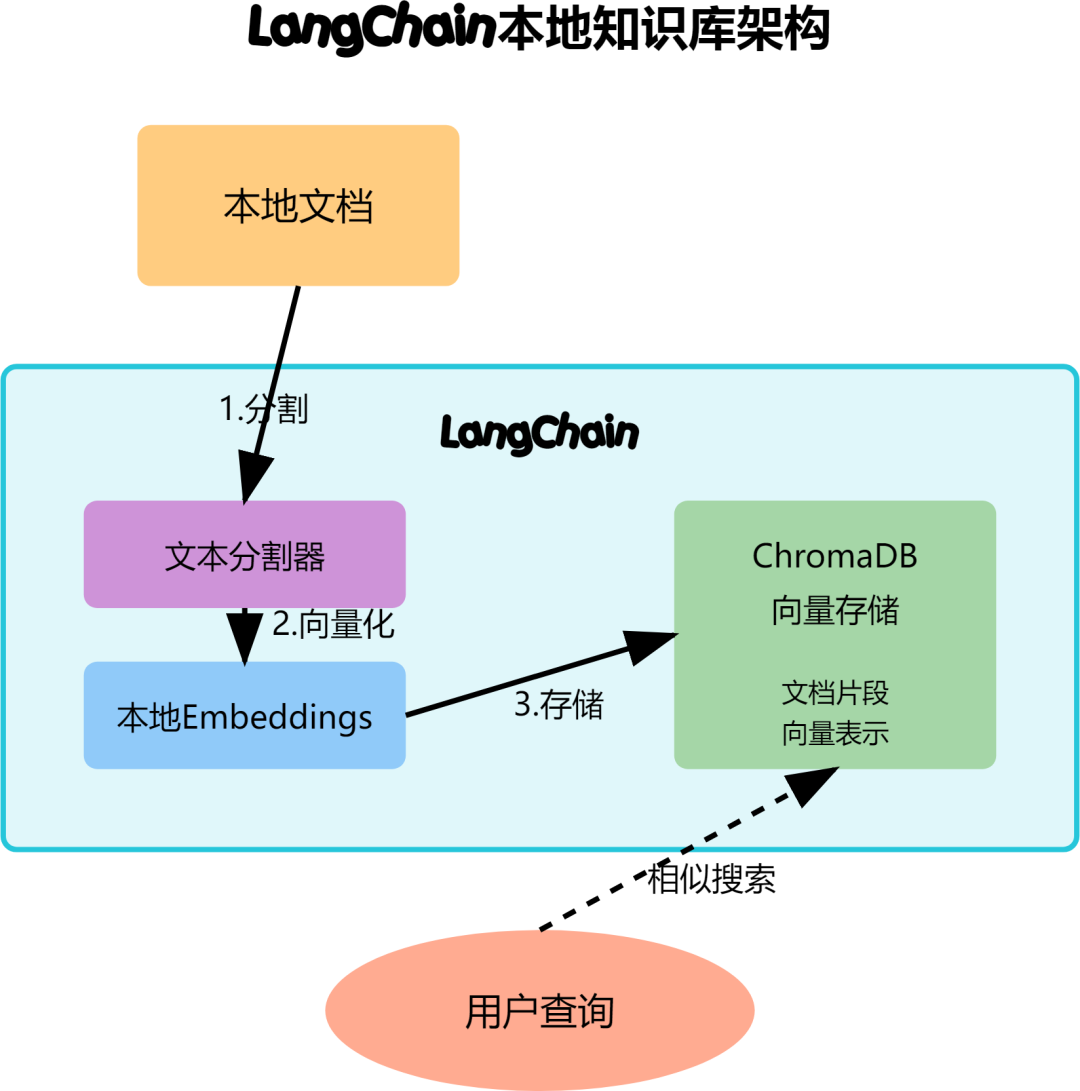
文档处理
# 加载和处理本地文档
from langchain.document_loaders import TextLoader, DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载单个文档
loader = TextLoader("./documents/machine_learning.txt")
document = loader.load()
# 加载整个目录
# dir_loader = DirectoryLoader("./documents/", glob="**/*.txt")
# documents = dir_loader.load()
# 文本分割,生成更小的文档块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块大小
chunk_overlap=200, # 重叠部分,保证上下文连贯
length_function=len # 计算长度的函数
)
docs = text_splitter.split_documents(document)
向量存储
# 设置Embeddings和向量存储
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
# 使用开源embeddings模型
embeddings = HuggingFaceEmbeddings(
model_name="all-MiniLM-L6-v2", # 小型但有效的模型
cache_folder="./models/" # 本地缓存
)
# 创建向量数据库
db = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化存储
)
# 保存向量数据库到磁盘
db.persist()
# 相似性搜索
query = "机器学习中的过拟合是什么?"
results = db.similarity_search(query, k=3) # 返回最相似的3个文档
RAG实现
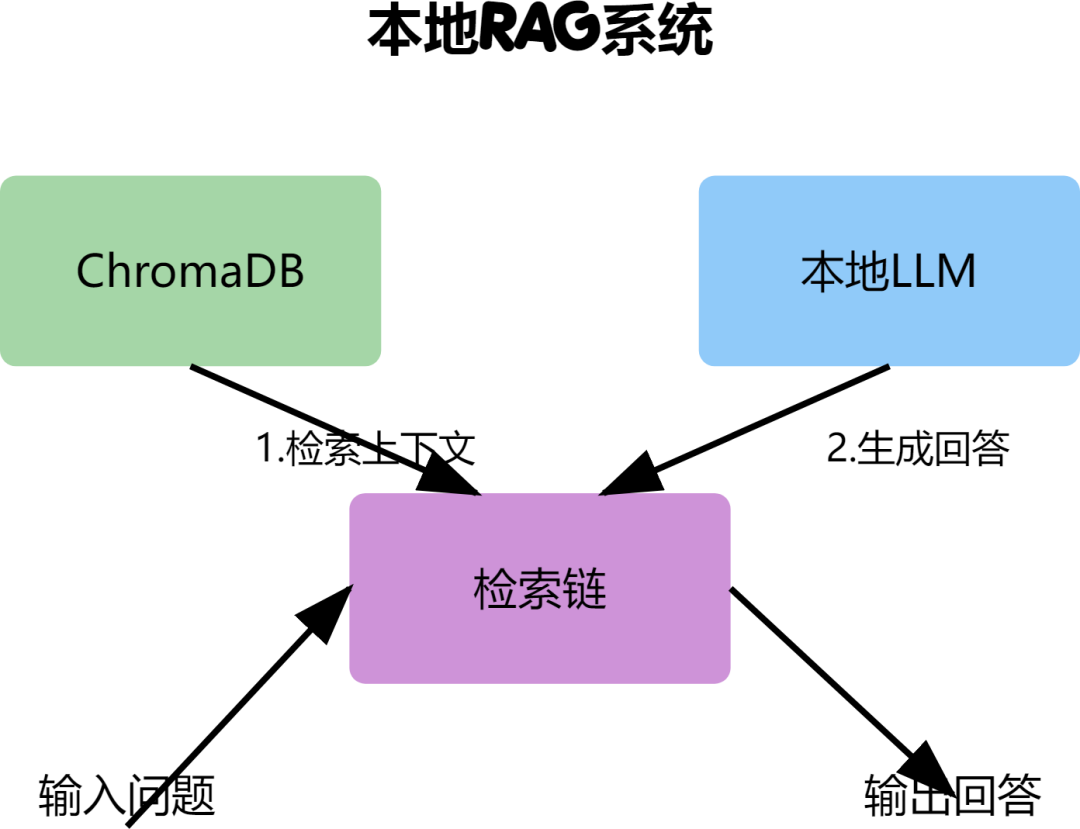
检索问答链
# 完整的RAG实现
from langchain.chains import RetrievalQA
# 创建检索问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # stuff方法:将所有文档合并为单个上下文
retriever=db.as_retriever(
search_kwargs={"k": 3} # 检索3个最相关的文档
),
verbose=True
)
# 处理问题
query = "如何解决机器学习中的过拟合问题?"
response = qa_chain.run(query)
print(response)
会话式RAG
# 带记忆的对话式RAG
from langchain.chains import ConversationalRetrievalChain
# 创建会话记忆
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 创建对话式检索链
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(),
memory=memory,
verbose=True
)
# 第一个问题
response = conversation_chain({"question": "什么是深度学习?"})
print(response['answer'])
# 后续问题(模型会记住上下文)
follow_up = conversation_chain({"question": "它与传统机器学习有什么区别?"})
print(follow_up['answer'])
应用部署
简易Web界面
# 使用Gradio创建简单界面
import gradio as gr
def process_query(query, chat_history):
# 处理用户输入并获取回答
response = conversation_chain({"question": query})
answer = response['answer']
# 更新对话历史
chat_history.append((query, answer))
return "", chat_history
# 创建Gradio界面
with gr.Blocks() as demo:
gr.Markdown("# 本地LLM知识库问答系统")
chatbot = gr.Chatbot()
msg = gr.Textbox(label="输入问题")
clear = gr.Button("清除对话")
msg.submit(process_query, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
# 启动本地服务
demo.launch(share=False) # 设置share=True可以获得公开链接
进程管理
# 持久化服务
import subprocess
import atexit
def start_server():
# 启动独立进程
server = subprocess.Popen(
["python", "app.py"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
# 程序退出时关闭服务器
def cleanup():
server.terminate()
atexit.register(cleanup)
return server
if __name__ == "__main__":
server = start_server()
print("服务已启动,访问 http://127.0.0.1:7860")
注意事项
- 本地模型对硬件有要求,至少8GB内存。小点儿的也行,但可能卡成PPT
- 第一次加载模型慢,别急,没死机。反正你熬夜调试都习惯了
- 持久化存储向量数据库,省得每次重启都重新计算。谁愿意白等呢
- 大文件分批处理,别一次性全塞进去,内存会哭
- 模型体积越大越吃资源,但效果确实好。取舍看你自己,又不是没法妥协
总结
LangChain本地部署是摆脱API依赖的强力工具,可以帮你:
- 无需网络连接运行
- 保护数据隐私安全
- 免费无限制使用
- 自定义系统行为
掌握这些技巧,你就能构建完全由自己控制的AI应用!连熬夜调试都值得,因为这是真正属于你的AI。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









