




近来大模型开源,并且提供各种蒸馏模型让普通用户也能在本地使用各种AI进行自嗨,由于很多有兴趣的用户不一定能通过自己调用相关的API这种方式进行使用,因此推荐目前比较热门的Ollama Desktop工具在本地进行各种大模型“尝鲜”。
本教程只针对新手和想要便捷使用但是又不知道如何完整配置的用户。
1.Ollama 安装
2.各种大模型安装
3.Ollama Desktop工具编译
4.Ollama Desktop配置
1.Ollama 安装
1.1下载安装
访问Ollama网站:Ollama 下载安装Ollama工具
进行工具下载
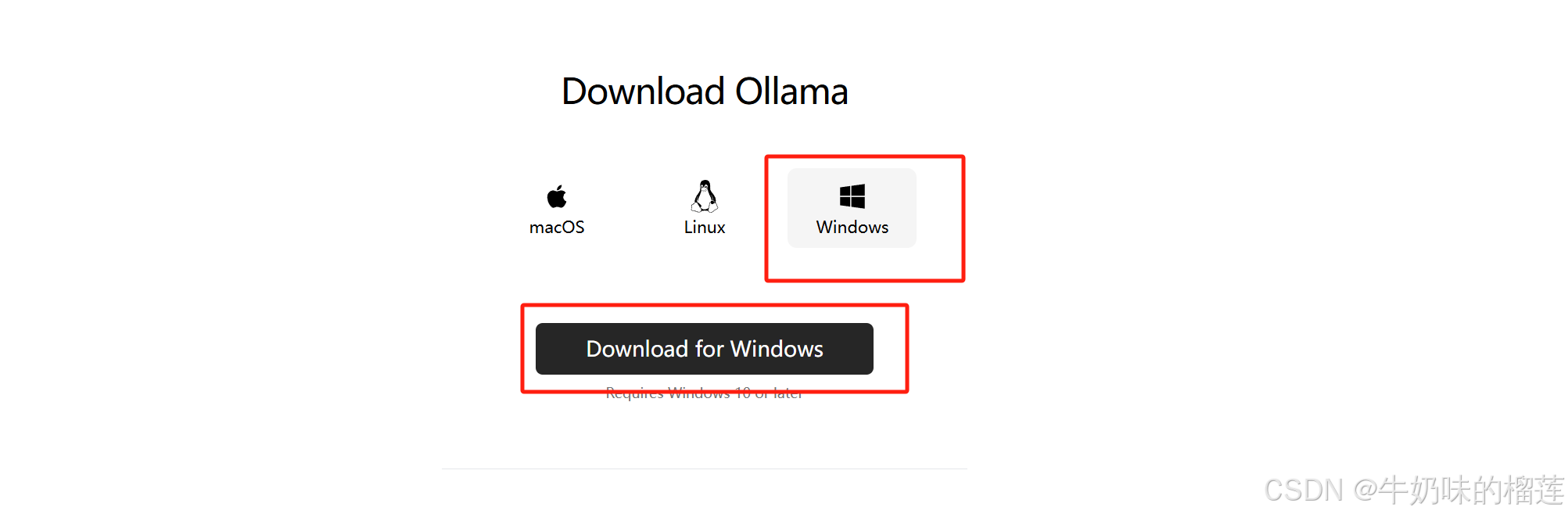
工具会默认安装到C:\Users\Administrator\AppData\Local\Programs\Ollama\
1.2环境变量配置
安装完成后进行环境变量配置,三个环境变量如下图所示:
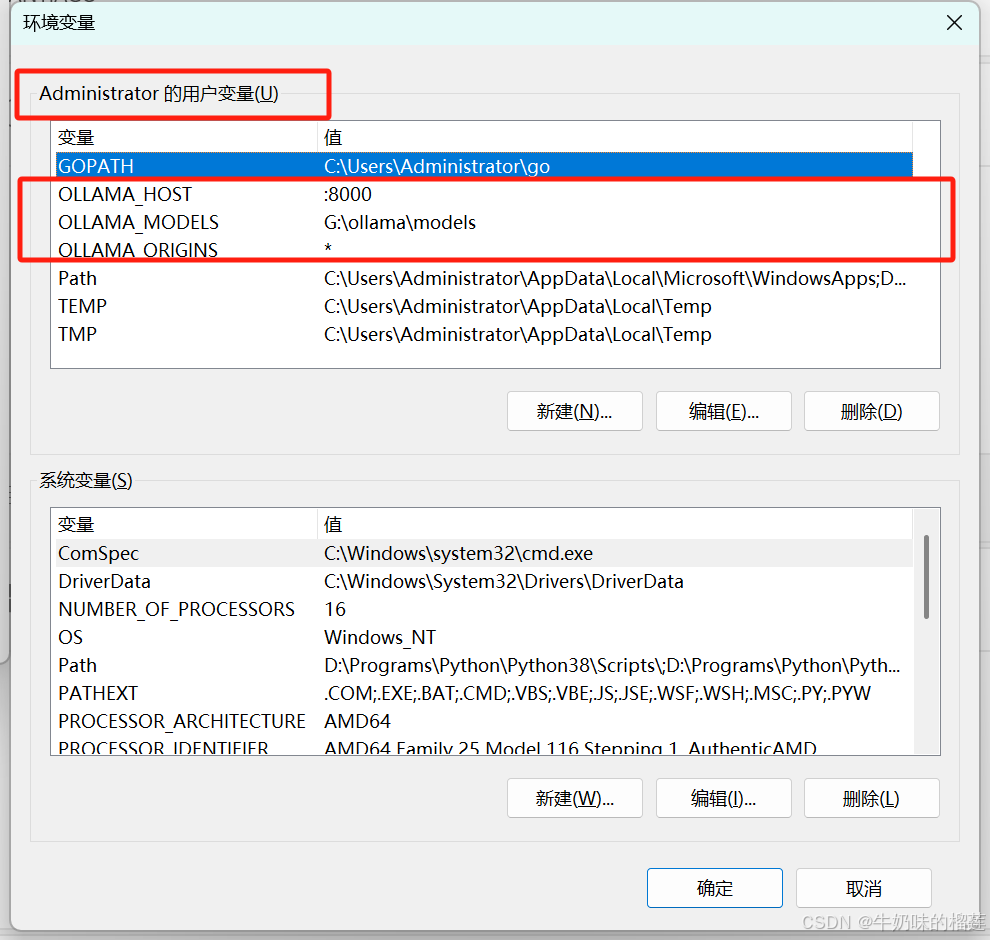
1.2.1环境变量说明
1.2.1.1模型存储目录
Ollama 的默认模型存储路径如下:
C:\Users\%username%\.ollama\\models
由于大部分用户C盘空间不富裕,建议通过环境变量配置到其他大空间目录:
变量名:
OLLAMA_MODELS变量值:G
:\ollama\models (请根据自身硬盘分区空间调整)
1.2.1.2 Ollama API访问地址和端口配置
Ollama 默认的API访问地址和端口为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









