







 本文探讨了CART决策树在分类和回归任务中的应用。通过鸢尾花数据集展示了决策树的训练和可视化过程。内容包括估算类别概率、CART训练算法、基尼不纯度与信息熵的比较,以及正则化超参数的作用。在回归问题中,CART通过最小化MSE来构建树。
本文探讨了CART决策树在分类和回归任务中的应用。通过鸢尾花数据集展示了决策树的训练和可视化过程。内容包括估算类别概率、CART训练算法、基尼不纯度与信息熵的比较,以及正则化超参数的作用。在回归问题中,CART通过最小化MSE来构建树。
决策树可以实现分类或者回归,也是随机森林的基本预测器。
决策树训练和可视化
在鸢尾花数据集上训练一个决策树:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris=load_iris()
x=iris.data[:,2:]
y=iris.target
tree_clf=DecisionTreeClassifier(max_depth=2)
tree_clf.fit(x,y)
特征值选择的是鸢尾花第2列及后面所有列(花瓣长度和宽度)。
可视化:使用export_graphviz库
#可视化决策树
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=image_path('iris_tree.dot'),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
定义image_path方法:
from __future__ import division, print_function, unicode_literals
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
# %matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
# Where to save the figures
PROJECT_ROOT_DIR = "."
def image_path(fig_id):
return os.path.join(PROJECT_ROOT_DIR, "images", fig_id)
def save_fig(fig_id, tight_layout=True):
print("Saving figure", fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(image_path(fig_id) + ".png", format='png', dpi=300)
运行以上代码,会在“…\images”文件夹下产生iris_tree.dot文件,打开命令行模式并且工作目录移动到此文件夹下,输入:
dot -Tpng iris_tree.dot -o iris_tree.png
将iris_tree.dot转换为:iris_tree.png
打开iris_tree.png文件:

注:决策树不需要特征缩放或集中(归一化)。
基尼不存度:如果所有实例都是同一个类型的,则是纯的,用来衡量当前数据集的混乱度,类似于信息熵。
G
i
=
1
−
∑
k
=
1
n
p
i
,
k
2
G_i=1-\sum_{k=1}^{n}p_{i,k}^2
Gi=1−k=1∑npi,k2
估算类别概率
决策树可以估算某个实例属于特定类别 k k k的概率:首先,跟随决策树找到该实例的叶节点,然后返回该叶节中点类别 k k k的训练实例占比。也就是说,特定叶节点上,所有实例属于类别 k k k的概率都相同。
CART训练算法:生成决策树的过程中如何选择特征及阈值?产生出最纯子集的特征和阈值就是经算法搜索确定的特征和阈值
cart分类成本函数:
J
(
k
,
t
k
)
=
m
l
e
f
t
m
G
l
e
f
t
+
m
r
i
g
h
t
m
G
r
i
g
h
t
J(k,t_k)=\frac{m_{left}}{m}G_{left}+\frac{m_{right}}{m}G_{right}
J(k,tk)=mmleftGleft+mmrightGright
其中,
G
l
e
f
t
G_{left}
Gleft是左子集的不纯度,
m
l
e
f
t
m_{left}
mleft是左子集的实例数量。
CART是贪婪算法,每次执行都会选择当前最好的特征和阈值,不一定能得到全局最优值。
基尼不纯度还是信息熵
都可以衡量信息的不纯度。
不同:基尼不纯度倾向于从树枝中分裂出最常见的类别,而信息熵则倾向于生产更平衡的树。
正则化超参数
防止过拟合。在训练过程中降低决策树的自由度。
min_samples_split(节点在被分裂之前必须具有的最小样本数),min_samples_leaf(叶节点必须具有的最小样本数),min_weight_fraction_leaf(和min_samples_leaf相同,但表示为加权总数的一小部分实例),max_leaf_nodes(叶节点的最大数量)和max_features(在每个节点被评估是否分裂的时候,具有的最大特征数量)。增加超参数min_* 或者减少max_* 会使模型正则化。
回归
使用含有高斯噪声的二次函数训练一个回归树:
from sklearn.tree import DecisionTreeRegressor
tree_reg=DecisionTreeRegressor(max_depth=2)
import numpy as np
i=2*np.random.rand(100,1)
j=4+3*i+np.random.randn(100,1)
tree_reg.fit(i,j)
export_graphviz(
tree_reg,
out_file=image_path('Tree_reg.dot'),
feature_names='i',
class_names='j',
rounded=True,
filled=True
)
可视化决策树:
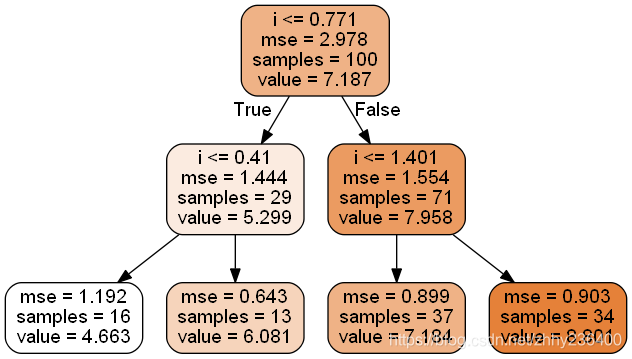
这里仍然使用了CART算法,不同的是,它分裂训练集的方式不是最小化不纯度,而是最小化MSE。
CART回归成本函数:
J
(
k
,
t
k
)
=
m
l
e
f
t
m
M
S
E
l
e
f
t
+
m
r
i
g
h
t
m
M
S
E
r
i
g
h
t
J(k,t_k)=\frac{m_{left}}{m}MSE_{left}+\frac{m_{right}}{m}MSE_{right}
J(k,tk)=mmleftMSEleft+mmrightMSEright

















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









